| Microexon ID | Ps_NC_039359.1:107733748-107733762:+ |
| Species | Papaver somniferum | Coordinates | NC_039359.1:107733748..107733762 |
| Microexon Cluster ID | MEP44 |
| Size | 15 |
| Phase | 1 |
| Pfam Domain Motif | Unknown |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 46,15,47 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | RTTTATGRGCTTTGTGATRTTGACTTGAAAGATTTYAGYMTBCAAGCWTWTGGRCARCAAGGBTGTYTACTTCGRAGCTTRCCTRCAGATRTKGTRTTTGACAAYWCW |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 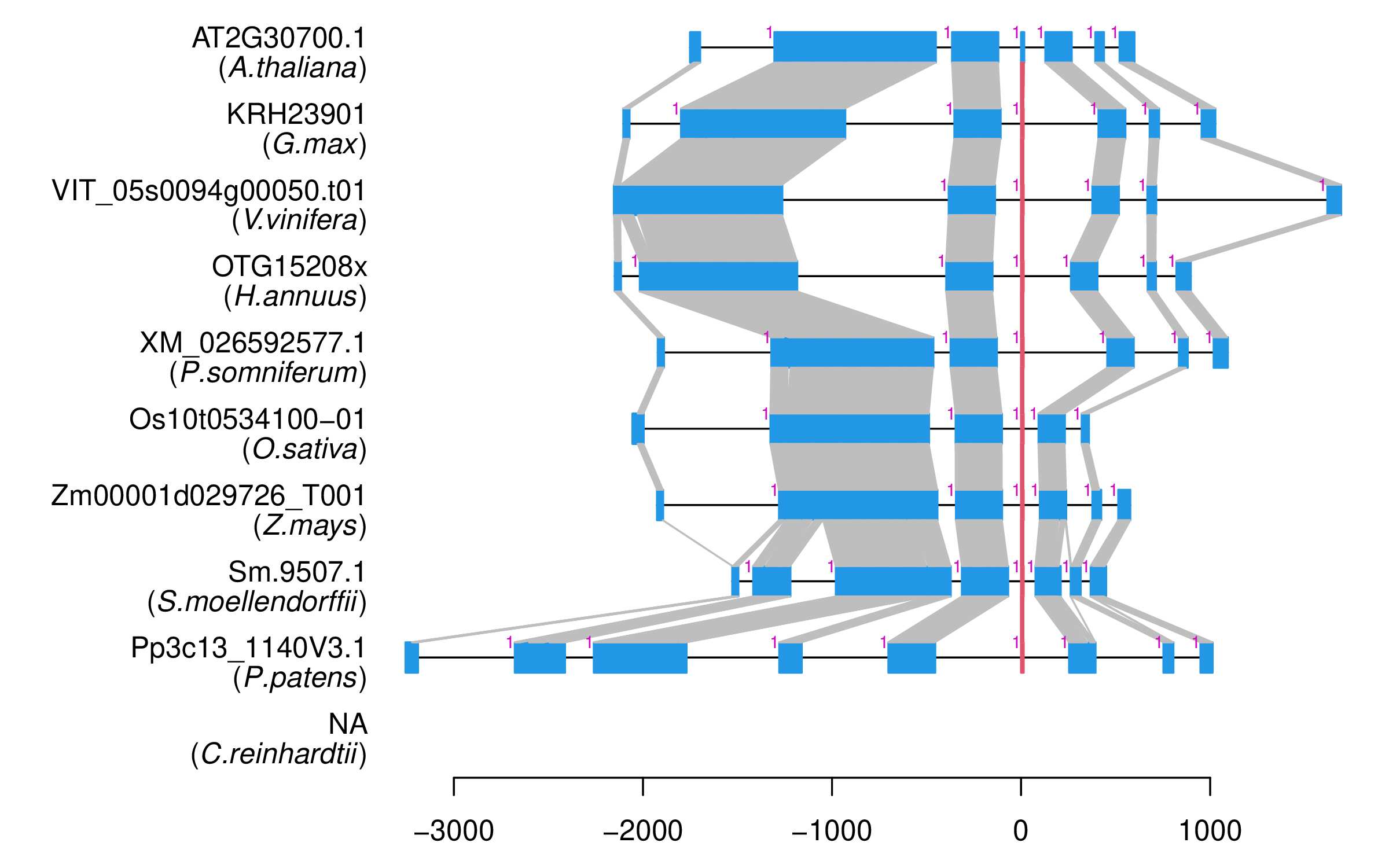 |
| Microexon DNA seq | CTTATGGACAAGAAG |
| Microexon Amino Acid seq | AYGQEG |
| Microexon-tag DNA Seq | ATCTATGAGCTTTGTGATGTGGACTTAAAAGACTTCAGTCTTCAGGCTTATGGACAAGAAGGTTGTCTGCTTCGAAGTTTGCCTGCAGATGCTGTATTTGACAATTCG |
| Microexon-tag Amino Acid Seq | IYELCDVDLKDFSLQAYGQEGCLLRSLPADAVFDNS |
| Microexon-tag spanning region | 107733575-107734250 |
| Microexon-tag prediction score | 0.9665 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026592577.1x |
| Reference Transcript ID | XM_026592577.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026592577.1 |
| Protein ID | XP_026448362.1 |
| Gene ID | LOC113348727 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026448362.1 MEYFRVYIRFKGYSCNMFLIFVIWLSSFENVTALQTSLKATLEISSANSIPDPPSSGVFEPIEISPAVIPRYPFPGESLP PMYPSFPTTYEPVLTGKCPVKFSAISDVMDKTASDCSAPLASVVGNVICCPQVNSLLHIFQGHYNSDSDQLVLQKAVADE CFSDIISILSSRGANKTIPALCSVKSSNLTGGSCPVKDTVTLEKMINTSKLLDACSSVDPLKECCRPVCQPAIVEAAVQI SSTVSANLVNANIAGDPAGLDVLGDCKGVVSSWLSRKLSVDDANTAFRILSACKVNKACPLDFKQPSAVISACRDLAGPN PSCCSSLNTYIAGIQKQMLITNRQAIHCAASFGAMLQKGGVMTNIYELCDVDLKDFSLQAYGQEGCLLRSLPADAVFDNS SGFSFTCDLSDNIAAPWPSSSSISSLSLCAPEMSLPALPSLHKSGNAGYHIGERIRKLVPVFSVLVLFSSVV* |
| CDS seq | >XM_026592577.1 ATGGAGTATTTCCGGGTCTACATTCGTTTTAAAGGTTATTCGTGCAACATGTTCTTAATCTTTGTAATTTGGTTATCTAG TTTTGAGAATGTAACAGCACTCCAAACTTCACTTAAAGCCACTTTGGAAATTTCTTCTGCAAATAGTATTCCTGACCCTC CCAGCAGCGGAGTCTTTGAACCCATAGAAATATCACCAGCAGTAATTCCACGTTATCCATTCCCTGGAGAATCTTTGCCA CCTATGTACCCTTCCTTTCCAACAACATATGAACCAGTCTTAACTGGGAAATGCCCTGTAAAATTTTCCGCCATTTCAGA TGTCATGGACAAAACTGCATCTGATTGTTCGGCACCCTTGGCATCAGTGGTGGGGAATGTGATATGTTGTCCCCAGGTTA ATAGTTTACTCCATATCTTCCAAGGACACTATAACAGTGACTCTGATCAGCTAGTCCTGCAAAAAGCAGTGGCCGATGAA TGTTTTTCAGATATTATTAGTATATTATCTAGCAGAGGAGCGAACAAGACGATTCCTGCACTTTGTTCAGTAAAATCTTC AAACCTTACAGGGGGATCTTGTCCTGTGAAAGACACGGTCACCTTAGAGAAAATGATTAATACAAGTAAGTTACTGGATG CCTGCAGCTCTGTTGATCCTCTTAAAGAGTGCTGCAGACCTGTATGCCAACCTGCTATTGTGGAGGCTGCAGTTCAAATC TCTTCAACGGTGTCAGCCAACCTTGTTAATGCAAACATAGCTGGGGATCCTGCTGGATTAGATGTTCTTGGTGATTGTAA AGGGGTAGTTTCTTCGTGGCTTTCCAGAAAACTCTCAGTAGATGATGCCAACACTGCATTTAGGATACTCTCTGCATGCA AGGTTAACAAAGCTTGTCCTTTGGATTTCAAGCAACCATCAGCTGTAATCTCAGCATGCCGTGACTTGGCTGGTCCGAAT CCTTCCTGTTGCAGCTCATTGAATACTTACATTGCTGGGATACAAAAGCAGATGCTAATTACAAATAGACAAGCCATACA TTGTGCAGCATCGTTTGGGGCCATGTTACAGAAAGGTGGTGTCATGACAAATATCTATGAGCTTTGTGATGTGGACTTAA AAGACTTCAGTCTTCAGGCTTATGGACAAGAAGGTTGTCTGCTTCGAAGTTTGCCTGCAGATGCTGTATTTGACAATTCG TCCGGCTTCAGTTTCACATGTGATTTGAGTGATAATATTGCTGCACCATGGCCTTCATCCTCCTCAATTTCATCACTGTC CCTGTGCGCCCCAGAGATGTCATTGCCTGCTCTTCCATCACTGCACAAATCAGGAAATGCTGGCTACCATATCGGCGAAA GAATCAGGAAACTTGTACCAGTTTTTTCTGTTTTAGTTCTATTTAGTAGTGTAGTGTAG |
| Microexon DNA seq | CTTATGGACAAGAAG |
| Microexon Amino Acid seq | AYGQEG |
| Microexon-tag DNA Seq | ATCTATGAGCTTTGTGATGTGGACTTAAAAGACTTCAGTCTTCAGGCTTATGGACAAGAAGGTTGTCTGCTTCGAAGTTTGCCTGCAGATGCTGTATTTGACAATTCG |
| Microexon-tag Amino Acid seq | IYELCDVDLKDFSLQAYGQEGCLLRSLPADAVFDNS |
| Transcript ID | XM_026592577.1 |
| Gene ID | Ps.11882 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026592577.1 MEYFRVYIRFKGYSCNMFLIFVIWLSSFENVTALQTSLKATLEISSANSIPDPPSSGVFEPIEISPAVIPRYPFPGESLP PMYPSFPTTYEPVLTGKCPVKFSAISDVMDKTASDCSAPLASVVGNVICCPQVNSLLHIFQGHYNSDSDQLVLQKAVADE CFSDIISILSSRGANKTIPALCSVKSSNLTGGSCPVKDTVTLEKMINTSKLLDACSSVDPLKECCRPVCQPAIVEAAVQI SSTVSANLVNANIAGDPAGLDVLGDCKGVVSSWLSRKLSVDDANTAFRILSACKVNKACPLDFKQPSAVISACRDLAGPN PSCCSSLNTYIAGIQKQMLITNRQAIHCAASFGAMLQKGGVMTNIYELCDVDLKDFSLQAYGQEGCLLRSLPADAVFDNS SGFSFTCDLSDNIAAPWPSSSSISSLSLCAPEMSLPALPSLHKSGNAGYHIGERIRKLVPVFSVLVLFSSVV* |
| CDS seq | >XM_026592577.1 ATGGAGTATTTCCGGGTCTACATTCGTTTTAAAGGTTATTCGTGCAACATGTTCTTAATCTTTGTAATTTGGTTATCTAG TTTTGAGAATGTAACAGCACTCCAAACTTCACTTAAAGCCACTTTGGAAATTTCTTCTGCAAATAGTATTCCTGACCCTC CCAGCAGCGGAGTCTTTGAACCCATAGAAATATCACCAGCAGTAATTCCACGTTATCCATTCCCTGGAGAATCTTTGCCA CCTATGTACCCTTCCTTTCCAACAACATATGAACCAGTCTTAACTGGGAAATGCCCTGTAAAATTTTCCGCCATTTCAGA TGTCATGGACAAAACTGCATCTGATTGTTCGGCACCCTTGGCATCAGTGGTGGGGAATGTGATATGTTGTCCCCAGGTTA ATAGTTTACTCCATATCTTCCAAGGACACTATAACAGTGACTCTGATCAGCTAGTCCTGCAAAAAGCAGTGGCCGATGAA TGTTTTTCAGATATTATTAGTATATTATCTAGCAGAGGAGCGAACAAGACGATTCCTGCACTTTGTTCAGTAAAATCTTC AAACCTTACAGGGGGATCTTGTCCTGTGAAAGACACGGTCACCTTAGAGAAAATGATTAATACAAGTAAGTTACTGGATG CCTGCAGCTCTGTTGATCCTCTTAAAGAGTGCTGCAGACCTGTATGCCAACCTGCTATTGTGGAGGCTGCAGTTCAAATC TCTTCAACGGTGTCAGCCAACCTTGTTAATGCAAACATAGCTGGGGATCCTGCTGGATTAGATGTTCTTGGTGATTGTAA AGGGGTAGTTTCTTCGTGGCTTTCCAGAAAACTCTCAGTAGATGATGCCAACACTGCATTTAGGATACTCTCTGCATGCA AGGTTAACAAAGCTTGTCCTTTGGATTTCAAGCAACCATCAGCTGTAATCTCAGCATGCCGTGACTTGGCTGGTCCGAAT CCTTCCTGTTGCAGCTCATTGAATACTTACATTGCTGGGATACAAAAGCAGATGCTAATTACAAATAGACAAGCCATACA TTGTGCAGCATCGTTTGGGGCCATGTTACAGAAAGGTGGTGTCATGACAAATATCTATGAGCTTTGTGATGTGGACTTAA AAGACTTCAGTCTTCAGGCTTATGGACAAGAAGGTTGTCTGCTTCGAAGTTTGCCTGCAGATGCTGTATTTGACAATTCG TCCGGCTTCAGTTTCACATGTGATTTGAGTGATAATATTGCTGCACCATGGCCTTCATCCTCCTCAATTTCATCACTGTC CCTGTGCGCCCCAGAGATGTCATTGCCTGCTCTTCCATCACTGCACAAATCAGGAAATGCTGGCTACCATATCGGCGAAA GAATCAGGAAACTTGTACCAGTTTTTTCTGTTTTAGTTCTATTTAGTAGTGTAGTGTAG |