| Microexon ID | Gm_9:45179994-45180008:+ |
| Species | Glycine max | Coordinates | 9:45179994..45180008 |
| Microexon Cluster ID | MEP44 |
| Size | 15 |
| Phase | 1 |
| Pfam Domain Motif | Unknown |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 46,15,47 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | RTTTATGRGCTTTGTGATRTTGACTTGAAAGATTTYAGYMTBCAAGCWTWTGGRCARCAAGGBTGTYTACTTCGRAGCTTRCCTRCAGATRTKGTRTTTGACAAYWCW |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 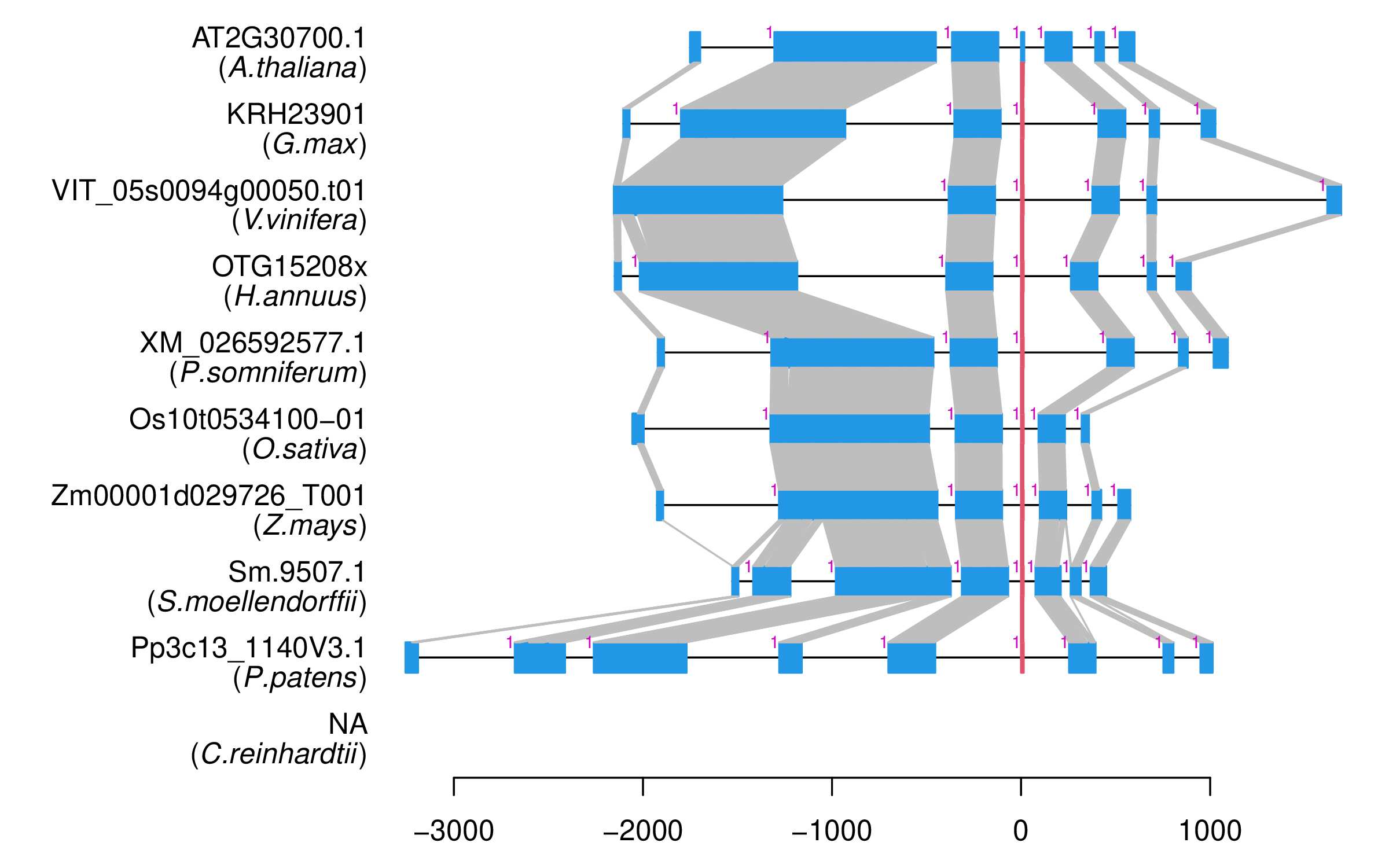 |
| Microexon DNA seq | CTTATGGACAACAAG |
| Microexon Amino Acid seq | AYGQQG |
| Microexon-tag DNA Seq | ATTTATGAGCTTTGTGACGTTGATTTGAAAGATTTCAGCATACAAGCTTATGGACAACAAGGCTGTTTACTTCGAAGCTTGCCTGGAGATGTGATATTTGACAATTCA |
| Microexon-tag Amino Acid Seq | IYELCDVDLKDFSIQAYGQQGCLLRSLPGDVIFDNS |
| Microexon-tag spanning region | 45179841-45180459 |
| Microexon-tag prediction score | 0.9769 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | KRH39908x |
| Reference Transcript ID | KRH39908 |
| Gene ID | GLYMA_09G227300 |
| Gene Name | NA |
| Transcript ID | KRH39908 |
| Protein ID | KRH39908 |
| Gene ID | GLYMA_09G227300 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >KRH39908 MGFSQDANFYRGSLCCQLILFFIWLPTFQYVTAREIHADHRRISTLVELAKEPASGESGLFDPIEISPAVLPKFPYPTES LPPMYPTFPTRYEPVLTGKCPVNFSHSGISSILDKTASDCSGPLAALVGNVICCPQLSSLIHIFQGYFSMKSDHLVLPNA VADHCFSDIISILASRGANSTIPRLCSIKSSNFTGGSCPVKDDSTFEKTVNSSKLLEACSTVDPLKECCRPVCQPAIMDA ALQISGRQMMINNNENMAGEVNHTDYLNDCKSVVYSYLSKKLSFEAANTAFRILSACKVNKVCPLTFKEPTEVINACWNV AAPSPSCCSSLNTYITGIQKQMLITNKQAIICATLFGSMLRGGGVMTNIYELCDVDLKDFSIQAYGQQGCLLRSLPGDVI FDNSSGFSFTCDLSDNIAAPWPSSSSSFASMSLCAPEMSLPALPTSSQTLKNNGCNSGGVGLLLLIFSFFIFSTLLY* |
| CDS seq | >KRH39908 ATGGGCTTCTCTCAGGATGCTAATTTTTATAGGGGTTCCTTGTGCTGTCAGCTAATTCTATTTTTCATCTGGCTTCCTAC TTTCCAATATGTGACAGCACGGGAAATACATGCTGACCATAGAAGAATTTCTACTCTGGTAGAGTTAGCTAAGGAACCTG CTTCTGGAGAATCTGGGCTCTTTGACCCCATAGAAATATCACCTGCTGTATTACCAAAATTCCCATATCCCACTGAGTCT TTACCACCCATGTACCCTACCTTCCCAACCAGATATGAACCAGTTTTAACTGGAAAATGCCCTGTAAACTTTTCTCATTC AGGTATATCAAGTATCCTAGATAAAACAGCATCTGATTGCTCTGGACCTTTGGCAGCCCTTGTAGGGAATGTAATATGTT GTCCTCAGTTAAGTAGTTTGATCCACATCTTCCAGGGTTACTTCAGCATGAAATCTGATCATTTGGTTTTGCCAAATGCA GTTGCTGATCATTGTTTTTCTGATATCATTAGTATTCTAGCCAGTAGAGGGGCAAATAGTACAATCCCCAGACTTTGTTC CATAAAATCATCTAATTTTACAGGCGGGTCATGTCCTGTGAAGGACGATTCTACTTTTGAGAAAACAGTTAACTCAAGTA AGTTACTTGAGGCTTGCAGCACTGTTGATCCACTTAAAGAGTGTTGCAGGCCTGTTTGCCAACCTGCGATAATGGATGCA GCCTTACAGATTTCTGGAAGACAAATGATGATTAACAATAATGAAAATATGGCCGGGGAAGTGAATCACACTGATTATCT TAACGATTGTAAAAGTGTGGTTTATTCATATCTTTCCAAAAAACTATCATTTGAGGCCGCAAATACTGCATTCCGTATAC TATCTGCTTGCAAAGTCAACAAAGTTTGTCCTTTGACTTTTAAGGAGCCAACAGAAGTAATTAATGCATGTTGGAATGTA GCTGCCCCCAGCCCTTCCTGTTGTAGTTCATTAAACACATATATTACTGGGATACAAAAGCAAATGTTAATTACGAATAA GCAAGCTATAATATGTGCAACACTTTTTGGATCTATGTTACGTGGAGGTGGAGTGATGACAAATATTTATGAGCTTTGTG ACGTTGATTTGAAAGATTTCAGCATACAAGCTTATGGACAACAAGGCTGTTTACTTCGAAGCTTGCCTGGAGATGTGATA TTTGACAATTCATCAGGCTTTAGCTTTACATGTGATTTGAGTGATAACATTGCTGCGCCCTGGCCTTCTTCATCATCTTC ATTTGCATCTATGTCACTCTGTGCACCTGAGATGTCATTACCTGCTCTCCCAACATCTTCTCAGACACTAAAAAATAATG GTTGTAATTCTGGTGGAGTGGGATTGCTTCTGCTTATTTTTTCATTTTTCATCTTCAGTACACTGTTGTATTGA |
| Microexon DNA seq | CTTATGGACAACAAG |
| Microexon Amino Acid seq | AYGQQG |
| Microexon-tag DNA Seq | ATTTATGAGCTTTGTGACGTTGATTTGAAAGATTTCAGCATACAAGCTTATGGACAACAAGGCTGTTTACTTCGAAGCTTGCCTGGAGATGTGATATTTGACAATTCA |
| Microexon-tag Amino Acid seq | IYELCDVDLKDFSIQAYGQQGCLLRSLPGDVIFDNS |
| Transcript ID | Gm.53987.1 |
| Gene ID | Gm.53987 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >Gm.53987.1 MGFSQDANFYRGSLCCQLILFFIWLPTFQYVTAREIHADHRRISTLVELAKEPASGESGLFDPIEISPAVLPKFPYPTES LPPMYPTFPTRYEPVLTGKCPVNFSHSGISSILDKTASDCSGPLAALVGNVICCPQLSSLIHIFQGYFSMKSDHLVLPNA VADHCFSDIISILASRGANSTIPRLCSIKSSNFTGGSCPVKDDSTFEKTVNSSKLLEACSTVDPLKECCRPVCQPAIMDA ALQISGRQMMINNNENMAGEVNHTDYLNDCKSVVYSYLSKKLSFEAANTAFRILSACKVNKVCPLTFKEPTEVINACWNV AAPSPSCCSSLNTYITGIQKQMLITNKQAIICATLFGSMLRGGGVMTNIYELCDVDLKDFSIQAYGQQGCLLRSLPGDVI FDNSSGFSFTCDLSDNIAAPWPSSSSSFASMSLCAPEMSLPALPTSSQTLKNNGCNSGGVGLLLLIFSFFIFSTLLY* |
| CDS seq | >Gm.53987.1 ATGGGCTTCTCTCAGGATGCTAATTTTTATAGGGGTTCCTTGTGCTGTCAGCTAATTCTATTTTTCATCTGGCTTCCTAC TTTCCAATATGTGACAGCACGGGAAATACATGCTGACCATAGAAGAATTTCTACTCTGGTAGAGTTAGCTAAGGAACCTG CTTCTGGAGAATCTGGGCTCTTTGACCCCATAGAAATATCACCTGCTGTATTACCAAAATTCCCATATCCCACTGAGTCT TTACCACCCATGTACCCTACCTTCCCAACCAGATATGAACCAGTTTTAACTGGAAAATGCCCTGTAAACTTTTCTCATTC AGGTATATCAAGTATCCTAGATAAAACAGCATCTGATTGCTCTGGACCTTTGGCAGCCCTTGTAGGGAATGTAATATGTT GTCCTCAGTTAAGTAGTTTGATCCACATCTTCCAGGGTTACTTCAGCATGAAATCTGATCATTTGGTTTTGCCAAATGCA GTTGCTGATCATTGTTTTTCTGATATCATTAGTATTCTAGCCAGTAGAGGGGCAAATAGTACAATCCCCAGACTTTGTTC CATAAAATCATCTAATTTTACAGGCGGGTCATGTCCTGTGAAGGACGATTCTACTTTTGAGAAAACAGTTAACTCAAGTA AGTTACTTGAGGCTTGCAGCACTGTTGATCCACTTAAAGAGTGTTGCAGGCCTGTTTGCCAACCTGCGATAATGGATGCA GCCTTACAGATTTCTGGAAGACAAATGATGATTAACAATAATGAAAATATGGCCGGGGAAGTGAATCACACTGATTATCT TAACGATTGTAAAAGTGTGGTTTATTCATATCTTTCCAAAAAACTATCATTTGAGGCCGCAAATACTGCATTCCGTATAC TATCTGCTTGCAAAGTCAACAAAGTTTGTCCTTTGACTTTTAAGGAGCCAACAGAAGTAATTAATGCATGTTGGAATGTA GCTGCCCCCAGCCCTTCCTGTTGTAGTTCATTAAACACATATATTACTGGGATACAAAAGCAAATGTTAATTACGAATAA GCAAGCTATAATATGTGCAACACTTTTTGGATCTATGTTACGTGGAGGTGGAGTGATGACAAATATTTATGAGCTTTGTG ACGTTGATTTGAAAGATTTCAGCATACAAGCTTATGGACAACAAGGCTGTTTACTTCGAAGCTTGCCTGGAGATGTGATA TTTGACAATTCATCAGGCTTTAGCTTTACATGTGATTTGAGTGATAACATTGCTGCGCCCTGGCCTTCTTCATCATCTTC ATTTGCATCTATGTCACTCTGTGCACCTGAGATGTCATTACCTGCTCTCCCAACATCTTCTCAGACACTAAAAAATAATG GTTGTAATTCTGGTGGAGTGGGATTGCTTCTGCTTATTTTTTCATTTTTCATCTTCAGTACACTGTTGTATTGA |