| Microexon ID | Ps_NC_039359.1:62173815-62173829:- |
| Species | Papaver somniferum | Coordinates | NC_039359.1:62173815..62173829 |
| Microexon Cluster ID | MEP43 |
| Size | 15 |
| Phase | 0 |
| Pfam Domain Motif | Unknown |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,15,45 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GARCTTCTYAGWCTAGCWTCAACMGAARTACARMGACARTTYTWTCAGGARGCRAGGATTAAGACTGCTGTWTTCATGGGGTGYAACARWGGWGAAATTGARMTYGGT |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 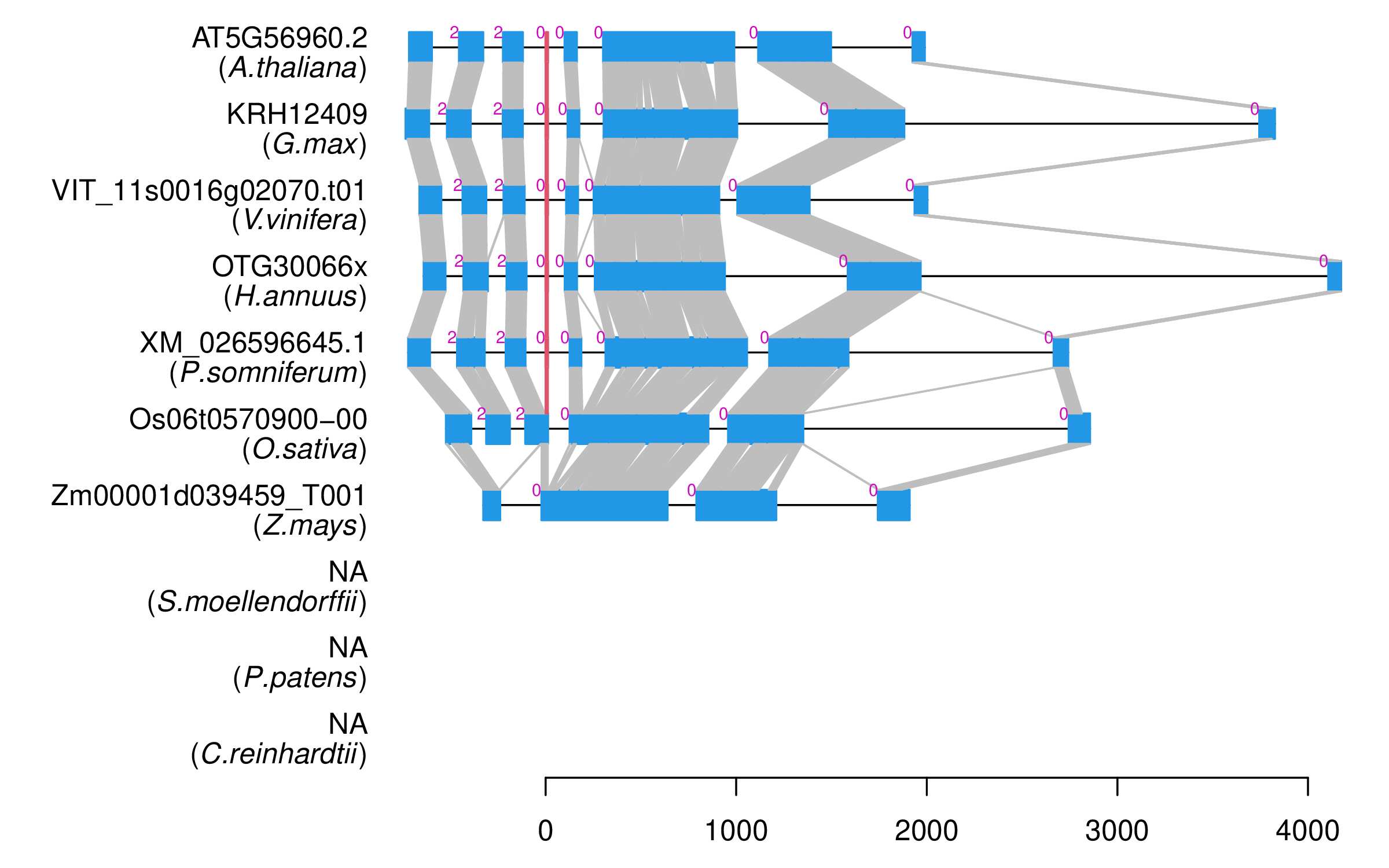 |
| Microexon DNA seq | GAAGCGCGGATTAAG |
| Microexon Amino Acid seq | EARIK |
| Microexon-tag DNA Seq | GAGCTTCTTAATCGAGCTTCAACCGACATCCAGCGACAGTTTTATCAGGAAGCGCGGATTAAGTTGGCCGCATTCGCAAGTTGCAAAAGTGGTGCAATGGAAATCGGA |
| Microexon-tag Amino Acid Seq | ELLNRASTDIQRQFYQEARIKLAAFASCKSGAMEIG |
| Microexon-tag spanning region | 62173658-62173980 |
| Microexon-tag prediction score | 0.9317 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026597013.1x |
| Reference Transcript ID | XM_026597013.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026597013.1 |
| Protein ID | XP_026452798.1 |
| Gene ID | LOC113353409 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026452798.1 MDSVFYLDEEVRTRFLQNLAQSLGCTYLCLWSYYPLPANYLFSTNGVLNYNAIVHQPASSSSASIASQAIIQTLFDAYRS TPHIIQNGLVPGLAFLEGIPYLEFKELELLNRASTDIQRQFYQEARIKLAAFASCKSGAMEIGMSSLDQSKNIEMEMMNW FPDDFILQQSKLVRNQQVQLPQRIDQSWPSSSSSSLKSLVSSPEYSPLLFSAPTAFPPQEFIKEVITSDHQTSKPNLVAA QSIDQQIEHAYNILGNVQFPNPENVDAALTKAMLAVLSSTPASSSLPHQHQHQQTQACSNHLSQEVGVFKRYKPEDNLLA LANNKLKTNYGGQNMLKRAIIFYKNMQMRKRIMEEQLAQGYRPTSSQLHHKMSERKRREKLNDSFLALKSLLPPGSKKDK VSLLSITRDYLVTLKDEIKELKRRNRFLETQLAPTKPTLITSGNDPEMGAASTSSDITVEIQLTEASEPSILSEEREVDL QVNVRSRYCDFMSLIRCLLEFLNQVDGVTLEFMEGNTTPAQVPNSSYGVVIRLKIKASQQHIFEESAFKEAIRRIIGDAA K* |
| CDS seq | >XM_026597013.1 ATGGACTCGGTCTTCTACTTAGATGAAGAAGTCCGTACTCGTTTTCTACAAAACTTGGCACAATCTCTTGGTTGCACTTA TCTTTGTTTGTGGTCTTATTATCCTCTTCCTGCAAACTATCTATTCTCAACAAATGGAGTTCTCAACTATAATGCAATAG TACATCAGCCAGCTAGTTCTTCATCAGCATCAATAGCATCTCAAGCTATAATTCAAACCCTTTTCGACGCTTACCGTAGC ACGCCCCACATCATACAAAACGGATTGGTTCCGGGGCTTGCTTTCCTAGAAGGTATACCATATTTAGAATTCAAGGAATT GGAGCTTCTTAATCGAGCTTCAACCGACATCCAGCGACAGTTTTATCAGGAAGCGCGGATTAAGTTGGCCGCATTCGCAA GTTGCAAAAGTGGTGCAATGGAAATCGGAATGTCCAGTTTAGACCAGTCGAAAAACATTGAAATGGAGATGATGAATTGG TTTCCGGATGACTTCATCCTGCAACAGTCTAAACTTGTAAGAAATCAGCAAGTACAACTTCCTCAACGAATAGATCAAAG TTGGCCTTCGTCATCGTCTTCTTCATTAAAATCACTAGTGAGCAGTCCTGAGTACTCCCCTCTTCTGTTTAGTGCACCCA CTGCTTTTCCCCCTCAAGAATTCATTAAAGAAGTAATTACATCTGATCATCAAACAAGTAAACCTAATCTAGTGGCAGCT CAATCCATCGATCAACAGATAGAGCATGCTTATAACATACTTGGGAATGTTCAATTTCCAAACCCAGAAAACGTTGATGC AGCACTGACCAAAGCCATGCTAGCCGTTTTGTCATCAACGCCAGCATCATCTTCTTTACCTCATCAACACCAACACCAAC AAACTCAAGCTTGTAGTAATCACTTAAGTCAAGAAGTGGGAGTTTTCAAAAGATATAAACCCGAAGACAATCTACTAGCA CTTGCCAATAATAAGTTGAAAACCAACTACGGAGGACAAAATATGCTTAAGCGAGCAATTATCTTTTACAAAAACATGCA AATGAGAAAAAGGATAATGGAGGAACAACTCGCACAAGGATATCGTCCAACCAGTTCACAATTGCACCATAAAATGTCAG AACGTAAACGACGAGAGAAACTTAACGATAGCTTTCTTGCGTTGAAATCACTTTTACCACCAGGTTCCAAGAAAGATAAG GTATCATTGCTGTCAATTACAAGAGATTACTTAGTTACTCTTAAAGATGAAATCAAAGAGCTGAAACGAAGAAATCGTTT CCTTGAGACACAACTTGCACCAACAAAGCCTACACTCATAACAAGCGGTAATGATCCAGAAATGGGTGCAGCTAGCACTT CTTCGGATATTACGGTTGAAATTCAGTTAACCGAAGCTTCTGAACCATCAATATTATCTGAAGAACGAGAAGTTGATTTG CAAGTTAATGTGAGATCAAGATATTGTGATTTTATGAGTCTGATTAGATGTCTGCTTGAGTTCTTAAACCAAGTTGATGG TGTAACCTTAGAGTTCATGGAAGGAAATACTACACCAGCACAAGTGCCAAATTCTTCCTATGGAGTGGTCATTAGACTGA AAATCAAGGCTAGCCAGCAGCATATATTCGAAGAGTCAGCCTTCAAAGAAGCTATTAGAAGAATTATTGGTGATGCAGCA AAGTGA |
| Microexon DNA seq | GAAGCGCGGATTAAG |
| Microexon Amino Acid seq | EARIK |
| Microexon-tag DNA Seq | GAGCTTCTTAATCGAGCTTCAACCGACATCCAGCGACAGTTTTATCAGGAAGCGCGGATTAAGTTGGCCGCATTCGCAAGTTGCAAAAGTGGTGCAATGGAAATCGGA |
| Microexon-tag Amino Acid seq | ELLNRASTDIQRQFYQEARIKLAAFASCKSGAMEIG |
| Transcript ID | XM_026597013.1 |
| Gene ID | LOC113353409 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026597013.1 MDSVFYLDEEVRTRFLQNLAQSLGCTYLCLWSYYPLPANYLFSTNGVLNYNAIVHQPASSSSASIASQAIIQTLFDAYRS TPHIIQNGLVPGLAFLEGIPYLEFKELELLNRASTDIQRQFYQEARIKLAAFASCKSGAMEIGMSSLDQSKNIEMEMMNW FPDDFILQQSKLVRNQQVQLPQRIDQSWPSSSSSSLKSLVSSPEYSPLLFSAPTAFPPQEFIKEVITSDHQTSKPNLVAA QSIDQQIEHAYNILGNVQFPNPENVDAALTKAMLAVLSSTPASSSLPHQHQHQQTQACSNHLSQEVGVFKRYKPEDNLLA LANNKLKTNYGGQNMLKRAIIFYKNMQMRKRIMEEQLAQGYRPTSSQLHHKMSERKRREKLNDSFLALKSLLPPGSKKDK VSLLSITRDYLVTLKDEIKELKRRNRFLETQLAPTKPTLITSGNDPEMGAASTSSDITVEIQLTEASEPSILSEEREVDL QVNVRSRYCDFMSLIRCLLEFLNQVDGVTLEFMEGNTTPAQVPNSSYGVVIRLKIKASQQHIFEESAFKEAIRRIIGDAA K* |
| CDS seq | >XM_026597013.1 ATGGACTCGGTCTTCTACTTAGATGAAGAAGTCCGTACTCGTTTTCTACAAAACTTGGCACAATCTCTTGGTTGCACTTA TCTTTGTTTGTGGTCTTATTATCCTCTTCCTGCAAACTATCTATTCTCAACAAATGGAGTTCTCAACTATAATGCAATAG TACATCAGCCAGCTAGTTCTTCATCAGCATCAATAGCATCTCAAGCTATAATTCAAACCCTTTTCGACGCTTACCGTAGC ACGCCCCACATCATACAAAACGGATTGGTTCCGGGGCTTGCTTTCCTAGAAGGTATACCATATTTAGAATTCAAGGAATT GGAGCTTCTTAATCGAGCTTCAACCGACATCCAGCGACAGTTTTATCAGGAAGCGCGGATTAAGTTGGCCGCATTCGCAA GTTGCAAAAGTGGTGCAATGGAAATCGGAATGTCCAGTTTAGACCAGTCGAAAAACATTGAAATGGAGATGATGAATTGG TTTCCGGATGACTTCATCCTGCAACAGTCTAAACTTGTAAGAAATCAGCAAGTACAACTTCCTCAACGAATAGATCAAAG TTGGCCTTCGTCATCGTCTTCTTCATTAAAATCACTAGTGAGCAGTCCTGAGTACTCCCCTCTTCTGTTTAGTGCACCCA CTGCTTTTCCCCCTCAAGAATTCATTAAAGAAGTAATTACATCTGATCATCAAACAAGTAAACCTAATCTAGTGGCAGCT CAATCCATCGATCAACAGATAGAGCATGCTTATAACATACTTGGGAATGTTCAATTTCCAAACCCAGAAAACGTTGATGC AGCACTGACCAAAGCCATGCTAGCCGTTTTGTCATCAACGCCAGCATCATCTTCTTTACCTCATCAACACCAACACCAAC AAACTCAAGCTTGTAGTAATCACTTAAGTCAAGAAGTGGGAGTTTTCAAAAGATATAAACCCGAAGACAATCTACTAGCA CTTGCCAATAATAAGTTGAAAACCAACTACGGAGGACAAAATATGCTTAAGCGAGCAATTATCTTTTACAAAAACATGCA AATGAGAAAAAGGATAATGGAGGAACAACTCGCACAAGGATATCGTCCAACCAGTTCACAATTGCACCATAAAATGTCAG AACGTAAACGACGAGAGAAACTTAACGATAGCTTTCTTGCGTTGAAATCACTTTTACCACCAGGTTCCAAGAAAGATAAG GTATCATTGCTGTCAATTACAAGAGATTACTTAGTTACTCTTAAAGATGAAATCAAAGAGCTGAAACGAAGAAATCGTTT CCTTGAGACACAACTTGCACCAACAAAGCCTACACTCATAACAAGCGGTAATGATCCAGAAATGGGTGCAGCTAGCACTT CTTCGGATATTACGGTTGAAATTCAGTTAACCGAAGCTTCTGAACCATCAATATTATCTGAAGAACGAGAAGTTGATTTG CAAGTTAATGTGAGATCAAGATATTGTGATTTTATGAGTCTGATTAGATGTCTGCTTGAGTTCTTAAACCAAGTTGATGG TGTAACCTTAGAGTTCATGGAAGGAAATACTACACCAGCACAAGTGCCAAATTCTTCCTATGGAGTGGTCATTAGACTGA AAATCAAGGCTAGCCAGCAGCATATATTCGAAGAGTCAGCCTTCAAAGAAGCTATTAGAAGAATTATTGGTGATGCAGCA AAGTGA |