| Microexon ID | Ps_NC_039359.1:218972900-218972914:+ |
| Species | Papaver somniferum | Coordinates | NC_039359.1:218972900..218972914 |
| Microexon Cluster ID | MEP43 |
| Size | 15 |
| Phase | 0 |
| Pfam Domain Motif | Unknown |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,15,45 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GARCTTCTYAGWCTAGCWTCAACMGAARTACARMGACARTTYTWTCAGGARGCRAGGATTAAGACTGCTGTWTTCATGGGGTGYAACARWGGWGAAATTGARMTYGGT |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 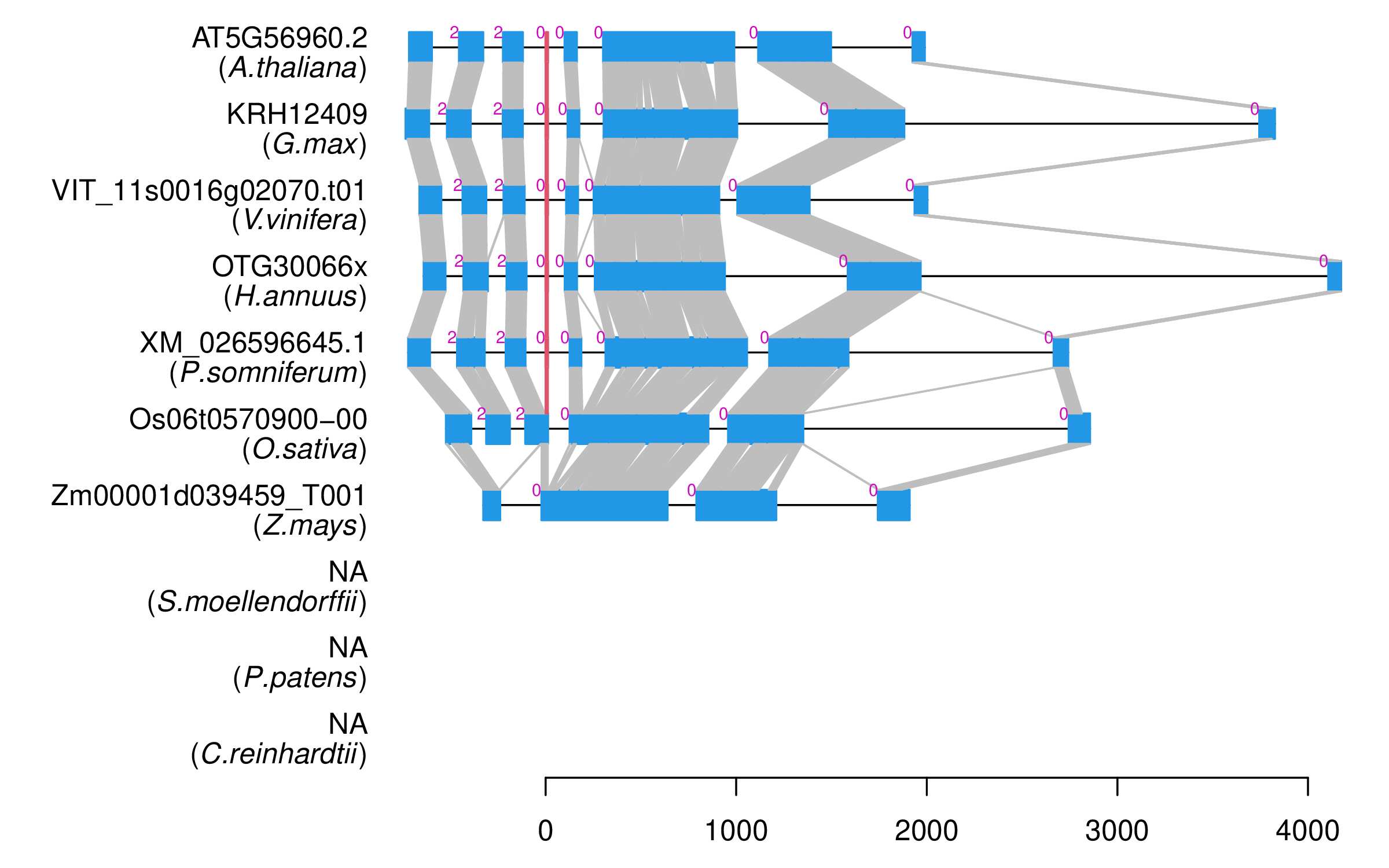 |
| Microexon DNA seq | GAAGCGCGGATTAAG |
| Microexon Amino Acid seq | EARIK |
| Microexon-tag DNA Seq | GAGCTTCTTAATCGAGCTTCAACCGACATCCAGCGACAGTTTTATCAGGAAGCGCGGATTAAGTTGGCCGCATTCGTAAGTTGCAAAAGTTGTGAAATGGAAATCGGA |
| Microexon-tag Amino Acid Seq | ELLNRASTDIQRQFYQEARIKLAAFVSCKSCEMEIG |
| Microexon-tag spanning region | 218972749-218973071 |
| Microexon-tag prediction score | 0.9332 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026596645.1x |
| Reference Transcript ID | XM_026596645.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026596645.1 |
| Protein ID | XP_026452430.1 |
| Gene ID | LOC113352888 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026452430.1 MDSVFYLDEEVRTRFLQNLAQSLGCTYLCLWSYYPLPANYLFSTNGLLNYNAIVHQPASSSSASIPSQAIIQTLFDAYRS TPHIIQNGLVPGLAFLEGIPYLEFKESELLNRASTDIQRQFYQEARIKLAAFVSCKSCEMEIGMSSLDQSKNIEMEMMNW FPDDFIPQQSKLLRNQQVQLPQRIDQSWPSSSSSSLKSLVSSPEYSPLLFSAPTAFPPQEFIKEVITSDHQTSKPNLVAA QSIDQQIEHAYNILGNVQFPNPENVDAALTKAMLAVLSSTPASSSLPHQHRHQQTQACSNHLSQEVGAFKRYKPEDNLLA LANNKLKTNYGGQNMLKRAIIFYKNMHMRKRIMEEPLAQGYRPTSSQLHHKMSERKRREKLNDSFLALKSLLPPGSKKDK VSLLSITRDYLVTLKDEIKELKRRNRFLETQLAPTELTLITSGNDPEMGAASTSSDITVEIQLTETSEPSIPSEEREVDL QVNVKSRHCDFMSLIRRLLEFLNQVDGVILEFMEGNTTPSQVPNSSYAVVFRLKIKACQQHVFEESAFKEAIRRIIGDAA K* |
| CDS seq | >XM_026596645.1 ATGGACTCGGTCTTCTACTTAGATGAAGAAGTCCGTACTCGTTTTCTACAAAACTTGGCACAATCTCTTGGTTGCACTTA TCTTTGTTTATGGTCTTATTATCCTCTTCCTGCAAACTATCTATTCTCAACAAATGGACTTCTCAACTATAATGCAATAG TACACCAGCCAGCTAGTTCTTCATCAGCATCAATACCATCTCAAGCTATAATTCAAACCCTTTTCGACGCTTACCGTAGC ACGCCGCACATCATACAAAACGGATTGGTTCCGGGGCTTGCTTTCCTAGAAGGTATACCATATTTAGAATTCAAGGAATC GGAGCTTCTTAATCGAGCTTCAACCGACATCCAGCGACAGTTTTATCAGGAAGCGCGGATTAAGTTGGCCGCATTCGTAA GTTGCAAAAGTTGTGAAATGGAAATCGGAATGTCCAGTTTAGACCAGTCGAAAAACATTGAAATGGAGATGATGAATTGG TTTCCGGATGACTTCATCCCGCAGCAGTCTAAACTTCTAAGAAATCAGCAAGTACAACTTCCTCAACGAATCGATCAAAG TTGGCCTTCGTCATCGTCTTCTTCATTAAAATCACTAGTGAGCAGTCCTGAGTACTCACCTCTTCTGTTTAGTGCACCCA CTGCTTTTCCCCCTCAAGAATTCATTAAAGAAGTCATTACATCTGATCATCAAACAAGTAAACCTAATCTGGTGGCAGCT CAATCCATCGATCAACAGATAGAGCATGCTTATAACATACTTGGAAATGTTCAATTTCCAAACCCAGAGAACGTTGATGC AGCACTGACCAAAGCCATGCTAGCCGTTTTGTCATCAACACCAGCATCATCTTCTTTACCTCATCAACACCGACACCAAC AAACTCAAGCTTGTAGTAATCACTTAAGTCAAGAAGTGGGAGCTTTCAAAAGATATAAACCCGAAGACAATCTACTGGCA CTTGCCAATAATAAGTTGAAAACCAACTACGGAGGACAAAATATGCTTAAGCGAGCAATTATCTTTTACAAAAACATGCA TATGAGAAAAAGGATAATGGAGGAACCACTCGCACAAGGATATCGTCCAACCAGTTCACAATTGCACCATAAAATGTCAG AACGTAAACGACGAGAGAAACTTAACGATAGCTTTCTCGCGTTGAAATCACTTTTACCACCAGGTTCCAAGAAAGATAAG GTATCATTGCTGTCAATTACAAGAGATTACTTAGTTACTCTTAAAGATGAAATCAAAGAGCTGAAACGAAGAAATCGTTT CCTTGAGACACAACTTGCACCAACAGAGCTTACACTCATAACAAGCGGTAATGATCCAGAAATGGGTGCAGCTAGCACTT CTTCGGATATTACGGTTGAAATTCAGTTAACCGAAACTTCTGAACCATCCATACCATCAGAAGAACGAGAAGTTGATTTG CAAGTTAATGTGAAATCAAGACATTGTGATTTTATGAGTCTGATTAGACGTTTGCTTGAGTTCTTAAACCAAGTTGATGG TGTAATCTTGGAGTTCATGGAAGGAAATACTACACCATCACAAGTGCCAAATTCTTCCTATGCAGTGGTCTTTAGACTGA AAATCAAGGCTTGCCAGCAGCATGTATTTGAAGAGTCGGCCTTCAAAGAAGCTATTAGAAGAATTATCGGTGATGCAGCA AAGTGA |
| Microexon DNA seq | GAAGCGCGGATTAAG |
| Microexon Amino Acid seq | EARIK |
| Microexon-tag DNA Seq | GAGCTTCTTAATCGAGCTTCAACCGACATCCAGCGACAGTTTTATCAGGAAGCGCGGATTAAGTTGGCCGCATTCGTAAGTTGCAAAAGTTGTGAAATGGAAATCGGA |
| Microexon-tag Amino Acid seq | ELLNRASTDIQRQFYQEARIKLAAFVSCKSCEMEIG |
| Transcript ID | XM_026596645.1 |
| Gene ID | LOC113352888 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026596645.1 MDSVFYLDEEVRTRFLQNLAQSLGCTYLCLWSYYPLPANYLFSTNGLLNYNAIVHQPASSSSASIPSQAIIQTLFDAYRS TPHIIQNGLVPGLAFLEGIPYLEFKESELLNRASTDIQRQFYQEARIKLAAFVSCKSCEMEIGMSSLDQSKNIEMEMMNW FPDDFIPQQSKLLRNQQVQLPQRIDQSWPSSSSSSLKSLVSSPEYSPLLFSAPTAFPPQEFIKEVITSDHQTSKPNLVAA QSIDQQIEHAYNILGNVQFPNPENVDAALTKAMLAVLSSTPASSSLPHQHRHQQTQACSNHLSQEVGAFKRYKPEDNLLA LANNKLKTNYGGQNMLKRAIIFYKNMHMRKRIMEEPLAQGYRPTSSQLHHKMSERKRREKLNDSFLALKSLLPPGSKKDK VSLLSITRDYLVTLKDEIKELKRRNRFLETQLAPTELTLITSGNDPEMGAASTSSDITVEIQLTETSEPSIPSEEREVDL QVNVKSRHCDFMSLIRRLLEFLNQVDGVILEFMEGNTTPSQVPNSSYAVVFRLKIKACQQHVFEESAFKEAIRRIIGDAA K* |
| CDS seq | >XM_026596645.1 ATGGACTCGGTCTTCTACTTAGATGAAGAAGTCCGTACTCGTTTTCTACAAAACTTGGCACAATCTCTTGGTTGCACTTA TCTTTGTTTATGGTCTTATTATCCTCTTCCTGCAAACTATCTATTCTCAACAAATGGACTTCTCAACTATAATGCAATAG TACACCAGCCAGCTAGTTCTTCATCAGCATCAATACCATCTCAAGCTATAATTCAAACCCTTTTCGACGCTTACCGTAGC ACGCCGCACATCATACAAAACGGATTGGTTCCGGGGCTTGCTTTCCTAGAAGGTATACCATATTTAGAATTCAAGGAATC GGAGCTTCTTAATCGAGCTTCAACCGACATCCAGCGACAGTTTTATCAGGAAGCGCGGATTAAGTTGGCCGCATTCGTAA GTTGCAAAAGTTGTGAAATGGAAATCGGAATGTCCAGTTTAGACCAGTCGAAAAACATTGAAATGGAGATGATGAATTGG TTTCCGGATGACTTCATCCCGCAGCAGTCTAAACTTCTAAGAAATCAGCAAGTACAACTTCCTCAACGAATCGATCAAAG TTGGCCTTCGTCATCGTCTTCTTCATTAAAATCACTAGTGAGCAGTCCTGAGTACTCACCTCTTCTGTTTAGTGCACCCA CTGCTTTTCCCCCTCAAGAATTCATTAAAGAAGTCATTACATCTGATCATCAAACAAGTAAACCTAATCTGGTGGCAGCT CAATCCATCGATCAACAGATAGAGCATGCTTATAACATACTTGGAAATGTTCAATTTCCAAACCCAGAGAACGTTGATGC AGCACTGACCAAAGCCATGCTAGCCGTTTTGTCATCAACACCAGCATCATCTTCTTTACCTCATCAACACCGACACCAAC AAACTCAAGCTTGTAGTAATCACTTAAGTCAAGAAGTGGGAGCTTTCAAAAGATATAAACCCGAAGACAATCTACTGGCA CTTGCCAATAATAAGTTGAAAACCAACTACGGAGGACAAAATATGCTTAAGCGAGCAATTATCTTTTACAAAAACATGCA TATGAGAAAAAGGATAATGGAGGAACCACTCGCACAAGGATATCGTCCAACCAGTTCACAATTGCACCATAAAATGTCAG AACGTAAACGACGAGAGAAACTTAACGATAGCTTTCTCGCGTTGAAATCACTTTTACCACCAGGTTCCAAGAAAGATAAG GTATCATTGCTGTCAATTACAAGAGATTACTTAGTTACTCTTAAAGATGAAATCAAAGAGCTGAAACGAAGAAATCGTTT CCTTGAGACACAACTTGCACCAACAGAGCTTACACTCATAACAAGCGGTAATGATCCAGAAATGGGTGCAGCTAGCACTT CTTCGGATATTACGGTTGAAATTCAGTTAACCGAAACTTCTGAACCATCCATACCATCAGAAGAACGAGAAGTTGATTTG CAAGTTAATGTGAAATCAAGACATTGTGATTTTATGAGTCTGATTAGACGTTTGCTTGAGTTCTTAAACCAAGTTGATGG TGTAATCTTGGAGTTCATGGAAGGAAATACTACACCATCACAAGTGCCAAATTCTTCCTATGCAGTGGTCTTTAGACTGA AAATCAAGGCTTGCCAGCAGCATGTATTTGAAGAGTCGGCCTTCAAAGAAGCTATTAGAAGAATTATCGGTGATGCAGCA AAGTGA |