| Microexon ID | Gm_9:6212909-6212923:+ |
| Species | Glycine max | Coordinates | 9:6212909..6212923 |
| Microexon Cluster ID | MEP43 |
| Size | 15 |
| Phase | 0 |
| Pfam Domain Motif | Unknown |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,15,45 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GARCTTCTYAGWCTAGCWTCAACMGAARTACARMGACARTTYTWTCAGGARGCRAGGATTAAGACTGCTGTWTTCATGGGGTGYAACARWGGWGAAATTGARMTYGGT |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 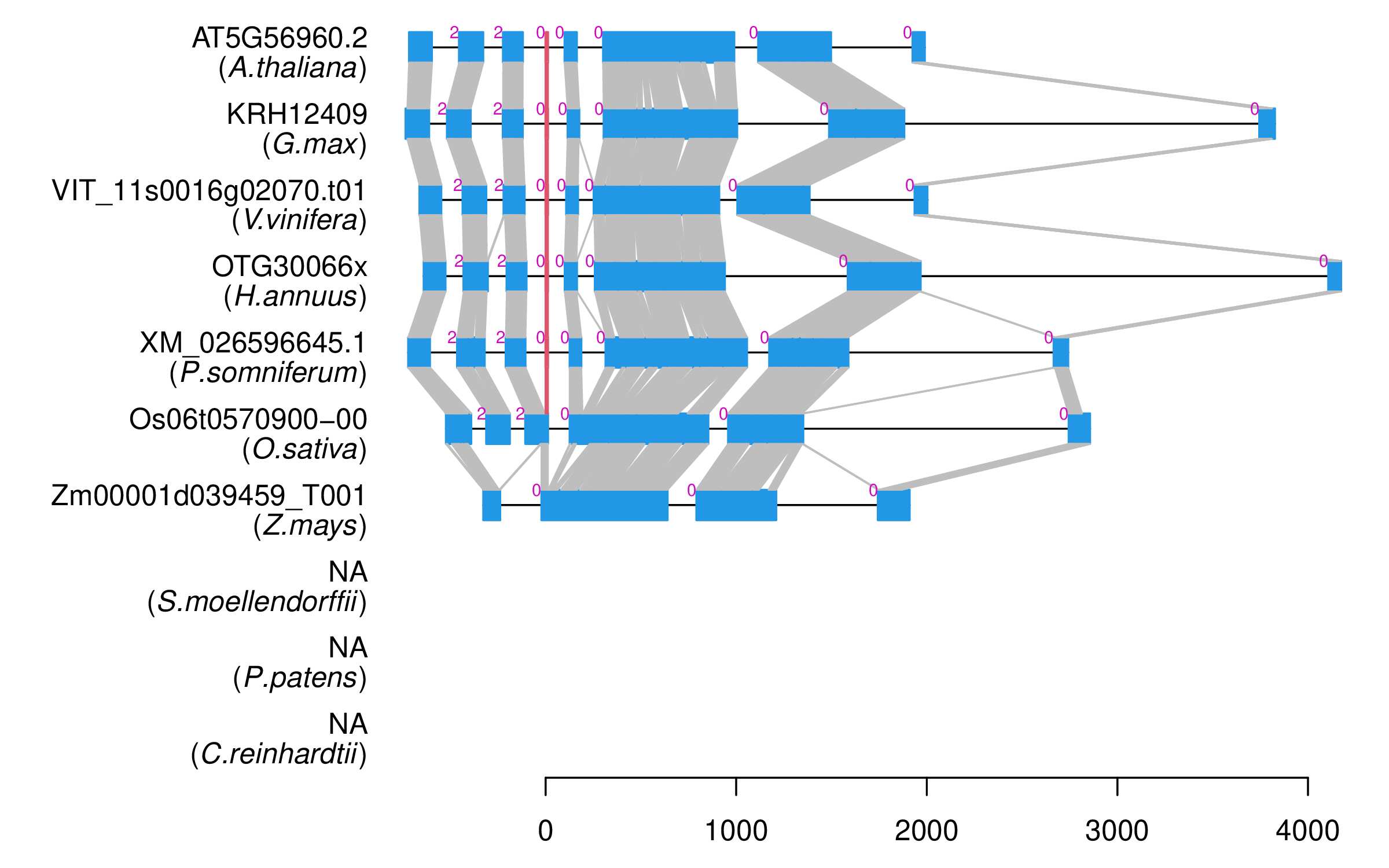 |
| Microexon DNA seq | GAGGCAAGGATTAAG |
| Microexon Amino Acid seq | EARIK |
| Microexon-tag DNA Seq | GAACTTCTCAGACTAGCATCCACAGAAATACAAACACAATTTTTTCAGGAGGCAAGGATTAAGACTGCTGTTTTCATGGGGTGTAACAAAGGAGAAATTGAGCTTGGT |
| Microexon-tag Amino Acid Seq | ELLRLASTEIQTQFFQEARIKTAVFMGCNKGEIELG |
| Microexon-tag spanning region | 6212739-6213073 |
| Microexon-tag prediction score | 0.9847 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | KRH37407x |
| Reference Transcript ID | KRH37407 |
| Gene ID | GLYMA_09G064200 |
| Gene Name | NA |
| Transcript ID | KRH37407 |
| Protein ID | KRH37407 |
| Gene ID | GLYMA_09G064200 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >KRH37407 MHPMESVFSLSVAARADFIQFLVQSFGCSYICLWAYDSISPNRLSFLDGIYNLRNNQASSSLGSVQAQQLFSQFRTLTFD INDDRVPGLAFRNQRSYLELQQLELLRLASTEIQTQFFQEARIKTAVFMGCNKGEIELGFLNMSQVDIQTTLRSLFPEDF STRVLSQQIDQNPPASSSSSLRSISTGSPEYSSLLFSIPGTSQPHFSPETLGASSSSRLVPPMQPVPNSPHQQAINNIQA LAQVPSLTQFPTPETEHDAIMRAILYVISPTTSHHHHNQQHQQNLPYSSNNSLPVVHPDASAFQRYRQDLGSNNMVSNIL RRQSLMKRSFVFFRNLNFMRMRDRIQATSRPTNTQLHHMISERRRREKLNENFQSLRALLPPGTKKDKASILIAAKETLS SLMAEVDKLSKRNQGLTSFLSAKESTTEETKVASLSPNKRLSVIISHVPESSSSEERMVELQVNVRGQVSQTDLLIRLLE FLKLAHHVSLVSMDANTHVAEGNNALHQLSFRFRIIQGSEWDESSFEEAVRRVVADLLQYQMDQ* |
| CDS seq | >KRH37407 ATGCACCCCATGGAAAGCGTCTTCTCTCTCTCTGTGGCCGCAAGGGCTGATTTTATCCAATTTCTGGTGCAGTCTTTTGG CTGCAGTTACATTTGTCTATGGGCATATGATTCCATTTCACCAAATCGTTTGAGCTTCTTGGATGGTATCTACAATCTAA GGAACAACCAAGCAAGTTCAAGTTTGGGGAGTGTGCAGGCACAACAGCTTTTCAGTCAGTTCCGGACTTTGACATTTGAT ATCAATGATGACCGTGTTCCTGGACTAGCTTTTCGGAATCAACGGTCATACCTTGAGCTCCAACAATTGGAACTTCTCAG ACTAGCATCCACAGAAATACAAACACAATTTTTTCAGGAGGCAAGGATTAAGACTGCTGTTTTCATGGGGTGTAACAAAG GAGAAATTGAGCTTGGTTTCTTAAATATGTCCCAAGTTGACATTCAAACAACACTTAGGAGTTTGTTTCCTGAAGATTTT TCCACTAGAGTACTGTCCCAGCAAATTGATCAAAACCCTCCAGCATCATCTTCATCTTCTCTGAGATCAATCTCCACAGG AAGCCCTGAATACTCATCACTTCTATTCAGTATTCCAGGAACTTCTCAACCCCACTTTTCACCTGAGACACTTGGAGCAT CATCATCATCAAGACTAGTGCCACCAATGCAGCCAGTGCCAAATAGTCCTCACCAACAAGCCATTAATAATATTCAAGCA TTGGCACAAGTCCCTTCTCTAACCCAATTCCCCACACCAGAAACTGAACATGATGCAATCATGAGAGCAATCCTCTATGT TATATCTCCAACAACTTCTCATCATCATCATAATCAACAGCACCAACAAAACTTGCCTTATAGTAGTAATAATTCTCTTC CTGTGGTGCATCCTGATGCTAGTGCATTCCAGAGGTATAGACAAGACTTAGGCTCCAACAACATGGTCTCCAATATTCTC AGAAGGCAAAGCCTCATGAAGAGATCTTTTGTGTTCTTTAGAAACTTGAATTTTATGAGAATGAGAGATCGCATTCAAGC AACGTCTCGTCCCACCAATACTCAGCTTCATCATATGATATCAGAGAGAAGAAGGCGTGAGAAGCTAAACGAGAATTTTC AATCCCTTAGAGCACTTCTTCCTCCGGGAACAAAGAAAGACAAAGCGTCTATACTGATAGCAGCAAAGGAGACATTGAGC TCTTTGATGGCTGAAGTTGATAAACTGAGCAAAAGGAATCAAGGGTTGACGTCATTTTTGTCAGCCAAAGAATCTACAAC TGAAGAAACCAAGGTAGCTAGTTTATCGCCAAATAAAAGATTAAGTGTCATAATTTCACATGTACCCGAATCAAGCTCAT CAGAAGAGAGAATGGTGGAGTTGCAAGTGAATGTGAGAGGACAAGTTTCTCAAACTGATTTATTAATCCGGTTATTGGAA TTCTTAAAACTGGCTCACCACGTGAGCTTGGTTTCCATGGACGCAAACACCCACGTTGCAGAAGGGAATAATGCACTACA TCAACTATCCTTCAGATTCAGGATTATTCAGGGAAGTGAATGGGACGAGTCTTCCTTCGAGGAAGCAGTGAGAAGAGTAG TTGCTGACTTGCTACAGTACCAAATGGACCAATAA |
| Microexon DNA seq | GAGGCAAGGATTAAG |
| Microexon Amino Acid seq | EARIK |
| Microexon-tag DNA Seq | GAACTTCTCAGACTAGCATCCACAGAAATACAAACACAATTTTTTCAGGAGGCAAGGATTAAGACTGCTGTTTTCATGGGGTGTAACAAAGGAGAAATTGAGCTTGGT |
| Microexon-tag Amino Acid seq | ELLRLASTEIQTQFFQEARIKTAVFMGCNKGEIELG |
| Transcript ID | KRH37407 |
| Gene ID | Gm.52416 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >KRH37407 MHPMESVFSLSVAARADFIQFLVQSFGCSYICLWAYDSISPNRLSFLDGIYNLRNNQASSSLGSVQAQQLFSQFRTLTFD INDDRVPGLAFRNQRSYLELQQLELLRLASTEIQTQFFQEARIKTAVFMGCNKGEIELGFLNMSQVDIQTTLRSLFPEDF STRVLSQQIDQNPPASSSSSLRSISTGSPEYSSLLFSIPGTSQPHFSPETLGASSSSRLVPPMQPVPNSPHQQAINNIQA LAQVPSLTQFPTPETEHDAIMRAILYVISPTTSHHHHNQQHQQNLPYSSNNSLPVVHPDASAFQRYRQDLGSNNMVSNIL RRQSLMKRSFVFFRNLNFMRMRDRIQATSRPTNTQLHHMISERRRREKLNENFQSLRALLPPGTKKDKASILIAAKETLS SLMAEVDKLSKRNQGLTSFLSAKESTTEETKVASLSPNKRLSVIISHVPESSSSEERMVELQVNVRGQVSQTDLLIRLLE FLKLAHHVSLVSMDANTHVAEGNNALHQLSFRFRIIQGSEWDESSFEEAVRRVVADLLQYQMDQ* |
| CDS seq | >KRH37407 ATGCACCCCATGGAAAGCGTCTTCTCTCTCTCTGTGGCCGCAAGGGCTGATTTTATCCAATTTCTGGTGCAGTCTTTTGG CTGCAGTTACATTTGTCTATGGGCATATGATTCCATTTCACCAAATCGTTTGAGCTTCTTGGATGGTATCTACAATCTAA GGAACAACCAAGCAAGTTCAAGTTTGGGGAGTGTGCAGGCACAACAGCTTTTCAGTCAGTTCCGGACTTTGACATTTGAT ATCAATGATGACCGTGTTCCTGGACTAGCTTTTCGGAATCAACGGTCATACCTTGAGCTCCAACAATTGGAACTTCTCAG ACTAGCATCCACAGAAATACAAACACAATTTTTTCAGGAGGCAAGGATTAAGACTGCTGTTTTCATGGGGTGTAACAAAG GAGAAATTGAGCTTGGTTTCTTAAATATGTCCCAAGTTGACATTCAAACAACACTTAGGAGTTTGTTTCCTGAAGATTTT TCCACTAGAGTACTGTCCCAGCAAATTGATCAAAACCCTCCAGCATCATCTTCATCTTCTCTGAGATCAATCTCCACAGG AAGCCCTGAATACTCATCACTTCTATTCAGTATTCCAGGAACTTCTCAACCCCACTTTTCACCTGAGACACTTGGAGCAT CATCATCATCAAGACTAGTGCCACCAATGCAGCCAGTGCCAAATAGTCCTCACCAACAAGCCATTAATAATATTCAAGCA TTGGCACAAGTCCCTTCTCTAACCCAATTCCCCACACCAGAAACTGAACATGATGCAATCATGAGAGCAATCCTCTATGT TATATCTCCAACAACTTCTCATCATCATCATAATCAACAGCACCAACAAAACTTGCCTTATAGTAGTAATAATTCTCTTC CTGTGGTGCATCCTGATGCTAGTGCATTCCAGAGGTATAGACAAGACTTAGGCTCCAACAACATGGTCTCCAATATTCTC AGAAGGCAAAGCCTCATGAAGAGATCTTTTGTGTTCTTTAGAAACTTGAATTTTATGAGAATGAGAGATCGCATTCAAGC AACGTCTCGTCCCACCAATACTCAGCTTCATCATATGATATCAGAGAGAAGAAGGCGTGAGAAGCTAAACGAGAATTTTC AATCCCTTAGAGCACTTCTTCCTCCGGGAACAAAGAAAGACAAAGCGTCTATACTGATAGCAGCAAAGGAGACATTGAGC TCTTTGATGGCTGAAGTTGATAAACTGAGCAAAAGGAATCAAGGGTTGACGTCATTTTTGTCAGCCAAAGAATCTACAAC TGAAGAAACCAAGGTAGCTAGTTTATCGCCAAATAAAAGATTAAGTGTCATAATTTCACATGTACCCGAATCAAGCTCAT CAGAAGAGAGAATGGTGGAGTTGCAAGTGAATGTGAGAGGACAAGTTTCTCAAACTGATTTATTAATCCGGTTATTGGAA TTCTTAAAACTGGCTCACCACGTGAGCTTGGTTTCCATGGACGCAAACACCCACGTTGCAGAAGGGAATAATGCACTACA TCAACTATCCTTCAGATTCAGGATTATTCAGGGAAGTGAATGGGACGAGTCTTCCTTCGAGGAAGCAGTGAGAAGAGTAG TTGCTGACTTGCTACAGTACCAAATGGACCAATAA |