| Microexon ID | Zm_10:139788102-139788116:+ |
| Species | Zea mays | Coordinates | 10:139788102..139788116 |
| Microexon Cluster ID | MEP42 |
| Size | 15 |
| Phase | 0 |
| Pfam Domain Motif | bHLH-MYC_N |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,15,45 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GCWMAYKATGCMGAYAGYAAARTYTTYTCTCGMKCTHTKCTWGCMAAGAGTGCWTSWATTCAGACWGTGGTRTGYWTTCCYYWYMTRGRYGGYGTBRTTGARCTWGGY |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 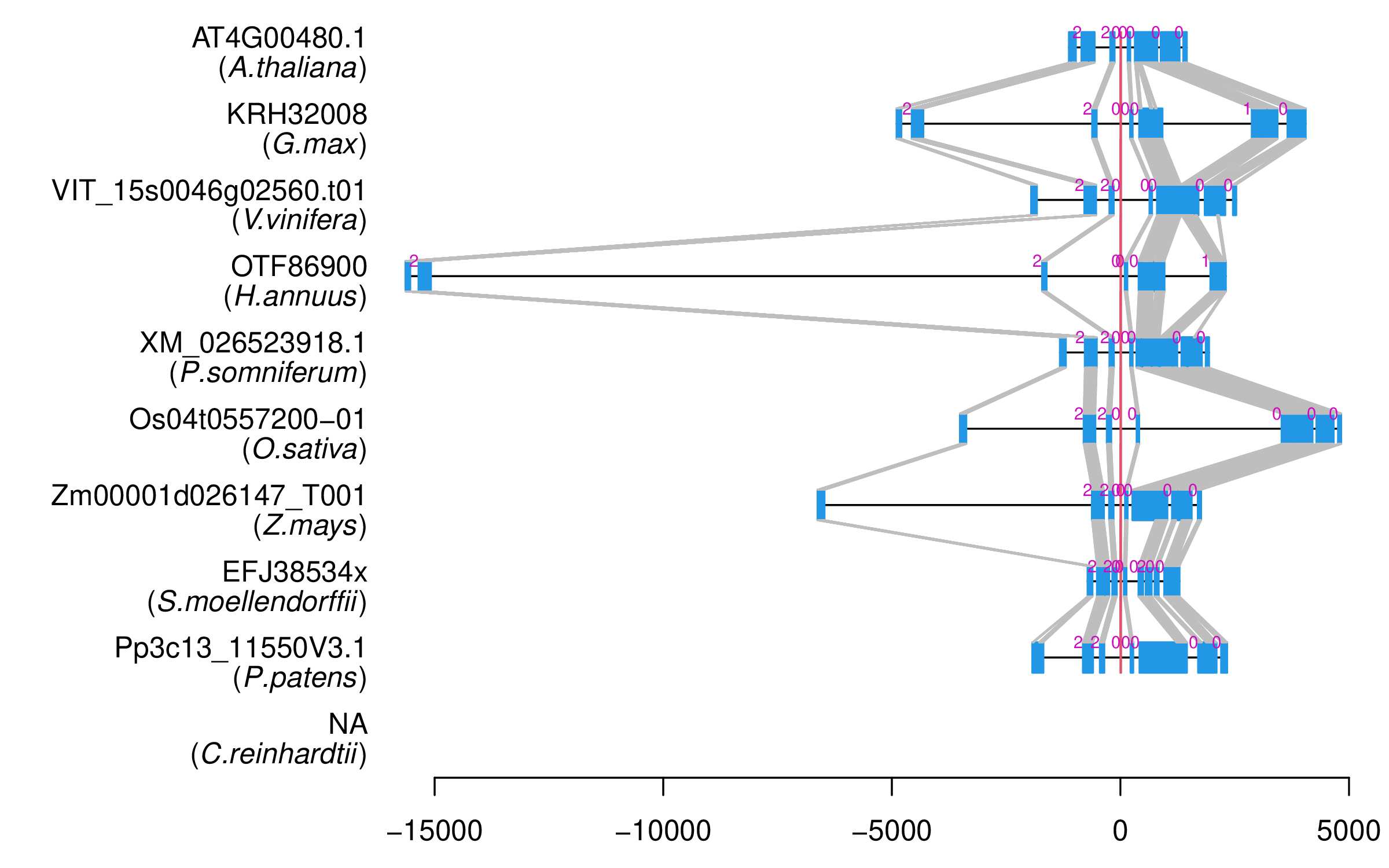 |
| Microexon DNA seq | AGCGCGTCCATTCAG |
| Microexon Amino Acid seq | SASIQ |
| Microexon-tag DNA Seq | GCGCACCTCGCCGGCAGCAAAGCCTTCCCCCGCGCGCTCCTGGCCAAGAGCGCGTCCATTCAGTCAATCCTCTGCATCCCGGTTATGGGCGGCGTGCTTGAGCTTGGT |
| Microexon-tag Amino Acid Seq | AHLAGSKAFPRALLAKSASIQSILCIPVMGGVLELG |
| Microexon-tag spanning region | 139787905-139788249 |
| Microexon-tag prediction score | 0.9071 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | Zm00001d026147_T001x |
| Reference Transcript ID | Zm00001d026147_T001 |
| Gene ID | Zm00001d026147 |
| Gene Name | colored1 |
| Transcript ID | Zm00001d026147_T001 |
| Protein ID | Zm00001d026147_P001 |
| Gene ID | Zm00001d026147 |
| Gene Name | colored1 |
| Pfam domain motif | bHLH-MYC_N |
| Motif E-value | 8.3e-47 |
| Motif start | 25 |
| Motif end | 209 |
| Protein seq | >Zm00001d026147_P001 MALSASRVQQAEELLQRPAERQLMRSQLAAAARSINWSYALFWSISDTQPGVLTWTDGFYNGEVKTRKISNSVELTSDHL VMQRSDQLRELYEALLSGEGDRRAAPARPAGSLSPEDLGDTEWYYVVSMTYAFRPGQGLPGRSFASDEHVWLCNAHLAGS KAFPRALLAKSASIQSILCIPVMGGVLELGTTDTVPEAPDLVSRATAAFWEPQCPTYSEEPSSSPSGRANETGEAAADDG TFAFEELDHNNGMDIEAMTAAGGHGQEEELRLREAEALSDDASLEHITKEIEEFYSLCDEMDLQALPLPLEDGWTVDASN FEVPCSSPQPAPPPVDRATANVAADASRAPVYGSRATSFMAWTRSSQQSSCSDDAAPAAVVPAIEEPQRLLKKVVAGGGA WESCGGATGAAQEMSGTGTKNHVMSERKRREKLNEMFLVLKSLLPSIHRVNKASILAETIAYLKELQRRVQELESSREPA SRPSETTTRLITRPSRGNNESVRKEVCAGSKRKSPELGRDDVERPPVLIMDAGTSNVTVTVSDKDVLLEVQCRWEELLMT RVFDAIKSLHLDVLSVQASAPDGFMGLKIRAQFAGSGAVVPWMISEALRKAIGKR* |
| CDS seq | >Zm00001d026147_T001 ATGGCGCTTTCAGCTTCCCGAGTTCAGCAGGCGGAAGAACTGCTGCAACGACCTGCTGAGAGGCAGCTGATGAGGAGCCA GCTTGCTGCAGCCGCCAGGAGCATCAACTGGAGCTACGCCCTCTTCTGGTCCATTTCAGACACTCAACCAGGGGTGCTGA CGTGGACGGACGGGTTCTACAACGGCGAGGTGAAGACGCGGAAGATCTCCAACTCCGTGGAGCTGACATCCGACCACCTC GTCATGCAGAGGAGCGACCAGCTCCGGGAGCTCTACGAGGCCCTGCTGTCGGGCGAGGGCGACCGCCGCGCTGCGCCTGC GCGGCCGGCCGGCTCGCTGTCGCCGGAGGACCTCGGGGACACCGAGTGGTATTACGTGGTCTCCATGACCTACGCCTTCC GGCCAGGCCAAGGGTTGCCCGGCAGGAGTTTCGCGAGCGACGAGCATGTCTGGCTGTGCAACGCGCACCTCGCCGGCAGC AAAGCCTTCCCCCGCGCGCTCCTGGCCAAGAGCGCGTCCATTCAGTCAATCCTCTGCATCCCGGTTATGGGCGGCGTGCT TGAGCTTGGTACAACTGACACGGTGCCGGAGGCCCCGGACTTGGTCAGCCGAGCAACCGCGGCTTTCTGGGAGCCGCAGT GCCCGACGTACTCGGAAGAGCCGAGCTCCAGCCCGTCAGGACGAGCAAACGAGACCGGCGAGGCCGCAGCAGACGACGGC ACGTTTGCGTTCGAGGAACTCGACCACAATAATGGCATGGACATAGAGGCGATGACCGCCGCCGGGGGACACGGGCAGGA GGAGGAGCTAAGACTAAGAGAAGCCGAGGCCCTGTCAGACGACGCAAGCCTGGAGCACATCACCAAGGAGATCGAGGAGT TCTACAGCCTCTGCGACGAAATGGACCTGCAGGCGCTACCACTACCGCTAGAGGACGGCTGGACCGTGGACGCGTCCAAT TTCGAGGTCCCCTGCTCTTCCCCGCAGCCAGCGCCGCCTCCGGTGGACAGGGCTACCGCTAACGTCGCCGCCGACGCCTC AAGGGCACCCGTCTACGGCTCTCGCGCGACGAGTTTCATGGCTTGGACGAGGTCCTCGCAGCAGTCGTCGTGCTCCGACG ACGCGGCGCCCGCAGCAGTAGTGCCGGCCATCGAGGAGCCGCAGAGATTGCTGAAGAAAGTGGTGGCCGGCGGCGGTGCT TGGGAGAGCTGTGGCGGCGCGACGGGAGCAGCACAGGAAATGAGTGGCACTGGCACCAAGAACCACGTCATGTCGGAGCG AAAGCGACGAGAGAAGCTCAACGAGATGTTCCTCGTCCTCAAGTCACTGCTTCCGTCCATTCACAGGGTGAACAAAGCGT CGATCCTCGCCGAAACGATAGCCTACCTCAAGGAGCTTCAGAGAAGGGTGCAAGAGCTGGAGTCCAGTAGGGAACCTGCG TCGCGCCCATCCGAAACGACGACAAGGCTAATAACAAGGCCCTCCCGTGGCAATAATGAGAGTGTGAGGAAGGAGGTCTG CGCGGGCTCCAAGAGGAAGAGCCCAGAGCTCGGCAGAGACGACGTGGAGCGCCCCCCGGTCCTCATCATGGACGCCGGCA CCAGCAACGTCACCGTCACCGTCTCGGACAAGGACGTGCTCCTGGAGGTGCAGTGCCGGTGGGAGGAGCTCCTGATGACG CGAGTGTTCGACGCCATCAAGAGCCTCCATTTGGACGTCCTCTCGGTTCAGGCTTCAGCGCCAGATGGCTTCATGGGGCT TAAGATACGAGCTCAGTTTGCTGGCTCCGGTGCCGTCGTGCCCTGGATGATCAGCGAGGCTCTTCGCAAAGCTATAGGGA AGCGGTGA |
| Microexon DNA seq | AGCGCGTCCATTCAG |
| Microexon Amino Acid seq | SASIQ |
| Microexon-tag DNA Seq | GCGCACCTCGCCGGCAGCAAAGCCTTCCCCCGCGCGCTCCTGGCCAAGAGCGCGTCCATTCAGTCAATCCTCTGCATCCCGGTTATGGGCGGCGTGCTTGAGCTTGGT |
| Microexon-tag Amino Acid seq | AHLAGSKAFPRALLAKSASIQSILCIPVMGGVLELG |
| Transcript ID | Zm00001d026147_T001 |
| Gene ID | Zm.8046 |
| Gene Name | colored1 |
| Pfam domain motif | bHLH-MYC_N |
| Motif E-value | 8.4e-47 |
| Motif start | 25 |
| Motif end | 209 |
| Protein seq | >Zm00001d026147_T001 MALSASRVQQAEELLQRPAERQLMRSQLAAAARSINWSYALFWSISDTQPGVLTWTDGFYNGEVKTRKISNSVELTSDHL VMQRSDQLRELYEALLSGEGDRRAAPARPAGSLSPEDLGDTEWYYVVSMTYAFRPGQGLPGRSFASDEHVWLCNAHLAGS KAFPRALLAKSASIQSILCIPVMGGVLELGTTDTVPEAPDLVSRATAAFWEPQCPTYSEEPSSSPSGRANETGEAAADDG TFAFEELDHNNGMDIEAMTAAGGHGQEEELRLREAEALSDDASLEHITKEIEEFYSLCDEMDLQALPLPLEDGWTVDASN FEVPCSSPQPAPPPVDRATANVAADASRAPVYGSRATSFMAWTRSSQQSSCSDDAAPAAVVPAIEEPQRLLKKVVAGGGA WESCGGATGAAQEMSGTGTKNHVMSERKRREKLNEMFLVLKSLLPSIHRVNKASILAETIAYLKELQRRVQELESSREPA SRPSETTTRLITRPSRGNNESVRKEVCAGSKRKSPELGRDDVERPPVLIMDAGTSNVTVTVSDKDVLLEVQCRWEELLMT RVFDAIKSLHLDVLSVQASAPDGFMGLKIRAQFAGSGAVVPWMISEALRKAIGKR* |
| CDS seq | >Zm00001d026147_T001 ATGGCGCTTTCAGCTTCCCGAGTTCAGCAGGCGGAAGAACTGCTGCAACGACCTGCTGAGAGGCAGCTGATGAGGAGCCA GCTTGCTGCAGCCGCCAGGAGCATCAACTGGAGCTACGCCCTCTTCTGGTCCATTTCAGACACTCAACCAGGGGTGCTGA CGTGGACGGACGGGTTCTACAACGGCGAGGTGAAGACGCGGAAGATCTCCAACTCCGTGGAGCTGACATCCGACCACCTC GTCATGCAGAGGAGCGACCAGCTCCGGGAGCTCTACGAGGCCCTGCTGTCGGGCGAGGGCGACCGCCGCGCTGCGCCTGC GCGGCCGGCCGGCTCGCTGTCGCCGGAGGACCTCGGGGACACCGAGTGGTATTACGTGGTCTCCATGACCTACGCCTTCC GGCCAGGCCAAGGGTTGCCCGGCAGGAGTTTCGCGAGCGACGAGCATGTCTGGCTGTGCAACGCGCACCTCGCCGGCAGC AAAGCCTTCCCCCGCGCGCTCCTGGCCAAGAGCGCGTCCATTCAGTCAATCCTCTGCATCCCGGTTATGGGCGGCGTGCT TGAGCTTGGTACAACTGACACGGTGCCGGAGGCCCCGGACTTGGTCAGCCGAGCAACCGCGGCTTTCTGGGAGCCGCAGT GCCCGACGTACTCGGAAGAGCCGAGCTCCAGCCCGTCAGGACGAGCAAACGAGACCGGCGAGGCCGCAGCAGACGACGGC ACGTTTGCGTTCGAGGAACTCGACCACAATAATGGCATGGACATAGAGGCGATGACCGCCGCCGGGGGACACGGGCAGGA GGAGGAGCTAAGACTAAGAGAAGCCGAGGCCCTGTCAGACGACGCAAGCCTGGAGCACATCACCAAGGAGATCGAGGAGT TCTACAGCCTCTGCGACGAAATGGACCTGCAGGCGCTACCACTACCGCTAGAGGACGGCTGGACCGTGGACGCGTCCAAT TTCGAGGTCCCCTGCTCTTCCCCGCAGCCAGCGCCGCCTCCGGTGGACAGGGCTACCGCTAACGTCGCCGCCGACGCCTC AAGGGCACCCGTCTACGGCTCTCGCGCGACGAGTTTCATGGCTTGGACGAGGTCCTCGCAGCAGTCGTCGTGCTCCGACG ACGCGGCGCCCGCAGCAGTAGTGCCGGCCATCGAGGAGCCGCAGAGATTGCTGAAGAAAGTGGTGGCCGGCGGCGGTGCT TGGGAGAGCTGTGGCGGCGCGACGGGAGCAGCACAGGAAATGAGTGGCACTGGCACCAAGAACCACGTCATGTCGGAGCG AAAGCGACGAGAGAAGCTCAACGAGATGTTCCTCGTCCTCAAGTCACTGCTTCCGTCCATTCACAGGGTGAACAAAGCGT CGATCCTCGCCGAAACGATAGCCTACCTCAAGGAGCTTCAGAGAAGGGTGCAAGAGCTGGAGTCCAGTAGGGAACCTGCG TCGCGCCCATCCGAAACGACGACAAGGCTAATAACAAGGCCCTCCCGTGGCAATAATGAGAGTGTGAGGAAGGAGGTCTG CGCGGGCTCCAAGAGGAAGAGCCCAGAGCTCGGCAGAGACGACGTGGAGCGCCCCCCGGTCCTCATCATGGACGCCGGCA CCAGCAACGTCACCGTCACCGTCTCGGACAAGGACGTGCTCCTGGAGGTGCAGTGCCGGTGGGAGGAGCTCCTGATGACG CGAGTGTTCGACGCCATCAAGAGCCTCCATTTGGACGTCCTCTCGGTTCAGGCTTCAGCGCCAGATGGCTTCATGGGGCT TAAGATACGAGCTCAGTTTGCTGGCTCCGGTGCCGTCGTGCCCTGGATGATCAGCGAGGCTCTTCGCAAAGCTATAGGGA AGCGGTGA |