| Microexon ID | Vv_7:1390418-1390432:- |
| Species | Vistis vinifera | Coordinates | 7:1390418..1390432 |
| Microexon Cluster ID | MEP42 |
| Size | 15 |
| Phase | 0 |
| Pfam Domain Motif | bHLH-MYC_N |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,15,45 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GCWMAYKATGCMGAYAGYAAARTYTTYTCTCGMKCTHTKCTWGCMAAGAGTGCWTSWATTCAGACWGTGGTRTGYWTTCCYYWYMTRGRYGGYGTBRTTGARCTWGGY |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 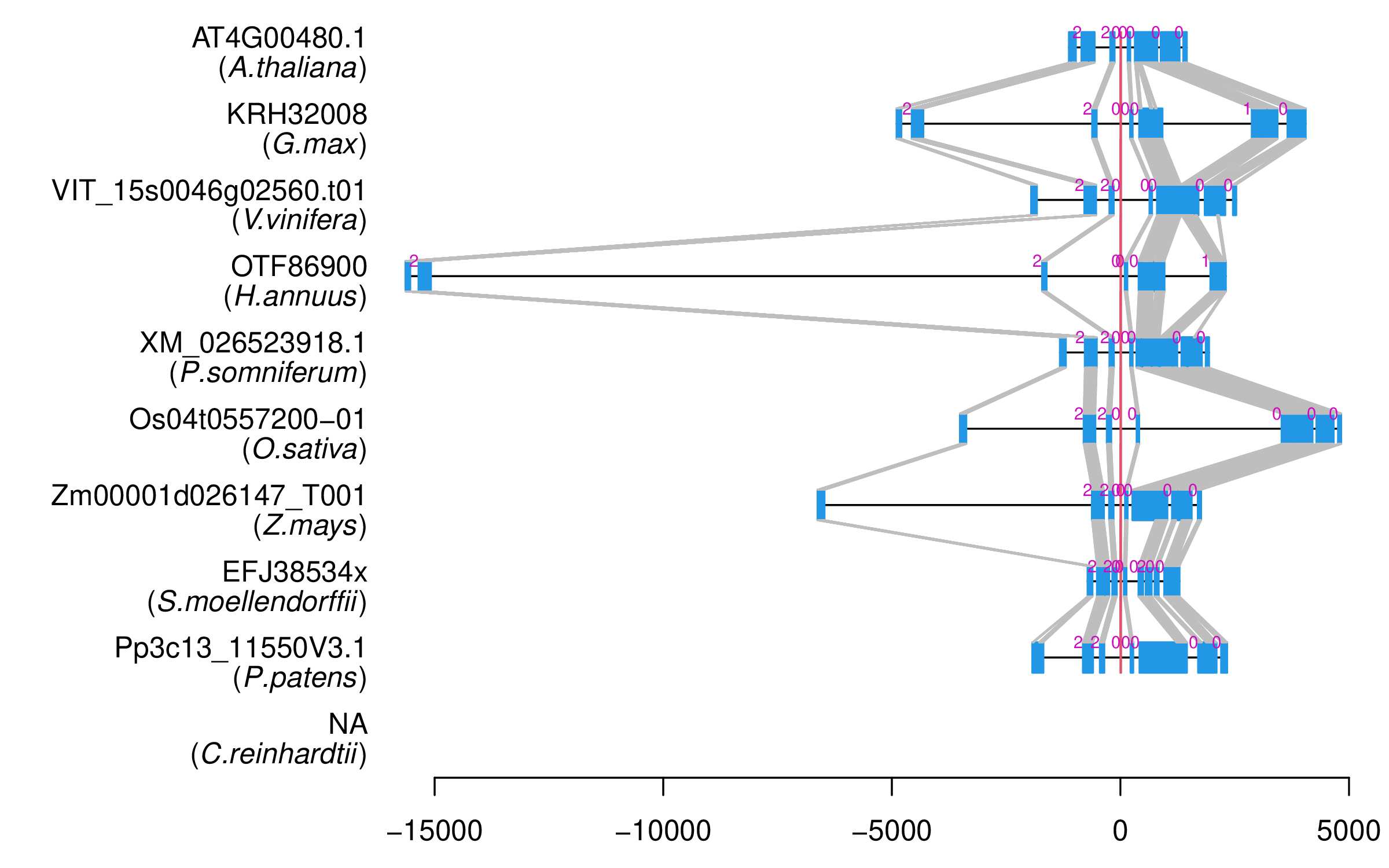 |
| Microexon DNA seq | AGTGCTCGCGTACAG |
| Microexon Amino Acid seq | SARVQ |
| Microexon-tag DNA Seq | GCAAATGAGGTCGATAGCAAAGTCTTCTCTAGAGCTATTCTTGCTAAGAGTGCTCGCGTACAGACTGTGGTTTGCATTCCTTTAATGGATGGCGTGGTTGAATTTGGC |
| Microexon-tag Amino Acid Seq | ANEVDSKVFSRAILAKSARVQTVVCIPLMDGVVEFG |
| Microexon-tag spanning region | 1390286-1390804 |
| Microexon-tag prediction score | 0.9503 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | VIT_07s0104g00090.t01x |
| Reference Transcript ID | VIT_07s0104g00090.t01 |
| Gene ID | VIT_07s0104g00090 |
| Gene Name | NA |
| Transcript ID | VIT_07s0104g00090.t01 |
| Protein ID | VIT_07s0104g00090.t01 |
| Gene ID | VIT_07s0104g00090 |
| Gene Name | NA |
| Pfam domain motif | bHLH-MYC_N |
| Motif E-value | 9.1e-53 |
| Motif start | 9 |
| Motif end | 191 |
| Protein seq | >VIT_07s0104g00090.t01 MAAPPNSRLQSMLQSAVQSVRWTYSLFWQICPQQGILVWGDGYYNGAIKTRKTVQPMEVSAEEASLQRSQQLRELYESLS AGETNQPARRPCAALSPEDLTESEWFYLMCVSFSFPPGVGLPGKAYAKRHHIWLAGANEVDSKVFSRAILAKSARVQTVV CIPLMDGVVEFGTTEKVQEDLGFVQHVKSFFTDHQLHNHPPKPALSEHSTSNPATSSDHSRFHSPPIQAAYAAADPPASN NQEEEEEEEEEEEEEEEEEEEAESDSEAETGRNNRRVRTQNTGTEGVAGSHTAAEPSELIQLEMSEGIRLGSPDDGSNNL DSDFHMLAVSQPGSSVDHQRRADSYRAESARRWPMLQDPLCSSGLQQPPPQPPTGPPPLDELSHEDTHYSQTVSTILQHQ PNRWSESSSSGCIAPYSSQSAFAKWTTRCDHHHHPMAVEGTSQWLLKYILFSVPFLHTKYRDENSPKSRDGDSAGRFRKG TPQDELSANHVLAERRRREKLNERFIILRSLVPFVTKMDKASILGDTIEYVKQLRKKIQDLEARTRQMEVEQRSRGSDSV RSKEHRIGSGGVDRNRAVVAGSDKRKLRIVEGSTGAKPKVVDSPPAAVEGGTTTVEVSIIESDALLEMQCPYREGLLLDV MQMLRDLRLETTTVQSSLTNGVFVAELRAKVKENASGKKASIMEVKRAINQIIPQC* |
| CDS seq | >VIT_07s0104g00090.t01 ATGGCTGCGCCGCCGAATAGCCGGCTTCAGAGTATGTTGCAGTCGGCGGTGCAATCAGTTCGATGGACTTACAGTCTATT CTGGCAAATCTGTCCCCAGCAAGGGATCTTAGTGTGGGGAGATGGGTATTACAATGGGGCAATCAAGACTAGGAAGACGG TGCAACCAATGGAGGTCAGCGCCGAGGAGGCGTCCCTCCAGAGAAGCCAGCAGCTAAGGGAACTCTACGAATCGCTGTCT GCTGGAGAAACCAACCAGCCAGCAAGGCGGCCATGTGCCGCCTTGTCGCCGGAGGACTTGACCGAGTCGGAGTGGTTCTA CCTGATGTGTGTCTCTTTCTCATTTCCTCCTGGGGTGGGGTTACCGGGAAAGGCATATGCAAAGCGGCACCATATATGGC TTGCAGGAGCAAATGAGGTCGATAGCAAAGTCTTCTCTAGAGCTATTCTTGCTAAGAGTGCTCGCGTACAGACTGTGGTT TGCATTCCTTTAATGGATGGCGTGGTTGAATTTGGCACCACTGAGAAGGTTCAAGAGGACCTTGGATTCGTCCAACATGT AAAAAGCTTCTTCACAGATCATCAACTCCACAACCACCCCCCTAAGCCAGCACTCTCCGAGCACTCCACTTCGAATCCCG CCACCTCATCAGACCACTCGCGTTTTCATTCTCCGCCGATCCAGGCGGCATACGCGGCAGCTGACCCACCAGCAAGTAAC AACCAAGAGGAGGAGGAGGAGGAGGAGGAAGAGGAGGAGGAGGAGGAAGAGGAAGAAGAAGAAGCTGAGTCCGACTCGGA GGCGGAAACGGGGCGAAACAATCGCAGGGTGAGGACCCAGAACACGGGGACTGAGGGCGTGGCAGGGTCTCACACGGCAG CGGAGCCGAGCGAGCTCATACAACTAGAAATGTCGGAGGGCATACGGCTGGGATCACCAGATGACGGCTCCAACAATCTG GACTCAGACTTTCACATGCTGGCTGTGAGCCAGCCAGGGAGCTCAGTAGACCATCAGCGCCGAGCTGACTCCTACAGGGC GGAGTCGGCTCGCAGGTGGCCGATGTTGCAGGACCCATTGTGCAGCAGCGGCCTCCAACAGCCTCCACCACAACCACCGA CAGGGCCCCCTCCATTGGATGAATTATCACATGAGGACACACACTATTCACAAACCGTCTCAACCATCCTTCAACACCAG CCGAACCGGTGGTCGGAGTCGTCGTCGTCCGGATGCATTGCGCCATACTCCAGCCAATCAGCGTTTGCCAAGTGGACTAC CCGCTGCGACCATCACCACCACCCCATGGCTGTGGAGGGCACCTCCCAGTGGCTGCTCAAATACATCCTCTTTAGCGTTC CCTTCCTCCACACCAAGTACCGCGACGAGAACTCTCCGAAATCCCGCGACGGCGACTCCGCCGGTCGGTTCCGCAAGGGA ACGCCTCAGGACGAGCTCAGCGCCAACCACGTCCTCGCCGAACGCCGCCGCCGCGAGAAGCTCAACGAGCGGTTCATCAT ACTCAGATCGCTGGTGCCGTTCGTGACGAAAATGGACAAGGCTTCGATTCTCGGAGACACGATAGAGTACGTGAAGCAGC TTCGGAAGAAAATCCAAGATCTGGAGGCTCGAACACGGCAGATGGAGGTGGAACAGCGATCGAGAGGATCCGATTCGGTT AGGTCAAAGGAGCATCGCATCGGGTCCGGCGGTGTAGATCGGAACAGGGCGGTGGTGGCAGGGTCAGACAAAAGGAAGTT GAGGATAGTTGAGGGGAGCACCGGCGCGAAGCCAAAGGTGGTGGATTCACCACCGGCAGCGGTGGAAGGCGGAACAACCA CCGTGGAGGTGTCGATAATAGAGAGTGACGCATTGTTGGAGATGCAATGTCCGTACAGGGAAGGGCTGTTGCTGGATGTA ATGCAGATGCTCCGAGACCTTCGGCTCGAAACGACGACGGTTCAGTCGTCGTTAACCAATGGGGTCTTCGTGGCCGAATT AAGGGCTAAGGTGAAGGAGAATGCCAGTGGGAAGAAGGCAAGCATTATGGAAGTAAAGAGGGCAATAAACCAAATAATAC CCCAGTGCTGA |
| Microexon DNA seq | AGTGCTCGCGTACAG |
| Microexon Amino Acid seq | SARVQ |
| Microexon-tag DNA Seq | GCAAATGAGGTCGATAGCAAAGTCTTCTCTAGAGCTATTCTTGCTAAGAGTGCTCGCGTACAGACTGTGGTTTGCATTCCTTTAATGGATGGCGTGGTTGAATTTGGC |
| Microexon-tag Amino Acid seq | ANEVDSKVFSRAILAKSARVQTVVCIPLMDGVVEFG |
| Transcript ID | VIT_07s0104g00090.t01 |
| Gene ID | Vv.28097 |
| Gene Name | NA |
| Pfam domain motif | bHLH-MYC_N |
| Motif E-value | 9.1e-53 |
| Motif start | 9 |
| Motif end | 191 |
| Protein seq | >VIT_07s0104g00090.t01 MAAPPNSRLQSMLQSAVQSVRWTYSLFWQICPQQGILVWGDGYYNGAIKTRKTVQPMEVSAEEASLQRSQQLRELYESLS AGETNQPARRPCAALSPEDLTESEWFYLMCVSFSFPPGVGLPGKAYAKRHHIWLAGANEVDSKVFSRAILAKSARVQTVV CIPLMDGVVEFGTTEKVQEDLGFVQHVKSFFTDHQLHNHPPKPALSEHSTSNPATSSDHSRFHSPPIQAAYAAADPPASN NQEEEEEEEEEEEEEEEEEEEAESDSEAETGRNNRRVRTQNTGTEGVAGSHTAAEPSELIQLEMSEGIRLGSPDDGSNNL DSDFHMLAVSQPGSSVDHQRRADSYRAESARRWPMLQDPLCSSGLQQPPPQPPTGPPPLDELSHEDTHYSQTVSTILQHQ PNRWSESSSSGCIAPYSSQSAFAKWTTRCDHHHHPMAVEGTSQWLLKYILFSVPFLHTKYRDENSPKSRDGDSAGRFRKG TPQDELSANHVLAERRRREKLNERFIILRSLVPFVTKMDKASILGDTIEYVKQLRKKIQDLEARTRQMEVEQRSRGSDSV RSKEHRIGSGGVDRNRAVVAGSDKRKLRIVEGSTGAKPKVVDSPPAAVEGGTTTVEVSIIESDALLEMQCPYREGLLLDV MQMLRDLRLETTTVQSSLTNGVFVAELRAKVKENASGKKASIMEVKRAINQIIPQC* |
| CDS seq | >VIT_07s0104g00090.t01 ATGGCTGCGCCGCCGAATAGCCGGCTTCAGAGTATGTTGCAGTCGGCGGTGCAATCAGTTCGATGGACTTACAGTCTATT CTGGCAAATCTGTCCCCAGCAAGGGATCTTAGTGTGGGGAGATGGGTATTACAATGGGGCAATCAAGACTAGGAAGACGG TGCAACCAATGGAGGTCAGCGCCGAGGAGGCGTCCCTCCAGAGAAGCCAGCAGCTAAGGGAACTCTACGAATCGCTGTCT GCTGGAGAAACCAACCAGCCAGCAAGGCGGCCATGTGCCGCCTTGTCGCCGGAGGACTTGACCGAGTCGGAGTGGTTCTA CCTGATGTGTGTCTCTTTCTCATTTCCTCCTGGGGTGGGGTTACCGGGAAAGGCATATGCAAAGCGGCACCATATATGGC TTGCAGGAGCAAATGAGGTCGATAGCAAAGTCTTCTCTAGAGCTATTCTTGCTAAGAGTGCTCGCGTACAGACTGTGGTT TGCATTCCTTTAATGGATGGCGTGGTTGAATTTGGCACCACTGAGAAGGTTCAAGAGGACCTTGGATTCGTCCAACATGT AAAAAGCTTCTTCACAGATCATCAACTCCACAACCACCCCCCTAAGCCAGCACTCTCCGAGCACTCCACTTCGAATCCCG CCACCTCATCAGACCACTCGCGTTTTCATTCTCCGCCGATCCAGGCGGCATACGCGGCAGCTGACCCACCAGCAAGTAAC AACCAAGAGGAGGAGGAGGAGGAGGAGGAAGAGGAGGAGGAGGAGGAAGAGGAAGAAGAAGAAGCTGAGTCCGACTCGGA GGCGGAAACGGGGCGAAACAATCGCAGGGTGAGGACCCAGAACACGGGGACTGAGGGCGTGGCAGGGTCTCACACGGCAG CGGAGCCGAGCGAGCTCATACAACTAGAAATGTCGGAGGGCATACGGCTGGGATCACCAGATGACGGCTCCAACAATCTG GACTCAGACTTTCACATGCTGGCTGTGAGCCAGCCAGGGAGCTCAGTAGACCATCAGCGCCGAGCTGACTCCTACAGGGC GGAGTCGGCTCGCAGGTGGCCGATGTTGCAGGACCCATTGTGCAGCAGCGGCCTCCAACAGCCTCCACCACAACCACCGA CAGGGCCCCCTCCATTGGATGAATTATCACATGAGGACACACACTATTCACAAACCGTCTCAACCATCCTTCAACACCAG CCGAACCGGTGGTCGGAGTCGTCGTCGTCCGGATGCATTGCGCCATACTCCAGCCAATCAGCGTTTGCCAAGTGGACTAC CCGCTGCGACCATCACCACCACCCCATGGCTGTGGAGGGCACCTCCCAGTGGCTGCTCAAATACATCCTCTTTAGCGTTC CCTTCCTCCACACCAAGTACCGCGACGAGAACTCTCCGAAATCCCGCGACGGCGACTCCGCCGGTCGGTTCCGCAAGGGA ACGCCTCAGGACGAGCTCAGCGCCAACCACGTCCTCGCCGAACGCCGCCGCCGCGAGAAGCTCAACGAGCGGTTCATCAT ACTCAGATCGCTGGTGCCGTTCGTGACGAAAATGGACAAGGCTTCGATTCTCGGAGACACGATAGAGTACGTGAAGCAGC TTCGGAAGAAAATCCAAGATCTGGAGGCTCGAACACGGCAGATGGAGGTGGAACAGCGATCGAGAGGATCCGATTCGGTT AGGTCAAAGGAGCATCGCATCGGGTCCGGCGGTGTAGATCGGAACAGGGCGGTGGTGGCAGGGTCAGACAAAAGGAAGTT GAGGATAGTTGAGGGGAGCACCGGCGCGAAGCCAAAGGTGGTGGATTCACCACCGGCAGCGGTGGAAGGCGGAACAACCA CCGTGGAGGTGTCGATAATAGAGAGTGACGCATTGTTGGAGATGCAATGTCCGTACAGGGAAGGGCTGTTGCTGGATGTA ATGCAGATGCTCCGAGACCTTCGGCTCGAAACGACGACGGTTCAGTCGTCGTTAACCAATGGGGTCTTCGTGGCCGAATT AAGGGCTAAGGTGAAGGAGAATGCCAGTGGGAAGAAGGCAAGCATTATGGAAGTAAAGAGGGCAATAAACCAAATAATAC CCCAGTGCTGA |