| Microexon ID | Ps_NC_039365.1:4844682-4844696:+ |
| Species | Papaver somniferum | Coordinates | NC_039365.1:4844682..4844696 |
| Microexon Cluster ID | MEP42 |
| Size | 15 |
| Phase | 0 |
| Pfam Domain Motif | bHLH-MYC_N |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,15,45 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GCWMAYKATGCMGAYAGYAAARTYTTYTCTCGMKCTHTKCTWGCMAAGAGTGCWTSWATTCAGACWGTGGTRTGYWTTCCYYWYMTRGRYGGYGTBRTTGARCTWGGY |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 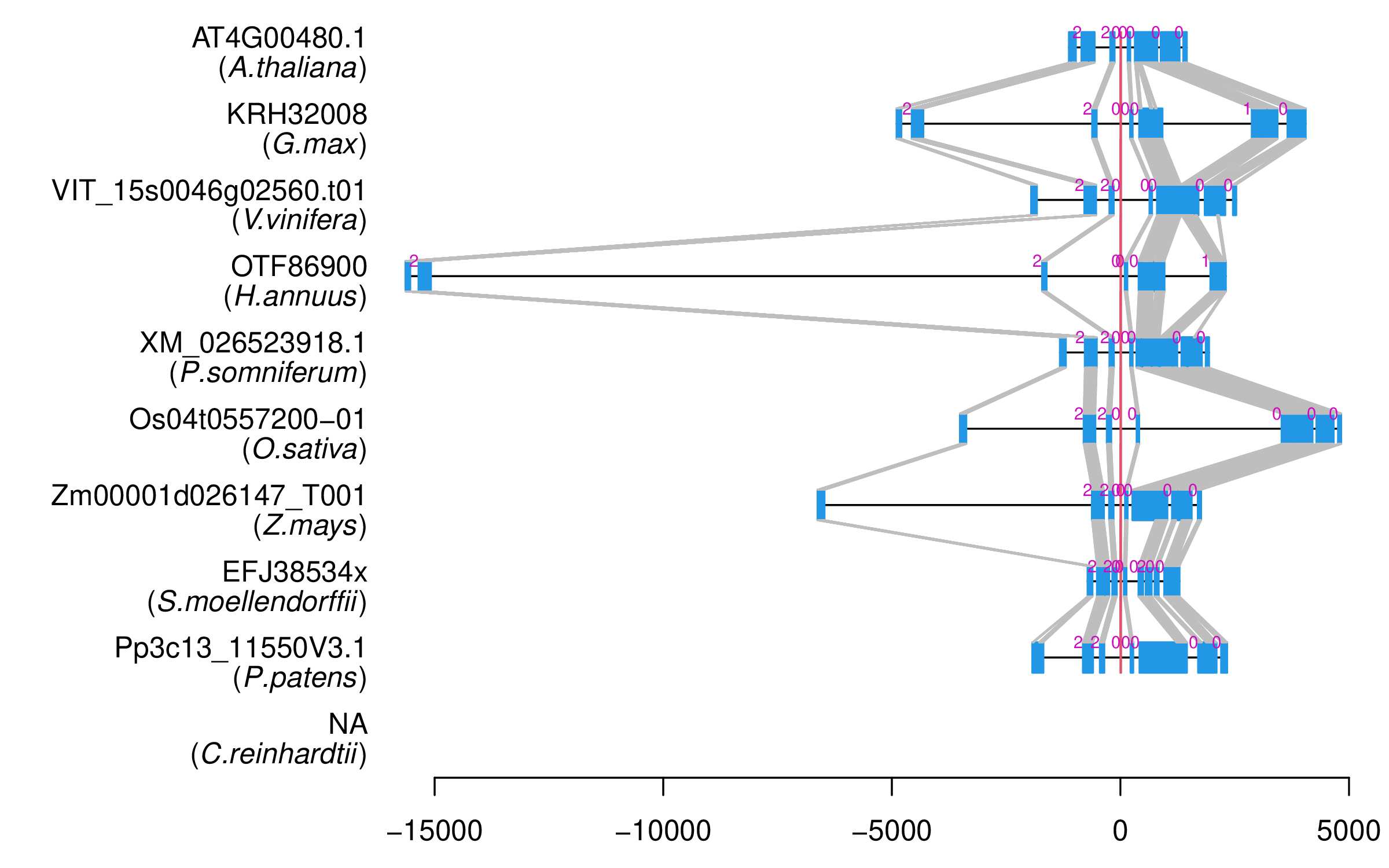 |
| Microexon DNA seq | AGTGCCTCCATTCAG |
| Microexon Amino Acid seq | SASIQ |
| Microexon-tag DNA Seq | GCTCATTGTGCAGATAGCAAAGTTTACATTCGATCACTACTTGCAAAGAGTGCCTCCATTCAGACTGTTGTGTGCTTTCCTTTCTTGGGCGGTGTGATCGAGCTAGGC |
| Microexon-tag Amino Acid Seq | AHCADSKVYIRSLLAKSASIQTVVCFPFLGGVIELG |
| Microexon-tag spanning region | 4844494-4845056 |
| Microexon-tag prediction score | 0.9486 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026553321.1x |
| Reference Transcript ID | XM_026553321.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026553321.1 |
| Protein ID | XP_026409106.1 |
| Gene ID | LOC113304253 |
| Gene Name | NA |
| Pfam domain motif | bHLH-MYC_N |
| Motif E-value | 8.1e-52 |
| Motif start | 17 |
| Motif end | 202 |
| Protein seq | >XP_026409106.1 MATPGLQNHQGVAETHLKHQLAVAVRSIQWSYAIFWTPSAKNKGGLEWGAGYYNGDIKTRKTVQLQHMEISANRLGLQRS EQLRELYESLAESESNQQARRPSASLSPEDLSDAEWYYLVCMSFTFSSGQGLPGRVFSTGQPIWLCDAHCADSKVYIRSL LAKSASIQTVVCFPFLGGVIELGVTEMVPEDLALVQHVKTVFMELKKPSCSLNGDKIGEDILGTEIIHEIVDTVAALDCG IQHSSYYLPQSILKEEIELQQNGVNTVIDEDLIANSPSSDECESDEEDSYMVNGGNLGVSQVQSWQFLGDEFEHSNGMQG SESSSDCVSQKSFLNQEKSSSQLKKTNSVQGLQECNHTKFNDLDLGTDDMHYKRTLSVIFKTSNALVTAPCSNSANHKSS FRRWKRRGLVGYVKNKSGTPQKMLKQILFDVPLMHSGAYLKSNDGKEFENGVLKSEGHDIAIGHEKREALDDKFLVLRSL VPSINKFDRTSLLSDTVDYLKELERRVEELESCREFTEFETIEKRKHPDIVERTSDNYGYNENANSPKAVLHKRKACDID EIDPELDSVSPKDNVATYVTVCMIEKEVLVEIRCPWKDCLIIEIIDAISNLHLDAHSIQSAATEGILTLTLKSKFKGAEV VSAGMIKQAIQRVIGTC* |
| CDS seq | >XM_026553321.1 ATGGCTACTCCTGGACTCCAAAACCATCAAGGAGTTGCAGAAACCCATCTTAAACATCAACTTGCTGTTGCTGTGAGGAG TATTCAATGGAGTTATGCAATCTTTTGGACTCCCTCTGCTAAGAATAAAGGGGGTTTGGAATGGGGTGCTGGTTACTACA ATGGAGATATCAAGACAAGGAAGACAGTGCAACTGCAGCATATGGAAATTAGTGCAAATCGATTGGGTTTACAAAGGAGT GAACAATTGAGAGAACTGTACGAGTCTCTTGCAGAAAGTGAAAGTAACCAACAAGCAAGAAGACCTTCAGCTTCATTGTC TCCGGAAGATCTTTCGGACGCGGAGTGGTATTACTTAGTTTGTATGTCCTTCACATTCAGTTCTGGTCAAGGCTTGCCAG GAAGAGTATTCTCAACCGGTCAACCTATTTGGCTGTGTGATGCTCATTGTGCAGATAGCAAAGTTTACATTCGATCACTA CTTGCAAAGAGTGCCTCCATTCAGACTGTTGTGTGCTTTCCTTTCTTGGGCGGTGTGATCGAGCTAGGCGTGACTGAAAT GGTTCCTGAAGATCTTGCTTTGGTTCAACATGTTAAAACTGTCTTCATGGAGTTGAAAAAGCCTAGTTGCTCCCTGAATG GAGATAAAATCGGTGAAGATATTTTGGGTACTGAAATTATTCATGAGATAGTTGATACTGTGGCAGCATTAGATTGTGGA ATTCAACACAGTTCATACTATCTTCCTCAGTCCATTCTAAAAGAAGAAATCGAGCTTCAACAAAATGGTGTAAACACAGT TATTGATGAAGATTTAATTGCTAACTCTCCTAGTTCAGATGAATGTGAATCTGATGAAGAGGATTCCTACATGGTAAATG GTGGAAATCTCGGTGTTTCTCAAGTTCAAAGCTGGCAATTCTTGGGTGATGAATTTGAACATAGTAACGGGATGCAAGGT TCAGAAAGTTCAAGTGACTGTGTATCTCAGAAGTCATTTTTGAATCAAGAGAAATCTTCTTCTCAGCTGAAAAAAACAAA TAGTGTTCAAGGGCTTCAAGAATGCAATCATACAAAGTTCAACGATTTGGATCTTGGGACTGATGATATGCACTACAAAA GAACACTTTCCGTCATTTTCAAAACTTCCAATGCACTGGTAACAGCACCATGTTCTAATAGTGCTAATCACAAATCCAGT TTCAGGAGATGGAAGCGGCGAGGCTTAGTGGGTTATGTGAAGAATAAATCTGGAACACCACAGAAAATGTTGAAGCAAAT TTTGTTTGATGTTCCTTTGATGCACAGTGGGGCTTATCTGAAATCAAATGATGGAAAGGAATTTGAAAATGGGGTTTTGA AATCAGAAGGACATGATATTGCTATAGGCCACGAAAAAAGAGAAGCACTTGATGACAAGTTTCTCGTTCTCAGATCCTTA GTTCCCTCTATAAACAAGTTCGATAGGACATCTCTCCTCAGTGACACGGTAGATTACTTGAAAGAGCTCGAGAGAAGAGT CGAAGAGCTAGAATCATGCAGGGAGTTTACAGAGTTTGAAACTATAGAGAAAAGGAAACACCCGGATATAGTAGAAAGGA CTTCTGATAATTACGGGTATAATGAAAATGCTAACAGTCCAAAGGCCGTGTTACACAAGAGAAAAGCTTGCGATATTGAT GAAATAGACCCTGAGCTAGATTCTGTGTCACCTAAAGACAATGTAGCAACATATGTTACAGTCTGCATGATTGAGAAAGA GGTTTTGGTTGAGATACGCTGTCCATGGAAAGATTGCTTAATCATCGAAATTATAGATGCAATAAGTAATCTCCATTTGG ATGCTCATTCAATTCAGTCTGCAGCAACTGAAGGCATTCTTACTCTAACCCTGAAATCTAAGTTCAAAGGAGCCGAAGTT GTATCAGCAGGAATGATCAAACAAGCAATTCAGAGAGTTATTGGTACCTGCTGA |
| Microexon DNA seq | AGTGCCTCCATTCAG |
| Microexon Amino Acid seq | SASIQ |
| Microexon-tag DNA Seq | GCTCATTGTGCAGATAGCAAAGTTTACATTCGATCACTACTTGCAAAGAGTGCCTCCATTCAGACTGTTGTGTGCTTTCCTTTCTTGGGCGGTGTGATCGAGCTAGGC |
| Microexon-tag Amino Acid seq | AHCADSKVYIRSLLAKSASIQTVVCFPFLGGVIELG |
| Transcript ID | XM_026553321.1 |
| Gene ID | Ps.47730 |
| Gene Name | NA |
| Pfam domain motif | bHLH-MYC_N |
| Motif E-value | 8.1e-52 |
| Motif start | 17 |
| Motif end | 202 |
| Protein seq | >XM_026553321.1 MATPGLQNHQGVAETHLKHQLAVAVRSIQWSYAIFWTPSAKNKGGLEWGAGYYNGDIKTRKTVQLQHMEISANRLGLQRS EQLRELYESLAESESNQQARRPSASLSPEDLSDAEWYYLVCMSFTFSSGQGLPGRVFSTGQPIWLCDAHCADSKVYIRSL LAKSASIQTVVCFPFLGGVIELGVTEMVPEDLALVQHVKTVFMELKKPSCSLNGDKIGEDILGTEIIHEIVDTVAALDCG IQHSSYYLPQSILKEEIELQQNGVNTVIDEDLIANSPSSDECESDEEDSYMVNGGNLGVSQVQSWQFLGDEFEHSNGMQG SESSSDCVSQKSFLNQEKSSSQLKKTNSVQGLQECNHTKFNDLDLGTDDMHYKRTLSVIFKTSNALVTAPCSNSANHKSS FRRWKRRGLVGYVKNKSGTPQKMLKQILFDVPLMHSGAYLKSNDGKEFENGVLKSEGHDIAIGHEKREALDDKFLVLRSL VPSINKFDRTSLLSDTVDYLKELERRVEELESCREFTEFETIEKRKHPDIVERTSDNYGYNENANSPKAVLHKRKACDID EIDPELDSVSPKDNVATYVTVCMIEKEVLVEIRCPWKDCLIIEIIDAISNLHLDAHSIQSAATEGILTLTLKSKFKGAEV VSAGMIKQAIQRVIGTC* |
| CDS seq | >XM_026553321.1 ATGGCTACTCCTGGACTCCAAAACCATCAAGGAGTTGCAGAAACCCATCTTAAACATCAACTTGCTGTTGCTGTGAGGAG TATTCAATGGAGTTATGCAATCTTTTGGACTCCCTCTGCTAAGAATAAAGGGGGTTTGGAATGGGGTGCTGGTTACTACA ATGGAGATATCAAGACAAGGAAGACAGTGCAACTGCAGCATATGGAAATTAGTGCAAATCGATTGGGTTTACAAAGGAGT GAACAATTGAGAGAACTGTACGAGTCTCTTGCAGAAAGTGAAAGTAACCAACAAGCAAGAAGACCTTCAGCTTCATTGTC TCCGGAAGATCTTTCGGACGCGGAGTGGTATTACTTAGTTTGTATGTCCTTCACATTCAGTTCTGGTCAAGGCTTGCCAG GAAGAGTATTCTCAACCGGTCAACCTATTTGGCTGTGTGATGCTCATTGTGCAGATAGCAAAGTTTACATTCGATCACTA CTTGCAAAGAGTGCCTCCATTCAGACTGTTGTGTGCTTTCCTTTCTTGGGCGGTGTGATCGAGCTAGGCGTGACTGAAAT GGTTCCTGAAGATCTTGCTTTGGTTCAACATGTTAAAACTGTCTTCATGGAGTTGAAAAAGCCTAGTTGCTCCCTGAATG GAGATAAAATCGGTGAAGATATTTTGGGTACTGAAATTATTCATGAGATAGTTGATACTGTGGCAGCATTAGATTGTGGA ATTCAACACAGTTCATACTATCTTCCTCAGTCCATTCTAAAAGAAGAAATCGAGCTTCAACAAAATGGTGTAAACACAGT TATTGATGAAGATTTAATTGCTAACTCTCCTAGTTCAGATGAATGTGAATCTGATGAAGAGGATTCCTACATGGTAAATG GTGGAAATCTCGGTGTTTCTCAAGTTCAAAGCTGGCAATTCTTGGGTGATGAATTTGAACATAGTAACGGGATGCAAGGT TCAGAAAGTTCAAGTGACTGTGTATCTCAGAAGTCATTTTTGAATCAAGAGAAATCTTCTTCTCAGCTGAAAAAAACAAA TAGTGTTCAAGGGCTTCAAGAATGCAATCATACAAAGTTCAACGATTTGGATCTTGGGACTGATGATATGCACTACAAAA GAACACTTTCCGTCATTTTCAAAACTTCCAATGCACTGGTAACAGCACCATGTTCTAATAGTGCTAATCACAAATCCAGT TTCAGGAGATGGAAGCGGCGAGGCTTAGTGGGTTATGTGAAGAATAAATCTGGAACACCACAGAAAATGTTGAAGCAAAT TTTGTTTGATGTTCCTTTGATGCACAGTGGGGCTTATCTGAAATCAAATGATGGAAAGGAATTTGAAAATGGGGTTTTGA AATCAGAAGGACATGATATTGCTATAGGCCACGAAAAAAGAGAAGCACTTGATGACAAGTTTCTCGTTCTCAGATCCTTA GTTCCCTCTATAAACAAGTTCGATAGGACATCTCTCCTCAGTGACACGGTAGATTACTTGAAAGAGCTCGAGAGAAGAGT CGAAGAGCTAGAATCATGCAGGGAGTTTACAGAGTTTGAAACTATAGAGAAAAGGAAACACCCGGATATAGTAGAAAGGA CTTCTGATAATTACGGGTATAATGAAAATGCTAACAGTCCAAAGGCCGTGTTACACAAGAGAAAAGCTTGCGATATTGAT GAAATAGACCCTGAGCTAGATTCTGTGTCACCTAAAGACAATGTAGCAACATATGTTACAGTCTGCATGATTGAGAAAGA GGTTTTGGTTGAGATACGCTGTCCATGGAAAGATTGCTTAATCATCGAAATTATAGATGCAATAAGTAATCTCCATTTGG ATGCTCATTCAATTCAGTCTGCAGCAACTGAAGGCATTCTTACTCTAACCCTGAAATCTAAGTTCAAAGGAGCCGAAGTT GTATCAGCAGGAATGATCAAACAAGCAATTCAGAGAGTTATTGGTACCTGCTGA |