| Microexon ID | Ps_NC_039361.1:958338-958352:- |
| Species | Papaver somniferum | Coordinates | NC_039361.1:958338..958352 |
| Microexon Cluster ID | MEP42 |
| Size | 15 |
| Phase | 0 |
| Pfam Domain Motif | bHLH-MYC_N |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,15,45 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GCWMAYKATGCMGAYAGYAAARTYTTYTCTCGMKCTHTKCTWGCMAAGAGTGCWTSWATTCAGACWGTGGTRTGYWTTCCYYWYMTRGRYGGYGTBRTTGARCTWGGY |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 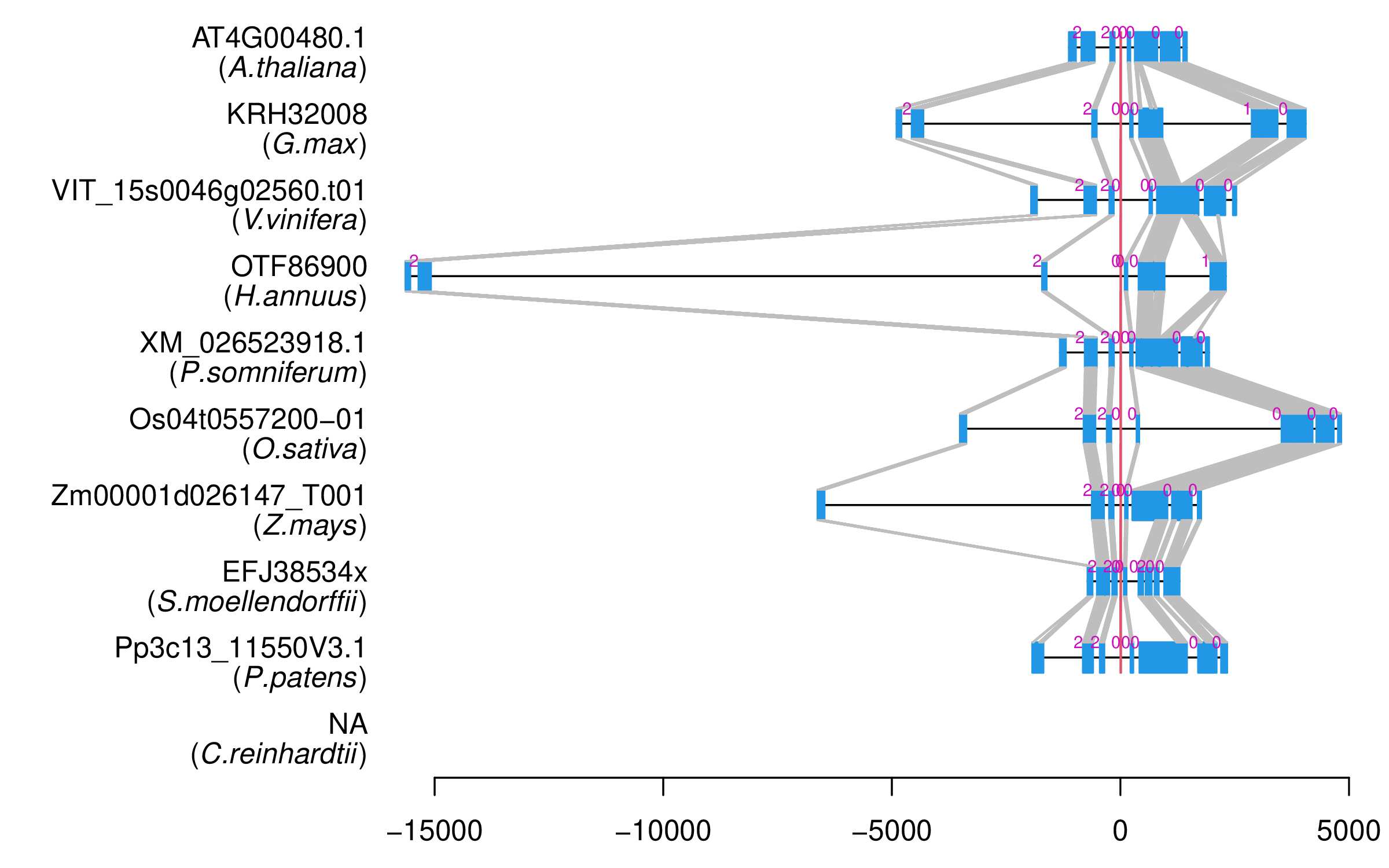 |
| Microexon DNA seq | AGTGCCTCCATTCAG |
| Microexon Amino Acid seq | SASIQ |
| Microexon-tag DNA Seq | GCTCATTGTGCAGACAGCAAAGTTTACATTCGATCTCTACTTGCAAAGAGTGCCTCCATTCAGACTGTTGTGTGCTTTCCTTTCTTGGGCGGTGTGATCGAGCTAGGC |
| Microexon-tag Amino Acid Seq | AHCADSKVYIRSLLAKSASIQTVVCFPFLGGVIELG |
| Microexon-tag spanning region | 958095-958541 |
| Microexon-tag prediction score | 0.9538 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026523918.1x |
| Reference Transcript ID | XM_026523918.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026523918.1 |
| Protein ID | XP_026379703.1 |
| Gene ID | LOC113274545 |
| Gene Name | NA |
| Pfam domain motif | bHLH-MYC_N |
| Motif E-value | 8e-52 |
| Motif start | 17 |
| Motif end | 202 |
| Protein seq | >XP_026379703.1 MATPGLQNHQGVAETHLKHQLAVAVRSIQWSYAIFWTPSAKNKGGLEWGAGYYNGDIKTRKTVQLQHMEISANRLGLQRS EQLRELYESLAESESNQQARRPSASLSPEDLSDAEWYYLVCMSFTFSSGQGLPGRVFSTGQPIWLCDAHCADSKVYIRSL LAKSASIQTVVCFPFLGGVIELGVTEMVPEDLALVQHVKTVFMELKKPSCSPNGDKIGEDILGTDIVHEIVDTVAGLECG IQHSSYYLPQSILKEEIELQQNGVNTDADLIANSPSSDECESDEEDSYMMNGGNLGVSQVQSWQFVGDEFEHSNGMQGSE SSSDCVSQKSFFNQEKASSQLKKTNSVQGLQECNHTKFNDLDLGTDDMHYKRTLSVIFKTSSALVTAPCSNSGNHKSSFR RWKRRGLVGYQKSRSGTPQKMLKKIMFDVPLMHGGGYLKSNDGKEFENGVLKSEGHDIALGHEKREALDDKFLVLRSLVP SINKFDRTSLLSDTVDYLKELERRVEELESCREFTEFETIEKRKHPDIVERTSDNYGYNENANSPKAVLNKRKACDIDEI DPELDSVSPKDNVATYVTVCVIEKEVLVEIRCPWKDCLLIEIIDAISNLHLDAHSIQSAATEGILTLTLKSKFKGAEVVS AGMIKQAIQRVIGTC* |
| CDS seq | >XM_026523918.1 ATGGCTACTCCTGGACTCCAAAACCATCAAGGAGTTGCAGAAACTCATCTTAAACATCAACTTGCTGTTGCTGTGAGGAG TATTCAATGGAGTTATGCAATCTTTTGGACTCCCTCTGCTAAGAATAAAGGGGGTTTGGAATGGGGTGCTGGTTACTACA ATGGAGATATCAAGACAAGGAAGACAGTGCAACTGCAACATATGGAAATTAGTGCAAATCGATTGGGTTTACAAAGGAGT GAACAATTGAGAGAACTGTACGAGTCTCTTGCAGAAAGTGAAAGTAACCAACAAGCAAGAAGACCTTCAGCTTCATTGTC TCCGGAAGATCTTTCGGACGCGGAGTGGTATTACTTAGTTTGTATGTCCTTCACATTCAGTTCTGGTCAAGGCTTGCCAG GAAGAGTATTCTCAACCGGTCAACCTATTTGGCTATGTGATGCTCATTGTGCAGACAGCAAAGTTTACATTCGATCTCTA CTTGCAAAGAGTGCCTCCATTCAGACTGTTGTGTGCTTTCCTTTCTTGGGCGGTGTGATCGAGCTAGGCGTGACTGAAAT GGTTCCTGAAGATCTTGCTTTGGTTCAACACGTTAAAACTGTCTTCATGGAGTTGAAGAAGCCTAGTTGCTCTCCGAATG GAGATAAAATTGGTGAAGATATTTTGGGTACTGATATTGTTCATGAGATAGTTGATACTGTAGCAGGATTAGAATGTGGA ATTCAACACAGTTCATATTATCTCCCTCAATCCATTCTAAAAGAAGAAATTGAACTTCAACAAAATGGTGTAAACACAGA TGCAGATTTAATTGCTAACTCTCCTAGTTCAGATGAATGTGAATCTGATGAAGAGGATTCTTACATGATGAATGGTGGAA ATCTCGGTGTTTCTCAAGTTCAAAGCTGGCAATTCGTGGGTGATGAATTTGAACATAGTAACGGGATGCAAGGTTCAGAA AGTTCAAGTGACTGTGTATCTCAGAAGTCATTTTTTAATCAAGAGAAAGCTTCTTCCCAGCTGAAAAAAACAAATAGTGT TCAAGGGCTTCAAGAATGCAACCATACAAAGTTTAATGATTTGGATCTTGGCACTGATGATATGCACTATAAAAGAACAC TTTCCGTCATTTTCAAAACATCCAGTGCACTGGTAACGGCACCATGTTCTAATAGTGGTAATCACAAATCCAGTTTCAGG AGATGGAAGCGGCGAGGCCTAGTGGGTTATCAAAAGAGTAGATCTGGAACACCACAGAAAATGTTGAAGAAAATTATGTT TGATGTTCCTCTGATGCACGGTGGGGGTTATCTGAAATCAAATGATGGGAAAGAATTTGAAAATGGGGTTTTGAAATCAG AAGGACATGATATTGCTTTAGGCCACGAAAAAAGAGAAGCACTCGATGACAAGTTTCTTGTTCTCAGATCTTTAGTTCCC TCCATAAACAAGTTTGATAGGACATCTCTCCTCAGTGACACGGTAGATTACTTGAAAGAGCTCGAGAGAAGAGTTGAAGA GCTAGAATCCTGCAGGGAGTTTACAGAGTTTGAAACTATAGAGAAAAGGAAACACCCGGATATAGTAGAAAGGACTTCTG ATAATTACGGGTATAATGAAAATGCTAACAGTCCAAAGGCCGTATTAAACAAGAGAAAAGCTTGCGATATTGATGAAATA GACCCTGAGCTAGATTCTGTTTCACCTAAAGACAATGTAGCAACATATGTTACAGTCTGCGTGATCGAGAAAGAGGTTTT GGTTGAGATACGCTGTCCATGGAAAGATTGCTTACTCATCGAAATTATAGATGCAATAAGTAATCTCCATTTGGATGCTC ATTCAATTCAGTCAGCAGCAACTGAAGGCATCCTCACTCTAACCCTCAAATCTAAGTTCAAAGGAGCCGAAGTTGTATCA GCAGGAATGATCAAACAAGCAATTCAGAGAGTTATTGGTACCTGCTGA |
| Microexon DNA seq | AGTGCCTCCATTCAG |
| Microexon Amino Acid seq | SASIQ |
| Microexon-tag DNA Seq | GCTCATTGTGCAGACAGCAAAGTTTACATTCGATCTCTACTTGCAAAGAGTGCCTCCATTCAGACTGTTGTGTGCTTTCCTTTCTTGGGCGGTGTGATCGAGCTAGGC |
| Microexon-tag Amino Acid seq | AHCADSKVYIRSLLAKSASIQTVVCFPFLGGVIELG |
| Transcript ID | XM_026523918.1 |
| Gene ID | Ps.22180 |
| Gene Name | NA |
| Pfam domain motif | bHLH-MYC_N |
| Motif E-value | 8e-52 |
| Motif start | 17 |
| Motif end | 202 |
| Protein seq | >XM_026523918.1 MATPGLQNHQGVAETHLKHQLAVAVRSIQWSYAIFWTPSAKNKGGLEWGAGYYNGDIKTRKTVQLQHMEISANRLGLQRS EQLRELYESLAESESNQQARRPSASLSPEDLSDAEWYYLVCMSFTFSSGQGLPGRVFSTGQPIWLCDAHCADSKVYIRSL LAKSASIQTVVCFPFLGGVIELGVTEMVPEDLALVQHVKTVFMELKKPSCSPNGDKIGEDILGTDIVHEIVDTVAGLECG IQHSSYYLPQSILKEEIELQQNGVNTDADLIANSPSSDECESDEEDSYMMNGGNLGVSQVQSWQFVGDEFEHSNGMQGSE SSSDCVSQKSFFNQEKASSQLKKTNSVQGLQECNHTKFNDLDLGTDDMHYKRTLSVIFKTSSALVTAPCSNSGNHKSSFR RWKRRGLVGYQKSRSGTPQKMLKKIMFDVPLMHGGGYLKSNDGKEFENGVLKSEGHDIALGHEKREALDDKFLVLRSLVP SINKFDRTSLLSDTVDYLKELERRVEELESCREFTEFETIEKRKHPDIVERTSDNYGYNENANSPKAVLNKRKACDIDEI DPELDSVSPKDNVATYVTVCVIEKEVLVEIRCPWKDCLLIEIIDAISNLHLDAHSIQSAATEGILTLTLKSKFKGAEVVS AGMIKQAIQRVIGTC* |
| CDS seq | >XM_026523918.1 ATGGCTACTCCTGGACTCCAAAACCATCAAGGAGTTGCAGAAACTCATCTTAAACATCAACTTGCTGTTGCTGTGAGGAG TATTCAATGGAGTTATGCAATCTTTTGGACTCCCTCTGCTAAGAATAAAGGGGGTTTGGAATGGGGTGCTGGTTACTACA ATGGAGATATCAAGACAAGGAAGACAGTGCAACTGCAACATATGGAAATTAGTGCAAATCGATTGGGTTTACAAAGGAGT GAACAATTGAGAGAACTGTACGAGTCTCTTGCAGAAAGTGAAAGTAACCAACAAGCAAGAAGACCTTCAGCTTCATTGTC TCCGGAAGATCTTTCGGACGCGGAGTGGTATTACTTAGTTTGTATGTCCTTCACATTCAGTTCTGGTCAAGGCTTGCCAG GAAGAGTATTCTCAACCGGTCAACCTATTTGGCTATGTGATGCTCATTGTGCAGACAGCAAAGTTTACATTCGATCTCTA CTTGCAAAGAGTGCCTCCATTCAGACTGTTGTGTGCTTTCCTTTCTTGGGCGGTGTGATCGAGCTAGGCGTGACTGAAAT GGTTCCTGAAGATCTTGCTTTGGTTCAACACGTTAAAACTGTCTTCATGGAGTTGAAGAAGCCTAGTTGCTCTCCGAATG GAGATAAAATTGGTGAAGATATTTTGGGTACTGATATTGTTCATGAGATAGTTGATACTGTAGCAGGATTAGAATGTGGA ATTCAACACAGTTCATATTATCTCCCTCAATCCATTCTAAAAGAAGAAATTGAACTTCAACAAAATGGTGTAAACACAGA TGCAGATTTAATTGCTAACTCTCCTAGTTCAGATGAATGTGAATCTGATGAAGAGGATTCTTACATGATGAATGGTGGAA ATCTCGGTGTTTCTCAAGTTCAAAGCTGGCAATTCGTGGGTGATGAATTTGAACATAGTAACGGGATGCAAGGTTCAGAA AGTTCAAGTGACTGTGTATCTCAGAAGTCATTTTTTAATCAAGAGAAAGCTTCTTCCCAGCTGAAAAAAACAAATAGTGT TCAAGGGCTTCAAGAATGCAACCATACAAAGTTTAATGATTTGGATCTTGGCACTGATGATATGCACTATAAAAGAACAC TTTCCGTCATTTTCAAAACATCCAGTGCACTGGTAACGGCACCATGTTCTAATAGTGGTAATCACAAATCCAGTTTCAGG AGATGGAAGCGGCGAGGCCTAGTGGGTTATCAAAAGAGTAGATCTGGAACACCACAGAAAATGTTGAAGAAAATTATGTT TGATGTTCCTCTGATGCACGGTGGGGGTTATCTGAAATCAAATGATGGGAAAGAATTTGAAAATGGGGTTTTGAAATCAG AAGGACATGATATTGCTTTAGGCCACGAAAAAAGAGAAGCACTCGATGACAAGTTTCTTGTTCTCAGATCTTTAGTTCCC TCCATAAACAAGTTTGATAGGACATCTCTCCTCAGTGACACGGTAGATTACTTGAAAGAGCTCGAGAGAAGAGTTGAAGA GCTAGAATCCTGCAGGGAGTTTACAGAGTTTGAAACTATAGAGAAAAGGAAACACCCGGATATAGTAGAAAGGACTTCTG ATAATTACGGGTATAATGAAAATGCTAACAGTCCAAAGGCCGTATTAAACAAGAGAAAAGCTTGCGATATTGATGAAATA GACCCTGAGCTAGATTCTGTTTCACCTAAAGACAATGTAGCAACATATGTTACAGTCTGCGTGATCGAGAAAGAGGTTTT GGTTGAGATACGCTGTCCATGGAAAGATTGCTTACTCATCGAAATTATAGATGCAATAAGTAATCTCCATTTGGATGCTC ATTCAATTCAGTCAGCAGCAACTGAAGGCATCCTCACTCTAACCCTCAAATCTAAGTTCAAAGGAGCCGAAGTTGTATCA GCAGGAATGATCAAACAAGCAATTCAGAGAGTTATTGGTACCTGCTGA |