| Microexon ID | Gm_7:6467405-6467419:+ |
| Species | Glycine max | Coordinates | 7:6467405..6467419 |
| Microexon Cluster ID | MEP42 |
| Size | 15 |
| Phase | 0 |
| Pfam Domain Motif | bHLH-MYC_N |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,15,45 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GCWMAYKATGCMGAYAGYAAARTYTTYTCTCGMKCTHTKCTWGCMAAGAGTGCWTSWATTCAGACWGTGGTRTGYWTTCCYYWYMTRGRYGGYGTBRTTGARCTWGGY |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 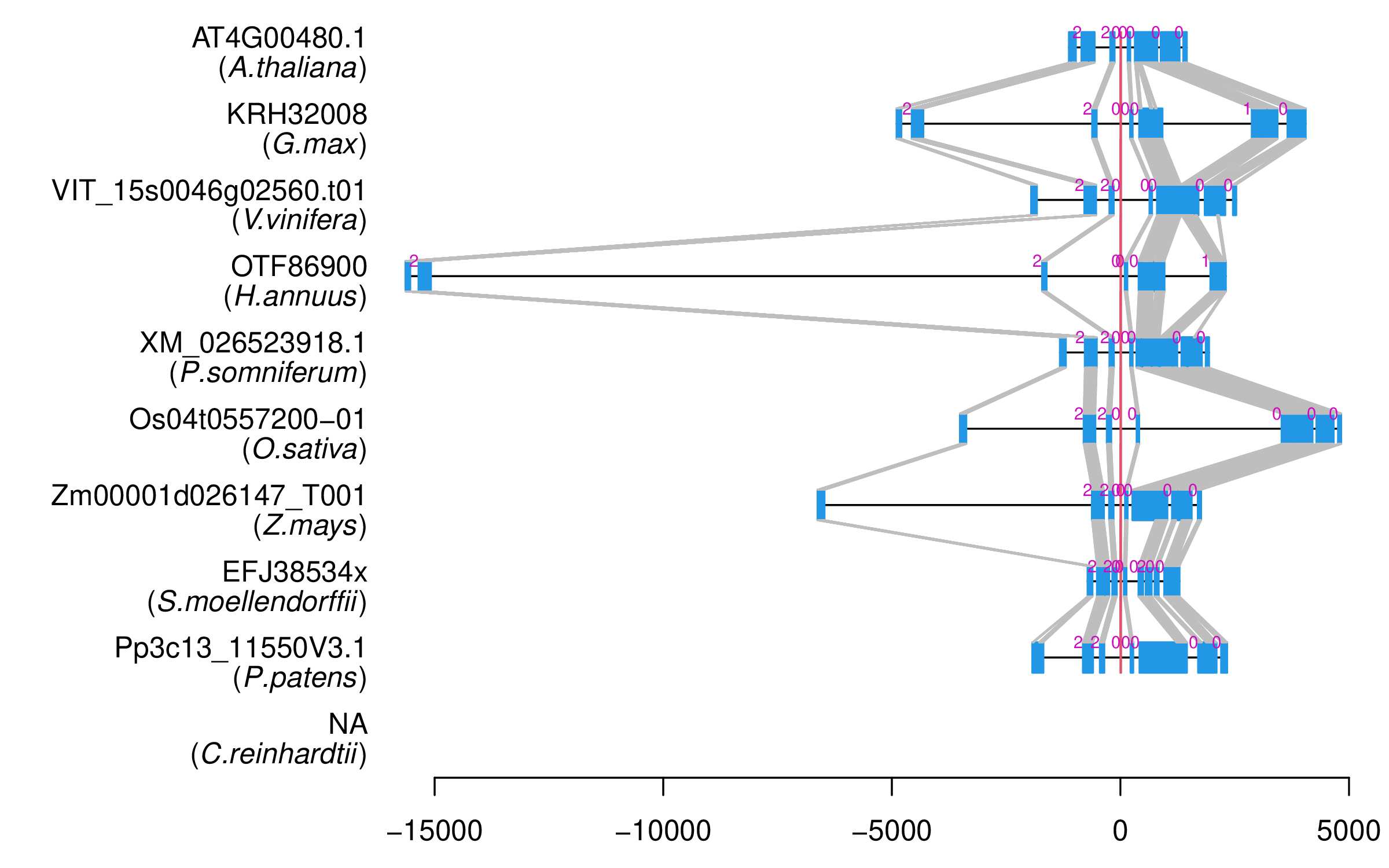 |
| Microexon DNA seq | AGTGCGTCAGTTCAG |
| Microexon Amino Acid seq | SASVQ |
| Microexon-tag DNA Seq | GCTCAACATGCTGATAGTAAAATTTTCTCTCGTTCTTTGCTAGCAAAGAGTGCGTCAGTTCAGACCGTGGTGTGTTTTCCCTATCAGAAAGGCGTTATTGAGATAGGC |
| Microexon-tag Amino Acid Seq | AQHADSKIFSRSLLAKSASVQTVVCFPYQKGVIEIG |
| Microexon-tag spanning region | 6465907-6467989 |
| Microexon-tag prediction score | 0.9493 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | KRH48144x |
| Reference Transcript ID | KRH48144 |
| Gene ID | GLYMA_07G071000 |
| Gene Name | NA |
| Transcript ID | KRH48144 |
| Protein ID | KRH48144 |
| Gene ID | GLYMA_07G071000 |
| Gene Name | NA |
| Pfam domain motif | bHLH-MYC_N |
| Motif E-value | 2.6e-48 |
| Motif start | 18 |
| Motif end | 201 |
| Protein seq | >KRH48144 MANNGSPKHKKMQKNLCTQLAVAVRSTQWSYGIFWAPSTTEERVLEWREGYYNGDIKTRKTVQAMELEMKADKIGLQRSE QLKELYKFLLAGEADPQTKRPSAALAPEDLSDLEWYYLVCMSFVFNHNQSLPGRALEIGDTVWLCNAQHADSKIFSRSLL AKSASVQTVVCFPYQKGVIEIGTTELVTEDPSLIQHVKACFLEISKPTCSDKSSSVLDKPHDDKYPTCTKGDQRVLEAMA LENPCSLEENIKFDHDPINELQDGNNEDSNMDSPDGCQHHFPMDGSMIEGINGVPSQVHFVNEALVIGAPDSLSSCDCMS EASENQGNDSKNVDQTQLMELQYCHKPKRSSMDVGADEDLCYIRTLCAILGNSSTFKPNPYAGNSNCKSSFAKWKKGRVS ERKRPKLHQSMLKKTLFNVPFMHRSYSSLKSQKENGRMKWTSKLENANDGFMEKTFSDKKRENKNFHVVKPMVPSSISEV EKISILGDTIKYLKKLETRVEELESYMEVTDPEARIRRKCPDVPEQMSDNYGTRKICMGMKPWVNKRKACGIDEIDTELE RIVSEESKVLDVKVNVKEQEVLIEMKCPYREYILYDIMDTINNLHLDAQTVESSTSDGVLTLTLKSKFRGAATAPTRMIK EALWKVSGNT* |
| CDS seq | >KRH48144 ATGGCCAACAACGGGAGTCCAAAGCATAAGAAGATGCAAAAGAACCTATGCACACAACTAGCTGTTGCAGTGAGAAGCAC TCAATGGAGCTATGGTATTTTCTGGGCACCTTCAACCACTGAAGAAAGGGTATTGGAATGGAGGGAAGGGTACTATAATG GAGACATTAAGACAAGAAAGACAGTCCAAGCCATGGAATTGGAAATGAAGGCTGATAAAATAGGACTGCAGAGGAGTGAG CAACTGAAGGAACTGTACAAGTTTCTTCTTGCAGGTGAAGCTGATCCACAAACTAAAAGGCCTTCTGCTGCATTAGCTCC AGAGGACCTCTCAGATTTGGAGTGGTATTACTTGGTTTGCATGTCCTTTGTTTTCAATCACAACCAAAGTTTGCCTGGAA GAGCACTAGAAATTGGTGACACTGTCTGGTTATGCAATGCTCAACATGCTGATAGTAAAATTTTCTCTCGTTCTTTGCTA GCAAAGAGTGCGTCAGTTCAGACCGTGGTGTGTTTTCCCTATCAGAAAGGCGTTATTGAGATAGGCACAACTGAACTGGT TACTGAGGATCCTAGTCTCATACAACATGTCAAGGCTTGCTTCTTAGAAATCTCAAAGCCTACATGCTCTGATAAATCTT CCTCTGTCCTTGATAAGCCACATGATGACAAATATCCAACATGCACCAAGGGTGACCAAAGGGTGTTAGAAGCAATGGCT CTGGAGAACCCATGTTCCCTTGAAGAAAATATCAAATTTGATCATGACCCCATCAATGAATTGCAAGATGGCAACAACGA AGATTCTAACATGGATTCTCCTGATGGTTGTCAGCATCATTTCCCTATGGATGGATCCATGATTGAGGGTATCAATGGTG TGCCATCTCAAGTTCATTTTGTGAATGAAGCCTTAGTCATTGGTGCTCCAGATTCTTTGAGTTCTTGTGATTGTATGTCT GAGGCTTCTGAGAACCAAGGCAATGATTCCAAGAATGTAGACCAAACTCAACTTATGGAACTTCAATATTGCCATAAACC AAAGAGAAGCTCCATGGATGTTGGAGCTGATGAGGACTTGTGCTACATAAGAACACTTTGTGCTATTTTGGGGAACTCAT CAACTTTTAAACCAAACCCTTATGCTGGTAACTCAAATTGCAAATCTAGTTTTGCGAAATGGAAGAAAGGGAGAGTTTCT GAAAGGAAGAGGCCAAAGTTGCACCAAAGCATGTTAAAGAAGACTTTGTTTAATGTCCCTTTTATGCATAGAAGTTACTC TTCTCTCAAGTCACAAAAAGAGAATGGCAGAATGAAATGGACTAGTAAATTGGAAAATGCTAATGATGGTTTCATGGAGA AAACATTCTCTGATAAGAAAAGAGAAAATAAAAACTTTCATGTTGTCAAACCAATGGTTCCATCTTCTATAAGTGAGGTA GAAAAAATTTCAATTCTTGGAGACACAATTAAGTACTTGAAAAAGCTTGAGACAAGAGTGGAAGAGCTAGAATCTTACAT GGAAGTTACAGACCCTGAAGCAAGAATCAGGAGAAAATGCCCTGATGTTCCAGAGCAGATGTCAGATAACTATGGCACCA GAAAGATTTGCATGGGAATGAAACCTTGGGTGAACAAGAGGAAGGCTTGTGGTATTGATGAGATAGACACAGAGCTAGAA AGAATTGTTTCTGAAGAATCAAAGGTTTTGGATGTGAAAGTCAATGTGAAGGAGCAGGAGGTTCTGATTGAGATGAAATG TCCTTACAGGGAATACATACTGTATGACATCATGGATACCATTAACAACCTACATTTAGATGCTCAAACAGTTGAATCAT CAACAAGTGATGGTGTTCTCACATTGACACTTAAATCTAAGTTTCGAGGAGCAGCAACAGCACCAACGAGGATGATCAAA GAAGCACTCTGGAAAGTATCTGGAAATACTTGA |
| Microexon DNA seq | AGTGCGTCAGTTCAG |
| Microexon Amino Acid seq | SASVQ |
| Microexon-tag DNA Seq | GCTCAACATGCTGATAGTAAAATTTTCTCTCGTTCTTTGCTAGCAAAGAGTGCGTCAGTTCAGACCGTGGTGTGTTTTCCCTATCAGAAAGGCGTTATTGAGATAGGC |
| Microexon-tag Amino Acid seq | AQHADSKIFSRSLLAKSASVQTVVCFPYQKGVIEIG |
| Transcript ID | KRH48144 |
| Gene ID | Gm.46192 |
| Gene Name | NA |
| Pfam domain motif | bHLH-MYC_N |
| Motif E-value | 2.7e-48 |
| Motif start | 18 |
| Motif end | 201 |
| Protein seq | >KRH48144 MANNGSPKHKKMQKNLCTQLAVAVRSTQWSYGIFWAPSTTEERVLEWREGYYNGDIKTRKTVQAMELEMKADKIGLQRSE QLKELYKFLLAGEADPQTKRPSAALAPEDLSDLEWYYLVCMSFVFNHNQSLPGRALEIGDTVWLCNAQHADSKIFSRSLL AKSASVQTVVCFPYQKGVIEIGTTELVTEDPSLIQHVKACFLEISKPTCSDKSSSVLDKPHDDKYPTCTKGDQRVLEAMA LENPCSLEENIKFDHDPINELQDGNNEDSNMDSPDGCQHHFPMDGSMIEGINGVPSQVHFVNEALVIGAPDSLSSCDCMS EASENQGNDSKNVDQTQLMELQYCHKPKRSSMDVGADEDLCYIRTLCAILGNSSTFKPNPYAGNSNCKSSFAKWKKGRVS ERKRPKLHQSMLKKTLFNVPFMHRSYSSLKSQKENGRMKWTSKLENANDGFMEKTFSDKKRENKNFHVVKPMVPSSISEV EKISILGDTIKYLKKLETRVEELESYMEVTDPEARIRRKCPDVPEQMSDNYGTRKICMGMKPWVNKRKACGIDEIDTELE RIVSEESKVLDVKVNVKEQEVLIEMKCPYREYILYDIMDTINNLHLDAQTVESSTSDGVLTLTLKSKFRGAATAPTRMIK EALWKVSGNT* |
| CDS seq | >KRH48144 ATGGCCAACAACGGGAGTCCAAAGCATAAGAAGATGCAAAAGAACCTATGCACACAACTAGCTGTTGCAGTGAGAAGCAC TCAATGGAGCTATGGTATTTTCTGGGCACCTTCAACCACTGAAGAAAGGGTATTGGAATGGAGGGAAGGGTACTATAATG GAGACATTAAGACAAGAAAGACAGTCCAAGCCATGGAATTGGAAATGAAGGCTGATAAAATAGGACTGCAGAGGAGTGAG CAACTGAAGGAACTGTACAAGTTTCTTCTTGCAGGTGAAGCTGATCCACAAACTAAAAGGCCTTCTGCTGCATTAGCTCC AGAGGACCTCTCAGATTTGGAGTGGTATTACTTGGTTTGCATGTCCTTTGTTTTCAATCACAACCAAAGTTTGCCTGGAA GAGCACTAGAAATTGGTGACACTGTCTGGTTATGCAATGCTCAACATGCTGATAGTAAAATTTTCTCTCGTTCTTTGCTA GCAAAGAGTGCGTCAGTTCAGACCGTGGTGTGTTTTCCCTATCAGAAAGGCGTTATTGAGATAGGCACAACTGAACTGGT TACTGAGGATCCTAGTCTCATACAACATGTCAAGGCTTGCTTCTTAGAAATCTCAAAGCCTACATGCTCTGATAAATCTT CCTCTGTCCTTGATAAGCCACATGATGACAAATATCCAACATGCACCAAGGGTGACCAAAGGGTGTTAGAAGCAATGGCT CTGGAGAACCCATGTTCCCTTGAAGAAAATATCAAATTTGATCATGACCCCATCAATGAATTGCAAGATGGCAACAACGA AGATTCTAACATGGATTCTCCTGATGGTTGTCAGCATCATTTCCCTATGGATGGATCCATGATTGAGGGTATCAATGGTG TGCCATCTCAAGTTCATTTTGTGAATGAAGCCTTAGTCATTGGTGCTCCAGATTCTTTGAGTTCTTGTGATTGTATGTCT GAGGCTTCTGAGAACCAAGGCAATGATTCCAAGAATGTAGACCAAACTCAACTTATGGAACTTCAATATTGCCATAAACC AAAGAGAAGCTCCATGGATGTTGGAGCTGATGAGGACTTGTGCTACATAAGAACACTTTGTGCTATTTTGGGGAACTCAT CAACTTTTAAACCAAACCCTTATGCTGGTAACTCAAATTGCAAATCTAGTTTTGCGAAATGGAAGAAAGGGAGAGTTTCT GAAAGGAAGAGGCCAAAGTTGCACCAAAGCATGTTAAAGAAGACTTTGTTTAATGTCCCTTTTATGCATAGAAGTTACTC TTCTCTCAAGTCACAAAAAGAGAATGGCAGAATGAAATGGACTAGTAAATTGGAAAATGCTAATGATGGTTTCATGGAGA AAACATTCTCTGATAAGAAAAGAGAAAATAAAAACTTTCATGTTGTCAAACCAATGGTTCCATCTTCTATAAGTGAGGTA GAAAAAATTTCAATTCTTGGAGACACAATTAAGTACTTGAAAAAGCTTGAGACAAGAGTGGAAGAGCTAGAATCTTACAT GGAAGTTACAGACCCTGAAGCAAGAATCAGGAGAAAATGCCCTGATGTTCCAGAGCAGATGTCAGATAACTATGGCACCA GAAAGATTTGCATGGGAATGAAACCTTGGGTGAACAAGAGGAAGGCTTGTGGTATTGATGAGATAGACACAGAGCTAGAA AGAATTGTTTCTGAAGAATCAAAGGTTTTGGATGTGAAAGTCAATGTGAAGGAGCAGGAGGTTCTGATTGAGATGAAATG TCCTTACAGGGAATACATACTGTATGACATCATGGATACCATTAACAACCTACATTTAGATGCTCAAACAGTTGAATCAT CAACAAGTGATGGTGTTCTCACATTGACACTTAAATCTAAGTTTCGAGGAGCAGCAACAGCACCAACGAGGATGATCAAA GAAGCACTCTGGAAAGTATCTGGAAATACTTGA |