| Microexon ID | Gm_10:2267543-2267557:+ |
| Species | Glycine max | Coordinates | 10:2267543..2267557 |
| Microexon Cluster ID | MEP42 |
| Size | 15 |
| Phase | 0 |
| Pfam Domain Motif | bHLH-MYC_N |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,15,45 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GCWMAYKATGCMGAYAGYAAARTYTTYTCTCGMKCTHTKCTWGCMAAGAGTGCWTSWATTCAGACWGTGGTRTGYWTTCCYYWYMTRGRYGGYGTBRTTGARCTWGGY |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 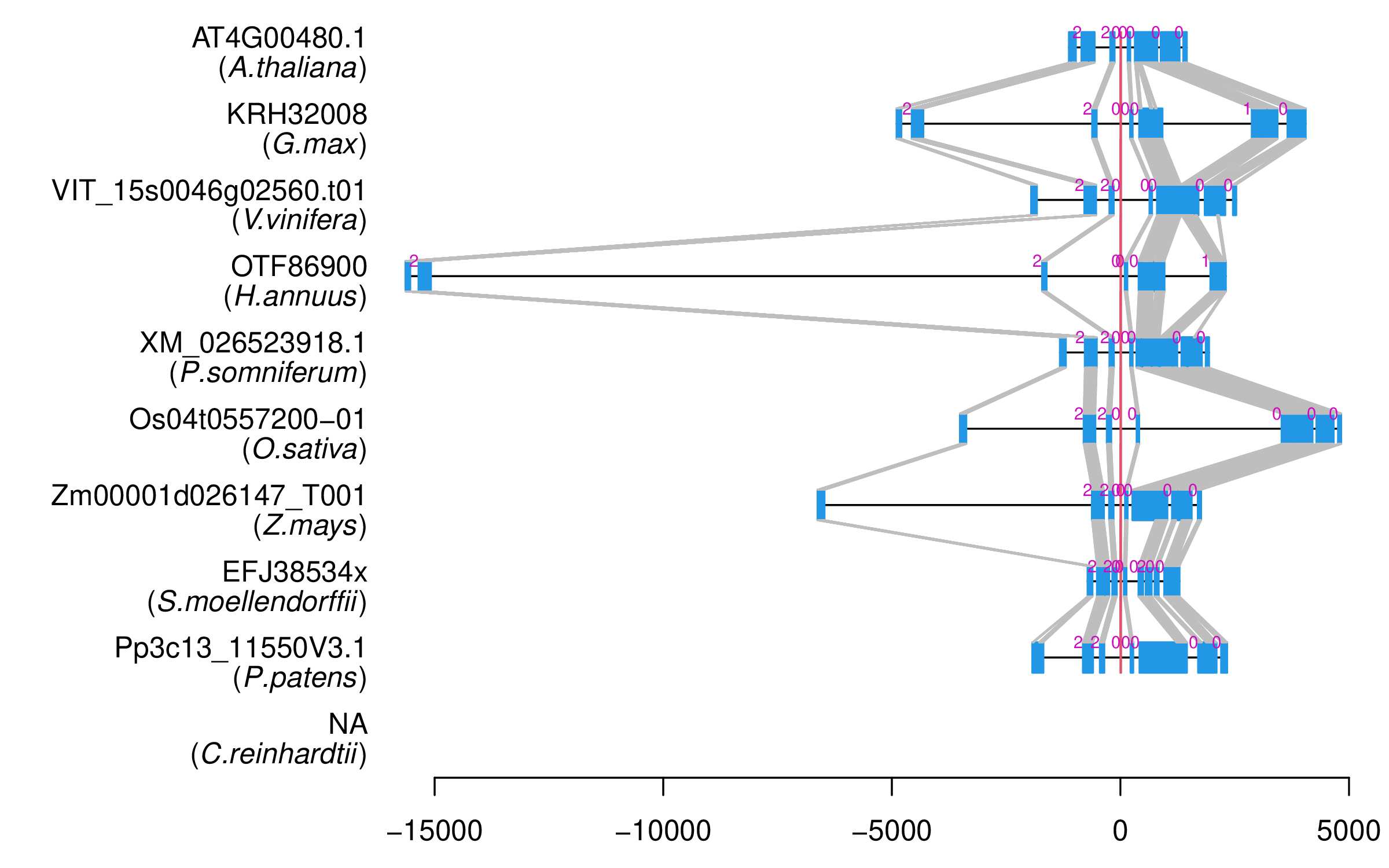 |
| Microexon DNA seq | AGTGCTCGCATACAG |
| Microexon Amino Acid seq | SARIQ |
| Microexon-tag DNA Seq | GCAAATGAGGTGGACAGCAAAACATTTTCACGAGCTATTCTAGCCAAGAGTGCTCGCATACAGACTGTGGTGTGCATTCCTTTATTGGACGGTGTGGTTGAGTTTGGC |
| Microexon-tag Amino Acid Seq | ANEVDSKTFSRAILAKSARIQTVVCIPLLDGVVEFG |
| Microexon-tag spanning region | 2266977-2267800 |
| Microexon-tag prediction score | 0.9547 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | KRH32008x |
| Reference Transcript ID | KRH32008 |
| Gene ID | GLYMA_10G026000 |
| Gene Name | NA |
| Transcript ID | KRH32008 |
| Protein ID | KRH32008 |
| Gene ID | GLYMA_10G026000 |
| Gene Name | NA |
| Pfam domain motif | bHLH-MYC_N |
| Motif E-value | 8.2e-52 |
| Motif start | 9 |
| Motif end | 191 |
| Protein seq | >KRH32008 MAAPLGTSLQSMLQAAVQSVQWTYSLFWQLCPQQGILVWGDGYYNGAIKTRKTVQPMEVSAEEASLQRSQQLRELYESLS AGETNPPCRRPCAALSPEDLTESEWFYLMCVSFSFPPGVGLPGKAYARRQHLWLTGANEVDSKTFSRAILAKSARIQTVV CIPLLDGVVEFGTMDKVQEDLSFIQHVETFFIDHLNPLPPKPALSEHSTSNPASSSEHIPAVMYTVVDPLAANPNLNDDM DEDIEEEEEEEEEDEEPESGSEDKAGYGIARQTPTPAMAAEPSELIQLEMPEDIRLGSPNDGSNNLDSDFHLLAVSQGVN TAGQAESTRRWGLSQNPMQVQLPTSALHPLEDLTQEDTHYSQTVSNILQNQFTRWPASPSSVGYVSYSTQSAFAKWSSRA SHHHFHPAAAAAADGTSQCILKYILFTVPYLHAKNPGESSPQTTAADTKLRGKGAPQEELSANHVLAERRRREKLNERFI ILRSLVPFVTKMDKASILGDTIEYVKQLRRKIQELEARNRQMTEAEQRSKLPEIAVQRTSSSSSKEQQRSGVTMTEKRKV RIVEGVVAKAKAVEAEATTSVQVSIIESDALLEIECRHKEGLLLDVMQMLREVRIEVIGVQSSLNNGVFVAELRAKVKEH ANGKKVSIVEVKRALNQIIPHAVD* |
| CDS seq | >KRH32008 ATGGCTGCGCCACTAGGCACTAGCCTTCAAAGCATGTTGCAGGCTGCGGTGCAATCTGTTCAGTGGACTTATAGTCTCTT CTGGCAACTTTGTCCACAACAAGGGATTCTGGTTTGGGGTGATGGTTACTACAATGGAGCAATTAAAACACGGAAGACGG TGCAACCAATGGAGGTGAGTGCTGAAGAGGCTTCTCTCCAAAGAAGCCAGCAACTTAGAGAACTCTATGAATCACTGTCC GCCGGAGAGACAAACCCGCCTTGTCGCCGGCCTTGTGCCGCCTTGTCGCCTGAGGACTTAACAGAATCCGAATGGTTCTA TTTGATGTGTGTCTCATTCTCCTTTCCACCTGGTGTTGGGTTGCCTGGAAAGGCATATGCGAGGAGGCAGCATCTATGGC TCACGGGTGCAAATGAGGTGGACAGCAAAACATTTTCACGAGCTATTCTAGCCAAGAGTGCTCGCATACAGACTGTGGTG TGCATTCCTTTATTGGACGGTGTGGTTGAGTTTGGCACAATGGATAAGGTTCAAGAAGACCTCAGCTTCATCCAACACGT GGAGACCTTCTTCATAGACCACCTCAACCCTTTGCCACCGAAGCCTGCCTTGTCGGAGCACTCAACCTCAAACCCCGCCT CCTCCTCTGAACACATCCCCGCCGTCATGTATACCGTCGTGGATCCACTTGCCGCCAATCCCAACCTAAATGATGACATG GATGAGGATATTGAGGAGGAAGAGGAGGAGGAAGAGGAAGATGAGGAGCCGGAATCTGGTTCCGAAGACAAAGCCGGATA CGGCATCGCTCGCCAAACTCCGACACCAGCCATGGCGGCAGAGCCCAGCGAGCTGATACAACTAGAGATGCCGGAGGACA TCCGGCTTGGGTCTCCAAACGATGGGTCAAACAACTTAGACTCAGATTTTCACTTGCTGGCGGTGAGTCAGGGTGTTAAC ACAGCGGGGCAGGCTGAGTCAACTCGGAGGTGGGGCCTGAGTCAAAACCCCATGCAAGTTCAACTACCGACTTCAGCCCT TCATCCATTGGAAGACTTGACACAAGAGGACACTCACTACTCTCAAACAGTGTCCAACATCCTCCAAAACCAGTTCACAC GGTGGCCAGCCTCACCCTCCTCCGTTGGATACGTCTCATACTCCACGCAATCAGCATTCGCAAAATGGAGCAGCCGCGCC AGCCACCACCACTTCCACCCGGCGGCGGCGGCGGCGGCGGACGGCACCAGCCAGTGCATCCTCAAGTACATCCTCTTCAC GGTCCCGTACCTCCACGCCAAGAACCCCGGCGAGAGTTCTCCCCAAACCACCGCCGCGGACACCAAACTCCGCGGCAAGG GAGCGCCGCAGGAGGAGCTCAGCGCCAACCACGTGCTGGCCGAGCGCCGCCGCCGCGAGAAGCTGAACGAGAGGTTCATA ATCCTGCGGTCGCTGGTCCCCTTCGTGACCAAAATGGACAAGGCGTCGATATTGGGAGACACCATCGAGTACGTGAAGCA GTTGCGGCGGAAGATCCAGGAGCTCGAGGCGCGTAACCGCCAGATGACGGAGGCGGAACAACGTTCCAAGCTCCCAGAGA TAGCAGTTCAGAGAACAAGTAGCAGTTCGAGCAAGGAGCAACAGAGGAGTGGGGTGACAATGACGGAGAAGAGGAAGGTG AGGATCGTGGAAGGGGTGGTGGCGAAGGCGAAGGCGGTGGAGGCTGAGGCCACCACGTCGGTGCAAGTTTCGATCATAGA AAGCGACGCACTGTTGGAGATCGAGTGTCGTCACAAAGAAGGGTTGCTTCTGGACGTGATGCAGATGCTGAGGGAGGTGA GGATAGAAGTTATAGGGGTGCAGTCGTCGCTTAACAATGGGGTGTTCGTGGCGGAGTTGAGGGCTAAGGTGAAGGAACAT GCAAACGGCAAGAAGGTCAGCATTGTGGAAGTGAAGAGGGCACTTAACCAAATTATACCCCATGCTGTTGACTAA |
| Microexon DNA seq | AGTGCTCGCATACAG |
| Microexon Amino Acid seq | SARIQ |
| Microexon-tag DNA Seq | GCAAATGAGGTGGACAGCAAAACATTTTCACGAGCTATTCTAGCCAAGAGTGCTCGCATACAGACTGTGGTGTGCATTCCTTTATTGGACGGTGTGGTTGAGTTTGGC |
| Microexon-tag Amino Acid seq | ANEVDSKTFSRAILAKSARIQTVVCIPLLDGVVEFG |
| Transcript ID | KRH32008 |
| Gene ID | Gm.2654 |
| Gene Name | NA |
| Pfam domain motif | bHLH-MYC_N |
| Motif E-value | 8.2e-52 |
| Motif start | 9 |
| Motif end | 191 |
| Protein seq | >KRH32008 MAAPLGTSLQSMLQAAVQSVQWTYSLFWQLCPQQGILVWGDGYYNGAIKTRKTVQPMEVSAEEASLQRSQQLRELYESLS AGETNPPCRRPCAALSPEDLTESEWFYLMCVSFSFPPGVGLPGKAYARRQHLWLTGANEVDSKTFSRAILAKSARIQTVV CIPLLDGVVEFGTMDKVQEDLSFIQHVETFFIDHLNPLPPKPALSEHSTSNPASSSEHIPAVMYTVVDPLAANPNLNDDM DEDIEEEEEEEEEDEEPESGSEDKAGYGIARQTPTPAMAAEPSELIQLEMPEDIRLGSPNDGSNNLDSDFHLLAVSQGVN TAGQAESTRRWGLSQNPMQVQLPTSALHPLEDLTQEDTHYSQTVSNILQNQFTRWPASPSSVGYVSYSTQSAFAKWSSRA SHHHFHPAAAAAADGTSQCILKYILFTVPYLHAKNPGESSPQTTAADTKLRGKGAPQEELSANHVLAERRRREKLNERFI ILRSLVPFVTKMDKASILGDTIEYVKQLRRKIQELEARNRQMTEAEQRSKLPEIAVQRTSSSSSKEQQRSGVTMTEKRKV RIVEGVVAKAKAVEAEATTSVQVSIIESDALLEIECRHKEGLLLDVMQMLREVRIEVIGVQSSLNNGVFVAELRAKVKEH ANGKKVSIVEVKRALNQIIPHAVD* |
| CDS seq | >KRH32008 ATGGCTGCGCCACTAGGCACTAGCCTTCAAAGCATGTTGCAGGCTGCGGTGCAATCTGTTCAGTGGACTTATAGTCTCTT CTGGCAACTTTGTCCACAACAAGGGATTCTGGTTTGGGGTGATGGTTACTACAATGGAGCAATTAAAACACGGAAGACGG TGCAACCAATGGAGGTGAGTGCTGAAGAGGCTTCTCTCCAAAGAAGCCAGCAACTTAGAGAACTCTATGAATCACTGTCC GCCGGAGAGACAAACCCGCCTTGTCGCCGGCCTTGTGCCGCCTTGTCGCCTGAGGACTTAACAGAATCCGAATGGTTCTA TTTGATGTGTGTCTCATTCTCCTTTCCACCTGGTGTTGGGTTGCCTGGAAAGGCATATGCGAGGAGGCAGCATCTATGGC TCACGGGTGCAAATGAGGTGGACAGCAAAACATTTTCACGAGCTATTCTAGCCAAGAGTGCTCGCATACAGACTGTGGTG TGCATTCCTTTATTGGACGGTGTGGTTGAGTTTGGCACAATGGATAAGGTTCAAGAAGACCTCAGCTTCATCCAACACGT GGAGACCTTCTTCATAGACCACCTCAACCCTTTGCCACCGAAGCCTGCCTTGTCGGAGCACTCAACCTCAAACCCCGCCT CCTCCTCTGAACACATCCCCGCCGTCATGTATACCGTCGTGGATCCACTTGCCGCCAATCCCAACCTAAATGATGACATG GATGAGGATATTGAGGAGGAAGAGGAGGAGGAAGAGGAAGATGAGGAGCCGGAATCTGGTTCCGAAGACAAAGCCGGATA CGGCATCGCTCGCCAAACTCCGACACCAGCCATGGCGGCAGAGCCCAGCGAGCTGATACAACTAGAGATGCCGGAGGACA TCCGGCTTGGGTCTCCAAACGATGGGTCAAACAACTTAGACTCAGATTTTCACTTGCTGGCGGTGAGTCAGGGTGTTAAC ACAGCGGGGCAGGCTGAGTCAACTCGGAGGTGGGGCCTGAGTCAAAACCCCATGCAAGTTCAACTACCGACTTCAGCCCT TCATCCATTGGAAGACTTGACACAAGAGGACACTCACTACTCTCAAACAGTGTCCAACATCCTCCAAAACCAGTTCACAC GGTGGCCAGCCTCACCCTCCTCCGTTGGATACGTCTCATACTCCACGCAATCAGCATTCGCAAAATGGAGCAGCCGCGCC AGCCACCACCACTTCCACCCGGCGGCGGCGGCGGCGGCGGACGGCACCAGCCAGTGCATCCTCAAGTACATCCTCTTCAC GGTCCCGTACCTCCACGCCAAGAACCCCGGCGAGAGTTCTCCCCAAACCACCGCCGCGGACACCAAACTCCGCGGCAAGG GAGCGCCGCAGGAGGAGCTCAGCGCCAACCACGTGCTGGCCGAGCGCCGCCGCCGCGAGAAGCTGAACGAGAGGTTCATA ATCCTGCGGTCGCTGGTCCCCTTCGTGACCAAAATGGACAAGGCGTCGATATTGGGAGACACCATCGAGTACGTGAAGCA GTTGCGGCGGAAGATCCAGGAGCTCGAGGCGCGTAACCGCCAGATGACGGAGGCGGAACAACGTTCCAAGCTCCCAGAGA TAGCAGTTCAGAGAACAAGTAGCAGTTCGAGCAAGGAGCAACAGAGGAGTGGGGTGACAATGACGGAGAAGAGGAAGGTG AGGATCGTGGAAGGGGTGGTGGCGAAGGCGAAGGCGGTGGAGGCTGAGGCCACCACGTCGGTGCAAGTTTCGATCATAGA AAGCGACGCACTGTTGGAGATCGAGTGTCGTCACAAAGAAGGGTTGCTTCTGGACGTGATGCAGATGCTGAGGGAGGTGA GGATAGAAGTTATAGGGGTGCAGTCGTCGCTTAACAATGGGGTGTTCGTGGCGGAGTTGAGGGCTAAGGTGAAGGAACAT GCAAACGGCAAGAAGGTCAGCATTGTGGAAGTGAAGAGGGCACTTAACCAAATTATACCCCATGCTGTTGACTAA |