| Microexon ID | At_4:218545-218559:- |
| Species | Arabidopsis thaliana | Coordinates | 4:218545..218559 |
| Microexon Cluster ID | MEP42 |
| Size | 15 |
| Phase | 0 |
| Pfam Domain Motif | bHLH-MYC_N |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,15,45 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GCWMAYKATGCMGAYAGYAAARTYTTYTCTCGMKCTHTKCTWGCMAAGAGTGCWTSWATTCAGACWGTGGTRTGYWTTCCYYWYMTRGRYGGYGTBRTTGARCTWGGY |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 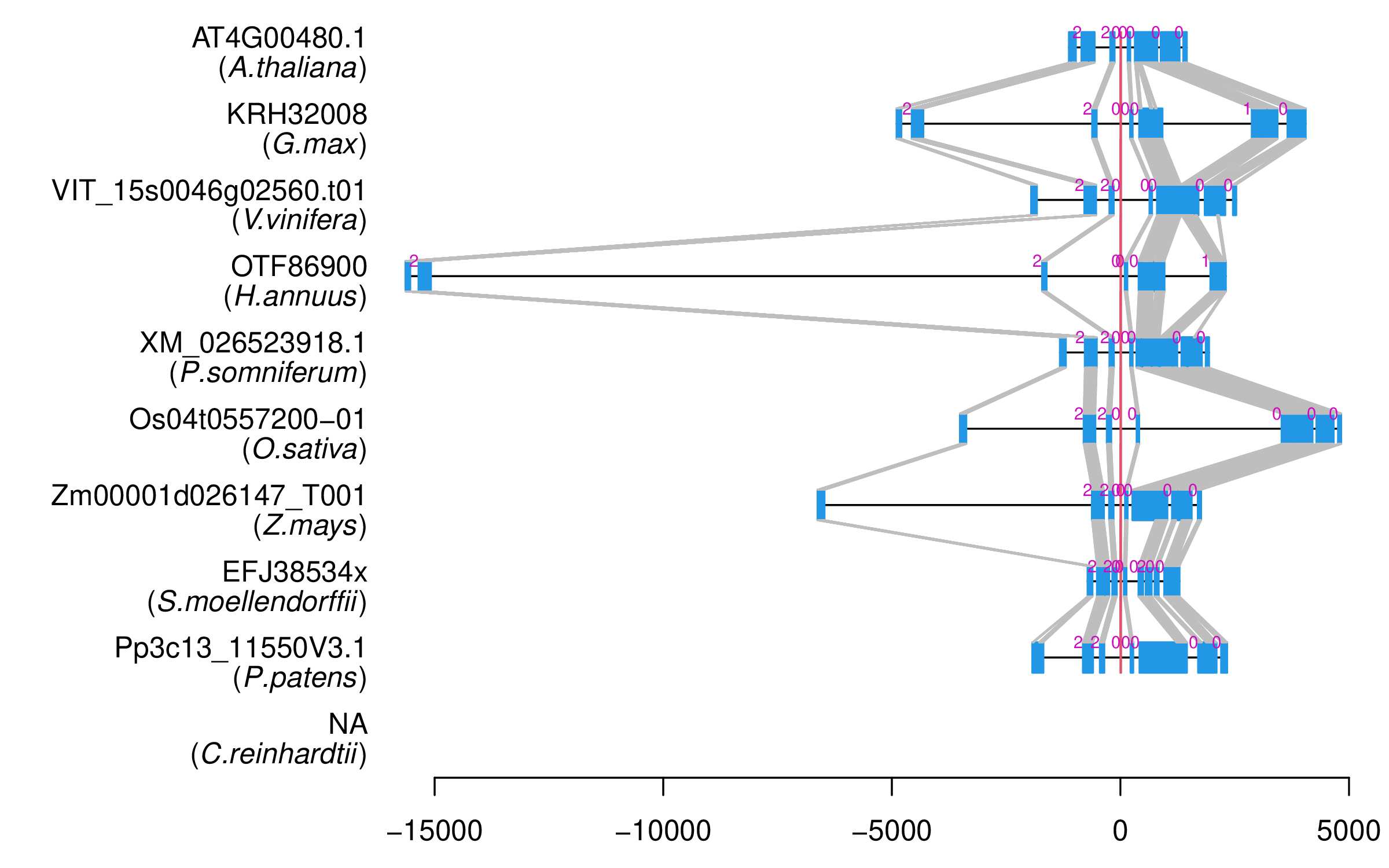 |
| Microexon DNA seq | AGCGCATCAATTCAG |
| Microexon Amino Acid seq | SASIQ |
| Microexon-tag DNA Seq | GCTCAATATGCGGAGAACAAGCTCTTCTCTCGTTCTTTGTTAGCAAGAAGCGCATCAATTCAGACTGTTGTGTGTTTCCCTTACTTGGGCGGAGTCATTGAGCTGGGC |
| Microexon-tag Amino Acid Seq | AQYAENKLFSRSLLARSASIQTVVCFPYLGGVIELG |
| Microexon-tag spanning region | 218356-218732 |
| Microexon-tag prediction score | 0.9339 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | AT4G00480.1x |
| Reference Transcript ID | AT4G00480.1 |
| Gene ID | AT4G00480 |
| Gene Name | ATMYC1 |
| Transcript ID | AT4G00480.1 |
| Protein ID | AT4G00480.1 |
| Gene ID | AT4G00480 |
| Gene Name | ATMYC1 |
| Pfam domain motif | bHLH-MYC_N |
| Motif E-value | 9.9e-50 |
| Motif start | 23 |
| Motif end | 216 |
| Protein seq | >AT4G00480.1 MSLTMADGVEAAAGRSKRQNSLLRKQLALAVRSVQWSYAIFWSSSLTQPGVLEWGEGCYNGDMKKRKKSYESHYKYGLQK SKELRKLYLSMLEGDSGTTVSTTHDNLNDDDDNCHSTSMMLSPDDLSDEEWYYLVSMSYVFSPSQCLPGRASATGETIWL CNAQYAENKLFSRSLLARSASIQTVVCFPYLGGVIELGVTELISEDHNLLRNIKSCLMEISAHQDNDDEKKMEIKISEEK HQLPLGISDEDLHYKRTISTVLNYSADRSGKNDKNIRHRQPNIVTSEPGSSFLRWKQCEQQVSGFVQKKKSQNVLRKILH DVPLMHTKRMFPSQNSGLNQDDPSDRRKENEKFSVLRTMVPTVNEVDKESILNNTIKYLQELEARVEELESCMGSVNFVE RQRKTTENLNDSVLIEETSGNYDDSTKIDDNSGETEQVTVFRDKTHLRVKLKETEVVIEVRCSYRDYIVADIMETLSNLH MDAFSVRSHTLNKFLTLNLKAKFRGAAVASVGMIKRELRRVIGDLF* |
| CDS seq | >AT4G00480.1 ATGTCTTTGACAATGGCTGATGGTGTAGAAGCTGCAGCAGGAAGAAGTAAAAGACAAAACAGCTTATTAAGAAAACAACT TGCTTTAGCTGTAAGAAGTGTTCAATGGAGCTACGCAATCTTCTGGTCGTCTTCACTTACTCAACCTGGGGTTTTGGAGT GGGGAGAAGGATGTTACAATGGAGATATGAAGAAGAGGAAGAAGAGTTATGAATCTCATTATAAATATGGGTTGCAAAAA AGCAAGGAGCTTCGGAAACTTTATTTGTCTATGCTTGAAGGAGACAGTGGTACTACTGTTAGTACTACTCATGATAATCT CAATGATGATGATGATAATTGTCACAGTACAAGTATGATGCTGTCACCAGATGACCTCTCTGATGAAGAGTGGTACTATT TAGTCTCCATGTCCTATGTCTTCTCTCCTTCACAATGTTTGCCTGGAAGAGCTTCAGCGACGGGTGAGACCATATGGCTC TGCAACGCTCAATATGCGGAGAACAAGCTCTTCTCTCGTTCTTTGTTAGCAAGAAGCGCATCAATTCAGACTGTTGTGTG TTTCCCTTACTTGGGCGGAGTCATTGAGCTGGGCGTCACTGAATTGATTTCAGAAGACCATAACCTGCTTCGAAACATCA AATCTTGCTTGATGGAAATATCTGCACACCAAGACAACGATGACGAGAAGAAGATGGAGATTAAGATCAGTGAAGAGAAG CATCAGCTTCCATTAGGTATTTCTGATGAAGACTTGCATTACAAAAGAACCATTTCAACAGTACTCAACTACTCCGCAGA TAGATCAGGTAAGAACGATAAGAACATTCGTCATCGTCAGCCAAATATTGTTACTTCTGAACCTGGCTCAAGTTTCTTGC GGTGGAAGCAATGTGAGCAGCAAGTCTCGGGTTTTGTTCAGAAAAAAAAGTCACAGAATGTGTTGCGGAAGATATTGCAT GATGTCCCTTTGATGCACACAAAGAGAATGTTCCCAAGTCAGAACTCTGGTCTGAATCAAGATGATCCTTCAGATAGAAG AAAAGAGAACGAAAAGTTCAGTGTCCTTAGAACTATGGTTCCCACTGTCAACGAGGTTGATAAAGAATCGATACTAAACA ACACAATCAAGTACCTGCAAGAACTGGAGGCAAGAGTAGAAGAGCTAGAATCTTGTATGGGATCAGTTAATTTTGTAGAA AGACAAAGAAAGACGACAGAGAACCTTAACGACTCTGTGTTGATCGAAGAGACATCAGGGAACTACGATGATAGCACGAA GATCGATGACAATTCAGGAGAAACCGAACAAGTCACTGTTTTCAGAGATAAGACACATTTGAGAGTTAAACTCAAAGAAA CAGAAGTTGTGATCGAAGTAAGATGTTCTTACAGAGACTACATAGTTGCGGACATCATGGAAACTCTGAGCAATCTTCAC ATGGATGCTTTCTCTGTTAGATCTCACACGCTCAATAAGTTCCTCACATTGAATCTCAAGGCCAAGTTTCGCGGGGCTGC AGTTGCGTCCGTAGGAATGATTAAGCGAGAGCTGAGAAGAGTCATTGGTGATTTGTTTTAA |
| Microexon DNA seq | AGCGCATCAATTCAG |
| Microexon Amino Acid seq | SASIQ |
| Microexon-tag DNA Seq | GCTCAATATGCGGAGAACAAGCTCTTCTCTCGTTCTTTGTTAGCAAGAAGCGCATCAATTCAGACTGTTGTGTGTTTCCCTTACTTGGGCGGAGTCATTGAGCTGGGC |
| Microexon-tag Amino Acid seq | AQYAENKLFSRSLLARSASIQTVVCFPYLGGVIELG |
| Transcript ID | AT4G00480.2 |
| Gene ID | At.17503 |
| Gene Name | ATMYC1 |
| Pfam domain motif | bHLH-MYC_N |
| Motif E-value | 1.2e-49 |
| Motif start | 23 |
| Motif end | 216 |
| Protein seq | >AT4G00480.2 MSLTMADGVEAAAGRSKRQNSLLRKQLALAVRSVQWSYAIFWSSSLTQPGVLEWGEGCYNGDMKKRKKSYESHYKYGLQK SKELRKLYLSMLEGDSGTTVSTTHDNLNDDDDNCHSTSMMLSPDDLSDEEWYYLVSMSYVFSPSQCLPGRASATGETIWL CNAQYAENKLFSRSLLARSASIQTVVCFPYLGGVIELGVTELISEDHNLLRNIKSCLMEISAHQDNDDEKKMEIKISEEK HQLPLGISDEDLHYKRTISTVLNYSADRSGKNDKNIRHRQPNIVTSEPGSSFLRWKQCEQQVSGFVQKKKSQNVLRKILH DVPLMHTKRMFPSQNSGLNQDDPSDRRKENEKFSVLRTMVPTVNEVDKESILNNTIKYLQELEARVEELESCMGSVNFVE RQRKTTENLNDSVLIEETSGNYDDSTKIDDNSGETEQVTVFRDKTHLRVKLKETEVVIEVRCSYRDYIVADIMETLSNLH MDAFSVRSHTLNKFLTLNLKAKFRGAAVASVGMIKRELRRVIDFREPICDVPLSLHQVFRVFVCKVCQSLVGIFDNVVSS SSTKPRSILIHNSWAICIFH* |
| CDS seq | >AT4G00480.2 ATGTCTTTGACAATGGCTGATGGTGTAGAAGCTGCAGCAGGAAGAAGTAAAAGACAAAACAGCTTATTAAGAAAACAACT TGCTTTAGCTGTAAGAAGTGTTCAATGGAGCTACGCAATCTTCTGGTCGTCTTCACTTACTCAACCTGGGGTTTTGGAGT GGGGAGAAGGATGTTACAATGGAGATATGAAGAAGAGGAAGAAGAGTTATGAATCTCATTATAAATATGGGTTGCAAAAA AGCAAGGAGCTTCGGAAACTTTATTTGTCTATGCTTGAAGGAGACAGTGGTACTACTGTTAGTACTACTCATGATAATCT CAATGATGATGATGATAATTGTCACAGTACAAGTATGATGCTGTCACCAGATGACCTCTCTGATGAAGAGTGGTACTATT TAGTCTCCATGTCCTATGTCTTCTCTCCTTCACAATGTTTGCCTGGAAGAGCTTCAGCGACGGGTGAGACCATATGGCTC TGCAACGCTCAATATGCGGAGAACAAGCTCTTCTCTCGTTCTTTGTTAGCAAGAAGCGCATCAATTCAGACTGTTGTGTG TTTCCCTTACTTGGGCGGAGTCATTGAGCTGGGCGTCACTGAATTGATTTCAGAAGACCATAACCTGCTTCGAAACATCA AATCTTGCTTGATGGAAATATCTGCACACCAAGACAACGATGACGAGAAGAAGATGGAGATTAAGATCAGTGAAGAGAAG CATCAGCTTCCATTAGGTATTTCTGATGAAGACTTGCATTACAAAAGAACCATTTCAACAGTACTCAACTACTCCGCAGA TAGATCAGGTAAGAACGATAAGAACATTCGTCATCGTCAGCCAAATATTGTTACTTCTGAACCTGGCTCAAGTTTCTTGC GGTGGAAGCAATGTGAGCAGCAAGTCTCGGGTTTTGTTCAGAAAAAAAAGTCACAGAATGTGTTGCGGAAGATATTGCAT GATGTCCCTTTGATGCACACAAAGAGAATGTTCCCAAGTCAGAACTCTGGTCTGAATCAAGATGATCCTTCAGATAGAAG AAAAGAGAACGAAAAGTTCAGTGTCCTTAGAACTATGGTTCCCACTGTCAACGAGGTTGATAAAGAATCGATACTAAACA ACACAATCAAGTACCTGCAAGAACTGGAGGCAAGAGTAGAAGAGCTAGAATCTTGTATGGGATCAGTTAATTTTGTAGAA AGACAAAGAAAGACGACAGAGAACCTTAACGACTCTGTGTTGATCGAAGAGACATCAGGGAACTACGATGATAGCACGAA GATCGATGACAATTCAGGAGAAACCGAACAAGTCACTGTTTTCAGAGATAAGACACATTTGAGAGTTAAACTCAAAGAAA CAGAAGTTGTGATCGAAGTAAGATGTTCTTACAGAGACTACATAGTTGCGGACATCATGGAAACTCTGAGCAATCTTCAC ATGGATGCTTTCTCTGTTAGATCTCACACGCTCAATAAGTTCCTCACATTGAATCTCAAGGCCAAGTTTCGCGGGGCTGC AGTTGCGTCCGTAGGAATGATTAAGCGAGAGCTGAGAAGAGTCATTGACTTTCGTGAACCGATATGCGATGTGCCATTAT CTTTACATCAAGTTTTCAGGGTTTTTGTATGTAAAGTTTGCCAAAGTTTGGTTGGAATTTTCGACAACGTTGTCTCTTCC TCTTCTACAAAACCAAGATCTATACTTATTCATAATTCATGGGCGATTTGTATCTTTCATTAA |