| Microexon ID | Ps_NC_039364.1:123153596-123153609:- |
| Species | Papaver somniferum | Coordinates | NC_039364.1:123153596..123153609 |
| Microexon Cluster ID | MEP40 |
| Size | 14 |
| Phase | 1 |
| Pfam Domain Motif | SBP_bac_10 |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 46,14,48 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GTYATCCCMYTRKCMAACTWYTCHRTBGAYRCCRMTTATTTTCCAGTKTCMTTCTTYGAGCTTYTAGGWYTRCTRGVRARCWTGAARGGCATMACATCAGAMWMRGTR |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 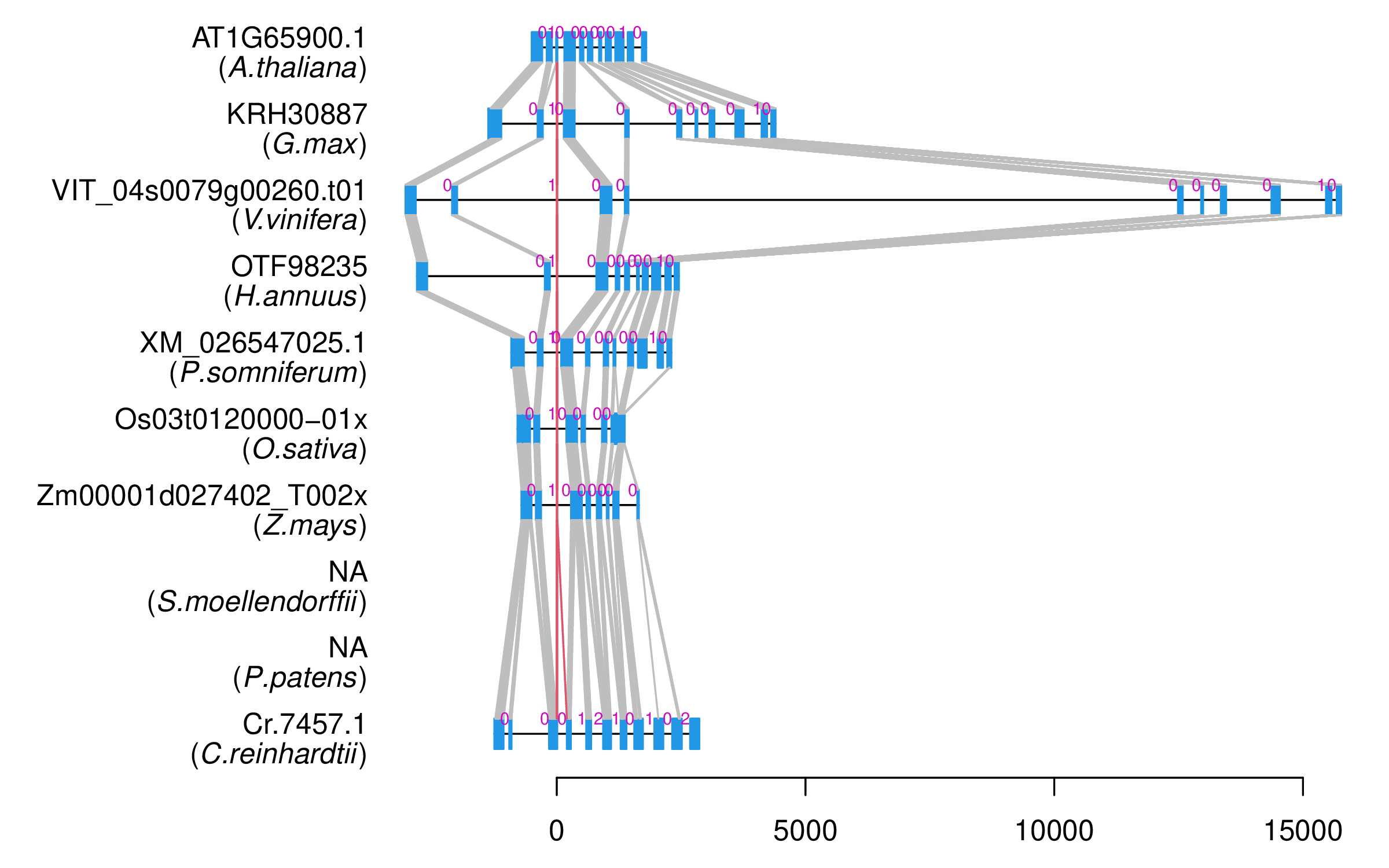 |
| Microexon DNA seq | TGTCCTTCTTTGAG |
| Microexon Amino Acid seq | VSFFE |
| Microexon-tag DNA Seq | GTAGTACCCCTATCAAACTACTCTATCAACACAGACTACTTTCCAGTGTCCTTCTTTGAGCTTCTAGGATTGGGGGGAAGTTTGAAGGGAATTACATCAGATTTAGTT |
| Microexon-tag Amino Acid Seq | VVPLSNYSINTDYFPVSFFELLGLGGSLKGITSDLV |
| Microexon-tag spanning region | 123153473-123153938 |
| Microexon-tag prediction score | 0.9357 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026547025.1x |
| Reference Transcript ID | XM_026547025.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026547025.1 |
| Protein ID | XP_026402810.1 |
| Gene ID | LOC113298318 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026402810.1 MSSDTGAYINSLQLLFSLWCFTNGVLYSIFLCGSCIRVVNAAAKSVNVGSNVSVVQDAKYFHIYYGQNFKVIKNGIDGKN YLLIQNNSRMATRTKYCTGRIKSFVVPLSNYSINTDYFPVSFFELLGLGGSLKGITSDLVASECVLKSYMDGGIQMINKT DVVKDTTQFTAYFVTNPDKMEACNFATFLPVDEDTPLQRAEWIKYLGAFANLEDRANHVYEAVKTNYMCLTKAAENNRKA FKPVVAWLRFNEGVWSFTNDAYKMKYVLDAGGENIDDSMNKNTYDTSIPDDMDDFHAILCTVDVVIDETYTSHPVEYKLS TFLKNLKVNEDEAQSDGFGFLTKQSLWRYDKRIQNSDSLDWLNNAVSQPHLVLADLLEAFFPTGNYTTTYLRNLAKDEKV TTIDPQMCSREISTAMEPIKVPC* |
| CDS seq | >XM_026547025.1 ATGTCTTCTGATACGGGAGCTTACATTAATTCTCTTCAGTTACTCTTTAGCCTCTGGTGCTTTACTAATGGCGTTCTCTA TTCGATTTTCTTGTGTGGGAGTTGTATAAGGGTTGTGAATGCAGCAGCAAAATCTGTAAATGTTGGAAGTAATGTTTCAG TGGTTCAAGATGCGAAGTACTTCCATATATATTATGGTCAGAACTTCAAAGTTATCAAAAATGGTATTGATGGCAAGAAT TACCTTCTCATTCAGAATAATTCGAGAATGGCGACGAGAACAAAATATTGCACAGGAAGAATCAAATCATTTGTAGTACC CCTATCAAACTACTCTATCAACACAGACTACTTTCCAGTGTCCTTCTTTGAGCTTCTAGGATTGGGGGGAAGTTTGAAGG GAATTACATCAGATTTAGTTGCCTCGGAATGTGTCTTGAAATCGTACATGGATGGTGGTATCCAAATGATCAACAAAACT GATGTAGTGAAAGATACTACTCAATTCACTGCTTATTTTGTTACCAACCCGGATAAAATGGAAGCTTGTAATTTTGCTAC CTTCCTTCCGGTCGACGAGGATACTCCTCTCCAGCGAGCAGAATGGATCAAGTACTTGGGTGCTTTCGCGAATTTGGAAG ATAGAGCAAATCACGTATACGAGGCAGTGAAAACAAATTACATGTGTTTGACAAAAGCGGCAGAGAATAACAGAAAAGCA TTCAAACCTGTGGTAGCATGGCTAAGGTTTAATGAGGGAGTTTGGTCTTTCACCAATGATGCATACAAGATGAAGTATGT GTTAGATGCAGGTGGGGAAAACATTGACGACTCGATGAACAAAAATACCTATGACACTTCAATCCCGGATGACATGGACG ACTTCCATGCTATCCTATGTACTGTTGACGTTGTCATTGATGAAACTTACACTTCACACCCTGTCGAATACAAGCTTTCC ACATTCTTGAAAAACTTAAAAGTGAATGAAGATGAAGCACAGTCTGATGGTTTTGGCTTCCTTACGAAACAAAGCTTATG GAGATATGATAAAAGGATCCAAAATTCCGATTCTCTAGATTGGTTAAACAATGCTGTCTCTCAGCCTCATCTTGTTCTGG CAGATTTATTAGAGGCATTTTTTCCTACGGGAAATTACACGACAACTTACTTAAGAAACCTTGCGAAGGATGAAAAAGTT ACTACCATTGATCCTCAGATGTGCAGTAGAGAGATTTCCACAGCAATGGAACCCATCAAGGTTCCTTGTTAG |
| Microexon DNA seq | TGTCCTTCTTTGAG |
| Microexon Amino Acid seq | VSFFE |
| Microexon-tag DNA Seq | GTAGTACCCCTATCAAACTACTCTATCAACACAGACTACTTTCCAGTGTCCTTCTTTGAGCTTCTAGGATTGGGGGGAAGTTTGAAGGGAATTACATCAGATTTAGTT |
| Microexon-tag Amino Acid seq | VVPLSNYSINTDYFPVSFFELLGLGGSLKGITSDLV |
| Transcript ID | XM_026547025.1 |
| Gene ID | Ps.43553 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026547025.1 MSSDTGAYINSLQLLFSLWCFTNGVLYSIFLCGSCIRVVNAAAKSVNVGSNVSVVQDAKYFHIYYGQNFKVIKNGIDGKN YLLIQNNSRMATRTKYCTGRIKSFVVPLSNYSINTDYFPVSFFELLGLGGSLKGITSDLVASECVLKSYMDGGIQMINKT DVVKDTTQFTAYFVTNPDKMEACNFATFLPVDEDTPLQRAEWIKYLGAFANLEDRANHVYEAVKTNYMCLTKAAENNRKA FKPVVAWLRFNEGVWSFTNDAYKMKYVLDAGGENIDDSMNKNTYDTSIPDDMDDFHAILCTVDVVIDETYTSHPVEYKLS TFLKNLKVNEDEAQSDGFGFLTKQSLWRYDKRIQNSDSLDWLNNAVSQPHLVLADLLEAFFPTGNYTTTYLRNLAKDEKV TTIDPQMCSREISTAMEPIKVPC* |
| CDS seq | >XM_026547025.1 ATGTCTTCTGATACGGGAGCTTACATTAATTCTCTTCAGTTACTCTTTAGCCTCTGGTGCTTTACTAATGGCGTTCTCTA TTCGATTTTCTTGTGTGGGAGTTGTATAAGGGTTGTGAATGCAGCAGCAAAATCTGTAAATGTTGGAAGTAATGTTTCAG TGGTTCAAGATGCGAAGTACTTCCATATATATTATGGTCAGAACTTCAAAGTTATCAAAAATGGTATTGATGGCAAGAAT TACCTTCTCATTCAGAATAATTCGAGAATGGCGACGAGAACAAAATATTGCACAGGAAGAATCAAATCATTTGTAGTACC CCTATCAAACTACTCTATCAACACAGACTACTTTCCAGTGTCCTTCTTTGAGCTTCTAGGATTGGGGGGAAGTTTGAAGG GAATTACATCAGATTTAGTTGCCTCGGAATGTGTCTTGAAATCGTACATGGATGGTGGTATCCAAATGATCAACAAAACT GATGTAGTGAAAGATACTACTCAATTCACTGCTTATTTTGTTACCAACCCGGATAAAATGGAAGCTTGTAATTTTGCTAC CTTCCTTCCGGTCGACGAGGATACTCCTCTCCAGCGAGCAGAATGGATCAAGTACTTGGGTGCTTTCGCGAATTTGGAAG ATAGAGCAAATCACGTATACGAGGCAGTGAAAACAAATTACATGTGTTTGACAAAAGCGGCAGAGAATAACAGAAAAGCA TTCAAACCTGTGGTAGCATGGCTAAGGTTTAATGAGGGAGTTTGGTCTTTCACCAATGATGCATACAAGATGAAGTATGT GTTAGATGCAGGTGGGGAAAACATTGACGACTCGATGAACAAAAATACCTATGACACTTCAATCCCGGATGACATGGACG ACTTCCATGCTATCCTATGTACTGTTGACGTTGTCATTGATGAAACTTACACTTCACACCCTGTCGAATACAAGCTTTCC ACATTCTTGAAAAACTTAAAAGTGAATGAAGATGAAGCACAGTCTGATGGTTTTGGCTTCCTTACGAAACAAAGCTTATG GAGATATGATAAAAGGATCCAAAATTCCGATTCTCTAGATTGGTTAAACAATGCTGTCTCTCAGCCTCATCTTGTTCTGG CAGATTTATTAGAGGCATTTTTTCCTACGGGAAATTACACGACAACTTACTTAAGAAACCTTGCGAAGGATGAAAAAGTT ACTACCATTGATCCTCAGATGTGCAGTAGAGAGATTTCCACAGCAATGGAACCCATCAAGGTTCCTTGTTAG |