| Microexon ID | Gm_11:30538431-30538444:+ |
| Species | Glycine max | Coordinates | 11:30538431..30538444 |
| Microexon Cluster ID | MEP40 |
| Size | 14 |
| Phase | 1 |
| Pfam Domain Motif | SBP_bac_10 |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 46,14,48 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GTYATCCCMYTRKCMAACTWYTCHRTBGAYRCCRMTTATTTTCCAGTKTCMTTCTTYGAGCTTYTAGGWYTRCTRGVRARCWTGAARGGCATMACATCAGAMWMRGTR |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 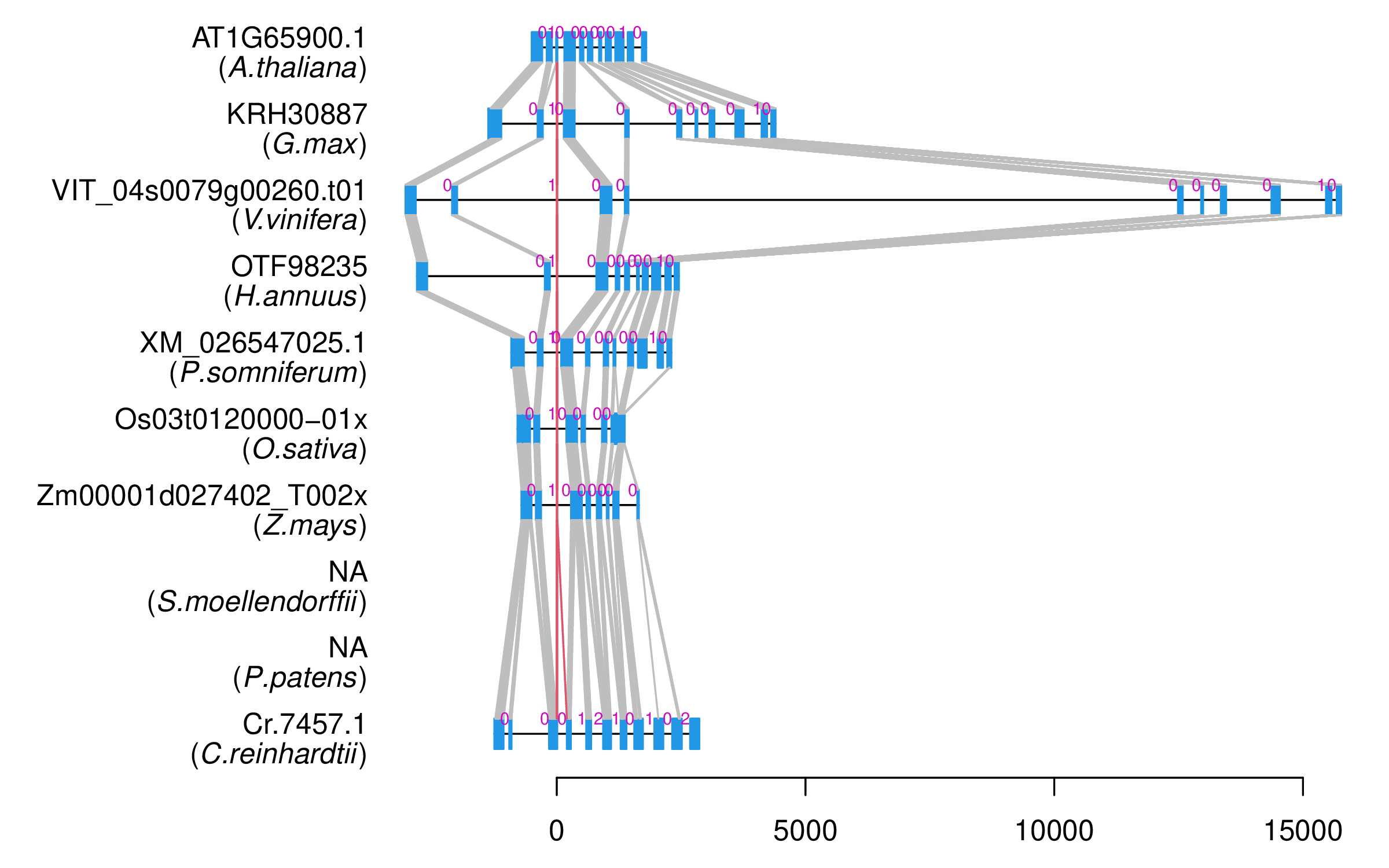 |
| Microexon DNA seq | TCTCCTTTGTAGAG |
| Microexon Amino Acid seq | VSFVE |
| Microexon-tag DNA Seq | GTCATTCCATTGTCAAACTATTCTGTTGATACAACTTTTTTTCCGGTCTCCTTTGTAGAGCTTTTAGGTTTAGTGGAGAGCTTGAAAGGCATAACCTCAGACTATGTG |
| Microexon-tag Amino Acid Seq | VIPLSNYSVDTTFFPVSFVELLGLVESLKGITSDYV |
| Microexon-tag spanning region | 30538104-30538618 |
| Microexon-tag prediction score | 0.9379 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | KRH30887x |
| Reference Transcript ID | KRH30887 |
| Gene ID | GLYMA_11G212500 |
| Gene Name | NA |
| Transcript ID | KRH30887 |
| Protein ID | KRH30887 |
| Gene ID | GLYMA_11G212500 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >KRH30887 MITLFLYSKRYLIQLMDSAPSSSWLQAFSFLALVWLFNCGCVHGASPAVKVGNFSKVEDAGNFHIYYGQTFKVIKNSADG QSYLLLQNNSRIASRTKYCTSRIKSFVIPLSNYSVDTTFFPVSFVELLGLVESLKGITSDYVASPCVLKLYQGGQLEMFN NSDYQKLAEFSSYFLSDTDQQPACNFATFVPFMEDTPLQRAEWIKFMGAFANVEARANQVYTAVKVNYLCLAKVATTRTT FKPTVAWMRYKNGLWSFTQEKYQLKYVQDAGGEILGANKNTYNVSDPDDLEEFHAILCTAEVVIDETLTSDPVNYTMSAF IQNLNVEDRSCFSFISNTSLWRYDKRVYNSVALDWYNGAVSQPQLALADLIEVLFPTGNYTMTYFRNIAKGEVPINIGPE MCDRDTSTAMEPTIVACG* |
| CDS seq | >KRH30887 ATGATCACATTATTTTTATATAGCAAGAGGTACCTCATTCAGCTCATGGATTCAGCTCCTTCTAGTTCTTGGCTGCAAGC CTTCTCCTTCTTAGCATTGGTTTGGTTATTTAACTGTGGATGTGTCCATGGAGCCTCCCCAGCAGTGAAAGTAGGTAACT TTTCAAAGGTGGAAGATGCTGGAAACTTCCACATCTACTATGGCCAGACCTTCAAAGTCATTAAGAATTCTGCTGATGGC CAGAGCTACCTTCTTCTCCAGAATAATTCAAGGATTGCATCAAGGACTAAATATTGCACATCAAGAATCAAATCATTTGT CATTCCATTGTCAAACTATTCTGTTGATACAACTTTTTTTCCGGTCTCCTTTGTAGAGCTTTTAGGTTTAGTGGAGAGCT TGAAAGGCATAACCTCAGACTATGTGGCTTCTCCATGTGTGTTGAAACTGTATCAAGGAGGACAGCTAGAAATGTTCAAT AATAGTGATTACCAAAAGCTTGCAGAGTTCTCTTCATACTTTCTTAGTGACACTGATCAGCAGCCAGCTTGCAATTTTGC AACTTTTGTTCCATTTATGGAAGATACTCCTTTGCAGAGAGCAGAATGGATCAAATTCATGGGAGCTTTTGCAAATGTTG AAGCTAGAGCCAATCAAGTCTATACAGCAGTTAAGGTGAACTATTTGTGCTTGGCTAAAGTTGCCACAACTAGGACAACA TTCAAGCCAACGGTAGCTTGGATGAGGTATAAAAATGGTCTTTGGTCTTTTACACAGGAAAAGTATCAATTGAAGTACGT GCAAGATGCAGGCGGAGAGATTTTGGGTGCCAACAAAAACACTTACAATGTCTCTGATCCTGATGACTTGGAGGAATTTC ATGCCATCCTATGTACTGCGGAAGTAGTCATTGATGAAACACTAACATCTGATCCAGTCAACTACACCATGTCAGCATTT ATCCAAAATCTAAATGTTGAAGATCGTTCTTGTTTTTCCTTTATTTCAAACACAAGTCTATGGAGATATGACAAAAGGGT TTATAATTCTGTAGCTCTTGACTGGTATAATGGAGCTGTGTCCCAACCTCAATTGGCACTAGCAGATCTTATTGAAGTTT TATTTCCCACTGGAAATTACACAATGACATATTTTAGGAACATTGCAAAGGGAGAAGTACCTATAAACATTGGTCCCGAA ATGTGTGATAGGGACACATCCACAGCAATGGAGCCTACCATAGTAGCATGTGGATGA |
| Microexon DNA seq | TCTCCTTTGTAGAG |
| Microexon Amino Acid seq | VSFVE |
| Microexon-tag DNA Seq | GTCATTCCATTGTCAAACTATTCTGTTGATACAACTTTTTTTCCGGTCTCCTTTGTAGAGCTTTTAGGTTTAGTGGAGAGCTTGAAAGGCATAACCTCAGACTATGTG |
| Microexon-tag Amino Acid seq | VIPLSNYSVDTTFFPVSFVELLGLVESLKGITSDYV |
| Transcript ID | KRH30887 |
| Gene ID | Gm.7383 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >KRH30887 MITLFLYSKRYLIQLMDSAPSSSWLQAFSFLALVWLFNCGCVHGASPAVKVGNFSKVEDAGNFHIYYGQTFKVIKNSADG QSYLLLQNNSRIASRTKYCTSRIKSFVIPLSNYSVDTTFFPVSFVELLGLVESLKGITSDYVASPCVLKLYQGGQLEMFN NSDYQKLAEFSSYFLSDTDQQPACNFATFVPFMEDTPLQRAEWIKFMGAFANVEARANQVYTAVKVNYLCLAKVATTRTT FKPTVAWMRYKNGLWSFTQEKYQLKYVQDAGGEILGANKNTYNVSDPDDLEEFHAILCTAEVVIDETLTSDPVNYTMSAF IQNLNVEDRSCFSFISNTSLWRYDKRVYNSVALDWYNGAVSQPQLALADLIEVLFPTGNYTMTYFRNIAKGEVPINIGPE MCDRDTSTAMEPTIVACG* |
| CDS seq | >KRH30887 ATGATCACATTATTTTTATATAGCAAGAGGTACCTCATTCAGCTCATGGATTCAGCTCCTTCTAGTTCTTGGCTGCAAGC CTTCTCCTTCTTAGCATTGGTTTGGTTATTTAACTGTGGATGTGTCCATGGAGCCTCCCCAGCAGTGAAAGTAGGTAACT TTTCAAAGGTGGAAGATGCTGGAAACTTCCACATCTACTATGGCCAGACCTTCAAAGTCATTAAGAATTCTGCTGATGGC CAGAGCTACCTTCTTCTCCAGAATAATTCAAGGATTGCATCAAGGACTAAATATTGCACATCAAGAATCAAATCATTTGT CATTCCATTGTCAAACTATTCTGTTGATACAACTTTTTTTCCGGTCTCCTTTGTAGAGCTTTTAGGTTTAGTGGAGAGCT TGAAAGGCATAACCTCAGACTATGTGGCTTCTCCATGTGTGTTGAAACTGTATCAAGGAGGACAGCTAGAAATGTTCAAT AATAGTGATTACCAAAAGCTTGCAGAGTTCTCTTCATACTTTCTTAGTGACACTGATCAGCAGCCAGCTTGCAATTTTGC AACTTTTGTTCCATTTATGGAAGATACTCCTTTGCAGAGAGCAGAATGGATCAAATTCATGGGAGCTTTTGCAAATGTTG AAGCTAGAGCCAATCAAGTCTATACAGCAGTTAAGGTGAACTATTTGTGCTTGGCTAAAGTTGCCACAACTAGGACAACA TTCAAGCCAACGGTAGCTTGGATGAGGTATAAAAATGGTCTTTGGTCTTTTACACAGGAAAAGTATCAATTGAAGTACGT GCAAGATGCAGGCGGAGAGATTTTGGGTGCCAACAAAAACACTTACAATGTCTCTGATCCTGATGACTTGGAGGAATTTC ATGCCATCCTATGTACTGCGGAAGTAGTCATTGATGAAACACTAACATCTGATCCAGTCAACTACACCATGTCAGCATTT ATCCAAAATCTAAATGTTGAAGATCGTTCTTGTTTTTCCTTTATTTCAAACACAAGTCTATGGAGATATGACAAAAGGGT TTATAATTCTGTAGCTCTTGACTGGTATAATGGAGCTGTGTCCCAACCTCAATTGGCACTAGCAGATCTTATTGAAGTTT TATTTCCCACTGGAAATTACACAATGACATATTTTAGGAACATTGCAAAGGGAGAAGTACCTATAAACATTGGTCCCGAA ATGTGTGATAGGGACACATCCACAGCAATGGAGCCTACCATAGTAGCATGTGGATGA |