| Microexon ID | Ps_NC_039363.1:19419868-19419881:- |
| Species | Papaver somniferum | Coordinates | NC_039363.1:19419868..19419881 |
| Microexon Cluster ID | MEP39 |
| Size | 14 |
| Phase | 1 |
| Pfam Domain Motif | Unknown |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 24,22,14,48 |
| Microexon location in the Microexon-tag | 3 |
| Microexon-tag DNA Seq | GRWGMWGGAGRYATGTAYKSYBTYCAASSTTCTGGAGCYMGKGCAGKTGGATTTCCWCAGATGGSMAATGCTGCAGCMATTGCAGCTGCCTTTGSKGGWGGTTTGCCT |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 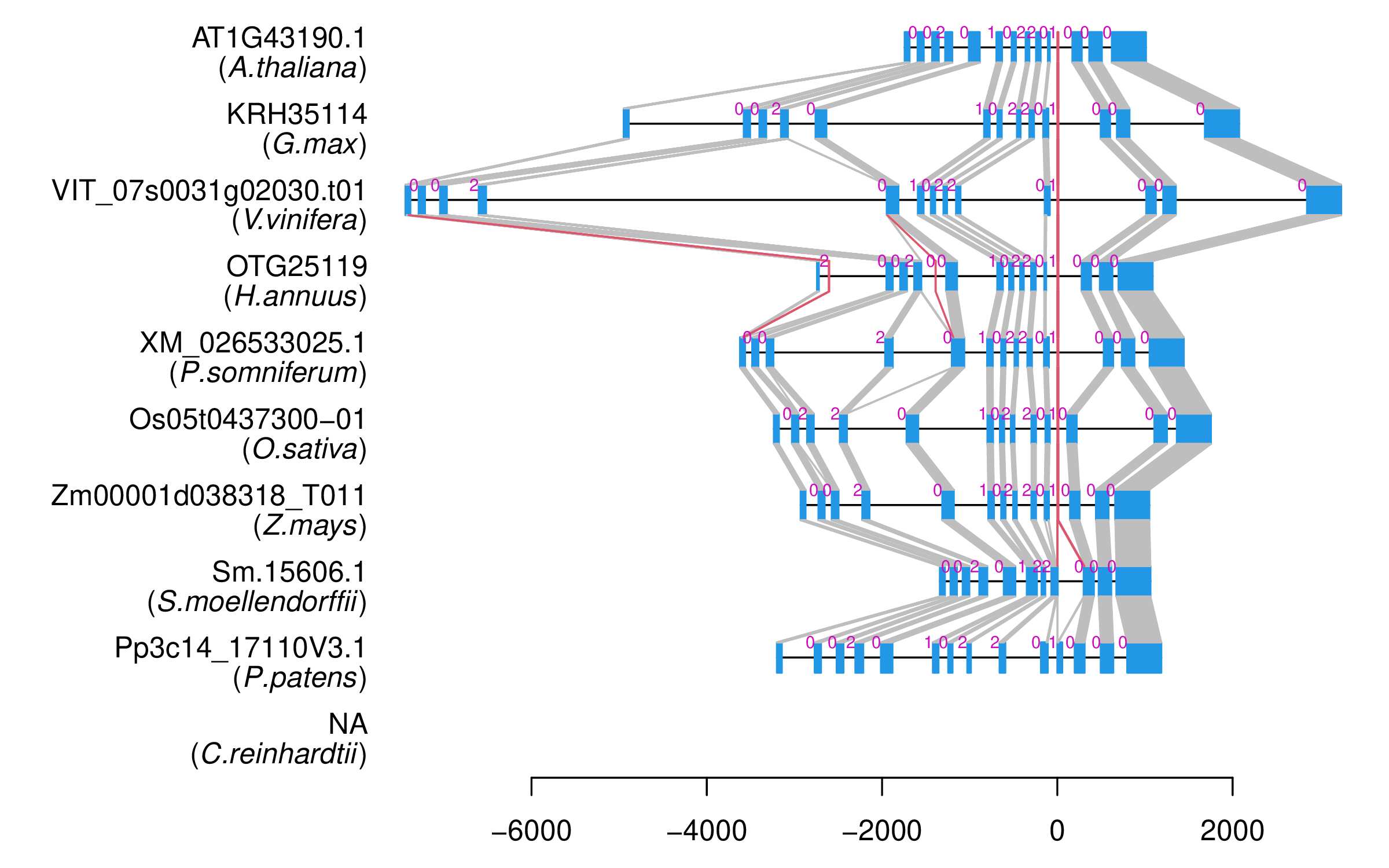 |
| Microexon DNA seq | GTGGATATCCACAG |
| Microexon Amino Acid seq | GGYPQ |
| Microexon-tag DNA Seq | GCTGAGGGAGGTTTATATGGTGCACAACCTTCTGGAGCTAGGCCAGGTGGATATCCACAGATGGGAAATGCAGCAGCTGTAGCAGCTGCATTTGGAGGCGGGTTGCCT |
| Microexon-tag Amino Acid Seq | AEGGLYGAQPSGARPGGYPQMGNAAAVAAAFGGGLP |
| Microexon-tag spanning region | 19419343-19420023 |
| Microexon-tag prediction score | 0.936 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026535807.1x |
| Reference Transcript ID | XM_026535807.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026535807.1 |
| Protein ID | XP_026391592.1 |
| Gene ID | LOC113287127 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026391592.1 MTEPSKVIHVRNVGHEIAENDLLQLVQPFGVVTKLVMLRAKNQALLQMQDVAAAVDVIQYFTNVQPSVRGRNVYIQFSSH QELTTMDQNGQGRKSSEQETEPNRILLVSIHHLLYPITVEVLHQVFSPHGYVEKIVTFQKSAGSQALIQFQTRQSAVAAR TALQGRNIYDGCCQLDVQFSNLSELQVNFNNERSRDYTNPSLPTEQKGRSSQPNYAEGGLYGAQPSGARPGGYPQMGNAA AVAAAFGGGLPPGISGTNERCTVLVSNLDPDRIDEDKLFNLFSIYGNIARIKLLRNKPDHALVQMGDGFQAELAVHFLKG AMLFEKRMEVNFSKHPTITAAPDTHEYQNSNLNRFNRNAAKNYRYCCSPTKIIHLSTLPQEITEEEIVCHLEEHGTIVNT KLFEVNGKKQALIMFETEEQATEALVCKHATTIDRSVIRISFSQLQNI* |
| CDS seq | >XM_026535807.1 ATGACTGAACCTTCTAAGGTCATTCATGTTCGTAATGTAGGCCACGAAATAGCGGAGAATGATTTGCTTCAATTAGTACA GCCATTTGGTGTTGTTACTAAGCTTGTTATGTTAAGGGCTAAAAATCAGGCACTTCTTCAGATGCAAGATGTGGCAGCTG CTGTTGATGTGATACAGTACTTCACTAATGTTCAGCCTAGTGTCAGAGGGAGGAATGTTTACATTCAATTCTCTTCACAT CAAGAATTGACGACAATGGATCAGAATGGTCAAGGACGCAAGAGCAGTGAACAGGAAACAGAACCCAATCGAATTCTATT AGTATCAATTCATCACCTGCTCTATCCTATAACGGTGGAAGTGCTGCATCAAGTGTTTTCTCCTCATGGGTATGTGGAGA AGATCGTCACGTTTCAGAAGTCAGCTGGTTCTCAAGCCCTTATACAATTTCAAACACGCCAGAGTGCTGTTGCTGCAAGG ACAGCTCTCCAAGGACGCAATATTTATGATGGTTGTTGTCAGCTGGATGTTCAGTTCTCAAACCTCAGTGAGTTACAAGT AAACTTCAACAACGAGCGCTCTAGGGATTACACCAACCCATCTTTGCCTACTGAACAAAAAGGCAGATCCTCCCAGCCTA ACTATGCTGAGGGAGGTTTATATGGTGCACAACCTTCTGGAGCTAGGCCAGGTGGATATCCACAGATGGGAAATGCAGCA GCTGTAGCAGCTGCATTTGGAGGCGGGTTGCCTCCTGGTATTAGCGGTACCAATGAACGATGCACAGTCTTGGTTTCCAA CCTTGATCCCGATAGAATTGATGAGGATAAGCTCTTCAACCTGTTCTCCATTTATGGAAACATCGCGAGAATCAAACTTC TCCGCAACAAACCAGATCATGCCCTTGTTCAGATGGGTGATGGATTTCAAGCTGAATTGGCCGTACACTTCTTGAAGGGA GCCATGCTGTTTGAAAAGCGTATGGAGGTGAACTTTTCAAAGCATCCAACTATTACTGCAGCACCTGACACGCATGAGTA CCAGAATTCGAACCTGAATCGGTTCAATCGCAATGCAGCAAAGAATTACCGTTACTGCTGTTCCCCAACCAAGATTATCC ACTTGTCCACCCTTCCTCAAGAAATTACTGAGGAAGAAATTGTCTGCCACCTCGAGGAGCATGGAACCATAGTGAACACC AAGCTTTTTGAAGTGAATGGCAAAAAACAGGCCCTTATCATGTTTGAAACAGAGGAGCAGGCTACTGAGGCTCTTGTGTG CAAGCACGCAACAACCATAGATCGTTCAGTCATCCGGATCTCCTTCTCCCAGCTGCAGAACATCTAA |
| Microexon DNA seq | GTGGATATCCACAG |
| Microexon Amino Acid seq | GGYPQ |
| Microexon-tag DNA Seq | GCTGAGGGAGGTTTATATGGTGCACAACCTTCTGGAGCTAGGCCAGGTGGATATCCACAGATGGGAAATGCAGCAGCTGTAGCAGCTGCATTTGGAGGCGGGTTGCCT |
| Microexon-tag Amino Acid seq | AEGGLYGAQPSGARPGGYPQMGNAAAVAAAFGGGLP |
| Transcript ID | XM_026535807.1 |
| Gene ID | Ps.34787 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026535807.1 MTEPSKVIHVRNVGHEIAENDLLQLVQPFGVVTKLVMLRAKNQALLQMQDVAAAVDVIQYFTNVQPSVRGRNVYIQFSSH QELTTMDQNGQGRKSSEQETEPNRILLVSIHHLLYPITVEVLHQVFSPHGYVEKIVTFQKSAGSQALIQFQTRQSAVAAR TALQGRNIYDGCCQLDVQFSNLSELQVNFNNERSRDYTNPSLPTEQKGRSSQPNYAEGGLYGAQPSGARPGGYPQMGNAA AVAAAFGGGLPPGISGTNERCTVLVSNLDPDRIDEDKLFNLFSIYGNIARIKLLRNKPDHALVQMGDGFQAELAVHFLKG AMLFEKRMEVNFSKHPTITAAPDTHEYQNSNLNRFNRNAAKNYRYCCSPTKIIHLSTLPQEITEEEIVCHLEEHGTIVNT KLFEVNGKKQALIMFETEEQATEALVCKHATTIDRSVIRISFSQLQNI* |
| CDS seq | >XM_026535807.1 ATGACTGAACCTTCTAAGGTCATTCATGTTCGTAATGTAGGCCACGAAATAGCGGAGAATGATTTGCTTCAATTAGTACA GCCATTTGGTGTTGTTACTAAGCTTGTTATGTTAAGGGCTAAAAATCAGGCACTTCTTCAGATGCAAGATGTGGCAGCTG CTGTTGATGTGATACAGTACTTCACTAATGTTCAGCCTAGTGTCAGAGGGAGGAATGTTTACATTCAATTCTCTTCACAT CAAGAATTGACGACAATGGATCAGAATGGTCAAGGACGCAAGAGCAGTGAACAGGAAACAGAACCCAATCGAATTCTATT AGTATCAATTCATCACCTGCTCTATCCTATAACGGTGGAAGTGCTGCATCAAGTGTTTTCTCCTCATGGGTATGTGGAGA AGATCGTCACGTTTCAGAAGTCAGCTGGTTCTCAAGCCCTTATACAATTTCAAACACGCCAGAGTGCTGTTGCTGCAAGG ACAGCTCTCCAAGGACGCAATATTTATGATGGTTGTTGTCAGCTGGATGTTCAGTTCTCAAACCTCAGTGAGTTACAAGT AAACTTCAACAACGAGCGCTCTAGGGATTACACCAACCCATCTTTGCCTACTGAACAAAAAGGCAGATCCTCCCAGCCTA ACTATGCTGAGGGAGGTTTATATGGTGCACAACCTTCTGGAGCTAGGCCAGGTGGATATCCACAGATGGGAAATGCAGCA GCTGTAGCAGCTGCATTTGGAGGCGGGTTGCCTCCTGGTATTAGCGGTACCAATGAACGATGCACAGTCTTGGTTTCCAA CCTTGATCCCGATAGAATTGATGAGGATAAGCTCTTCAACCTGTTCTCCATTTATGGAAACATCGCGAGAATCAAACTTC TCCGCAACAAACCAGATCATGCCCTTGTTCAGATGGGTGATGGATTTCAAGCTGAATTGGCCGTACACTTCTTGAAGGGA GCCATGCTGTTTGAAAAGCGTATGGAGGTGAACTTTTCAAAGCATCCAACTATTACTGCAGCACCTGACACGCATGAGTA CCAGAATTCGAACCTGAATCGGTTCAATCGCAATGCAGCAAAGAATTACCGTTACTGCTGTTCCCCAACCAAGATTATCC ACTTGTCCACCCTTCCTCAAGAAATTACTGAGGAAGAAATTGTCTGCCACCTCGAGGAGCATGGAACCATAGTGAACACC AAGCTTTTTGAAGTGAATGGCAAAAAACAGGCCCTTATCATGTTTGAAACAGAGGAGCAGGCTACTGAGGCTCTTGTGTG CAAGCACGCAACAACCATAGATCGTTCAGTCATCCGGATCTCCTTCTCCCAGCTGCAGAACATCTAA |