| Microexon ID | Ps_NC_039358.1:38926747-38926760:- |
| Species | Papaver somniferum | Coordinates | NC_039358.1:38926747..38926760 |
| Microexon Cluster ID | MEP39 |
| Size | 14 |
| Phase | 1 |
| Pfam Domain Motif | Unknown |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 24,22,14,48 |
| Microexon location in the Microexon-tag | 3 |
| Microexon-tag DNA Seq | GRWGMWGGAGRYATGTAYKSYBTYCAASSTTCTGGAGCYMGKGCAGKTGGATTTCCWCAGATGGSMAATGCTGCAGCMATTGCAGCTGCCTTTGSKGGWGGTTTGCCT |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 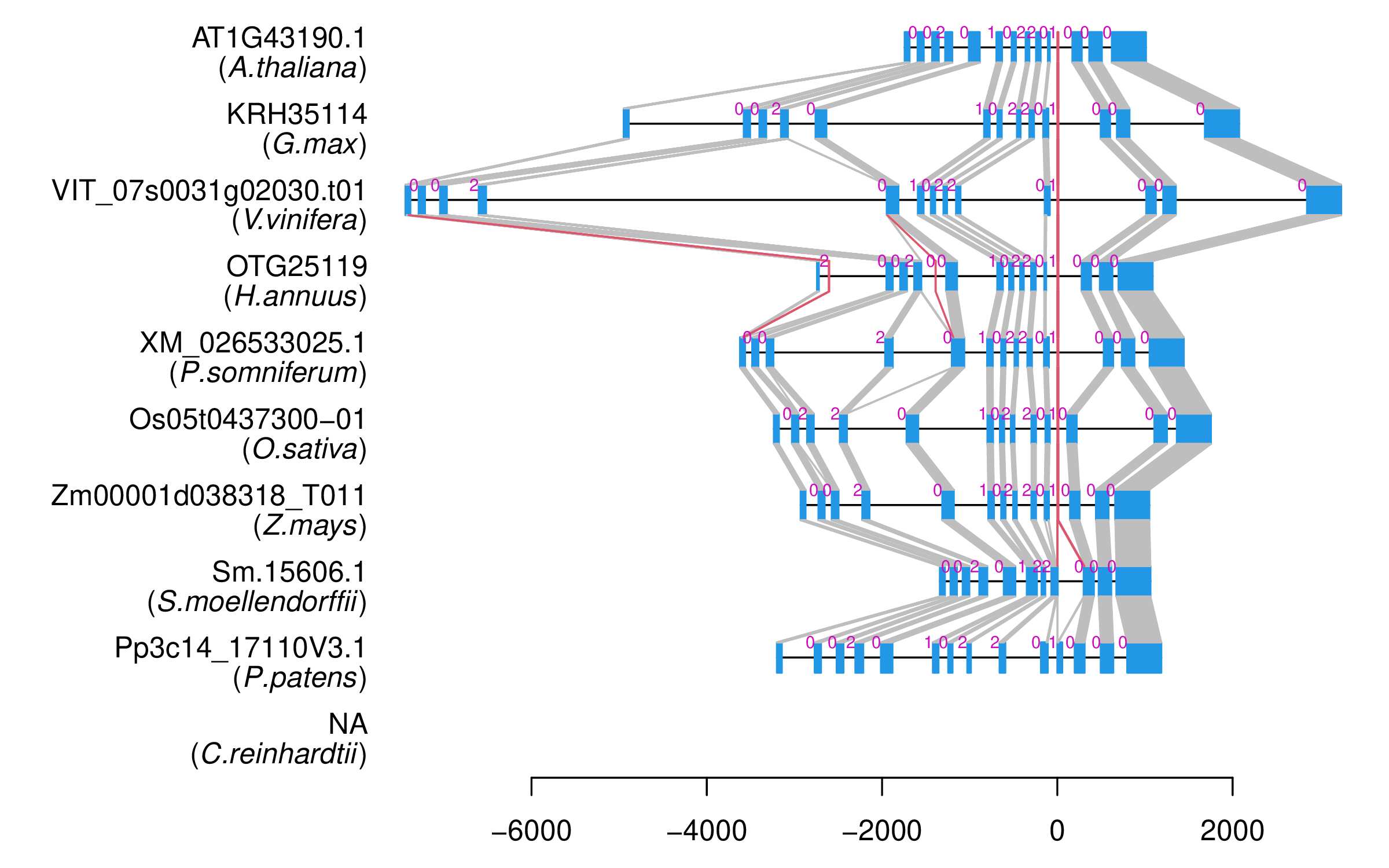 |
| Microexon DNA seq | GTGGATATCCACAG |
| Microexon Amino Acid seq | GGYPQ |
| Microexon-tag DNA Seq | GCTGAGGGAGGTTTATATGGTGTACAACCTTCTGGAGCTAGGCCAGGTGGATATCCACAGATGGGAAATGCGGCAGCTGTAGCAGCTGCATTTGGAGGCGGGTTGCCT |
| Microexon-tag Amino Acid Seq | AEGGLYGVQPSGARPGGYPQMGNAAAVAAAFGGGLP |
| Microexon-tag spanning region | 38926183-38926902 |
| Microexon-tag prediction score | 0.9385 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026533025.1x |
| Reference Transcript ID | XM_026533025.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026533025.1 |
| Protein ID | XP_026388810.1 |
| Gene ID | LOC113283693 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026388810.1 MTEPSKVIHVRNVGHEIAENDLLQLVQPFGVVTKLVMLRAKNQALLQMQDVAAAVDVIQYFTNVQPSVRGRNVYIQFSSH QELTTMDQNGQGRKSGEQISQETEPNRILLVSIHHLLYPITVEVLHQVFSPHGYVEKIVTFQKSAGSQALIQFQTRQSAV AARTALQGRNIYDGCCQLDVQFSNLSELQVNFNNERSRDYTNPSLPTEQKGRSSQPNYAEGGLYGVQPSGARPGGYPQMG NAAAVAAAFGGGLPPGISGTNERCTVLVSNLDPDRIDEDKLFNLFSIYGNIVRIKLLRNKPDHALVQMGDGFQAELAVHF LKGAMLFEKRMEVNFSKHPTITAAPDTHEYQNSNLNRFNRNAAKNYRYCCSPTKIIHLSTLPQEITEEEIVCHLEEHGTI VNTKLFEVNGKKQALIMFETEEQATEALVCKHAITINRSVIRISFSQLQNI* |
| CDS seq | >XM_026533025.1 ATGACTGAACCTTCTAAGGTCATTCATGTTCGTAATGTAGGCCACGAAATAGCCGAGAATGATTTGCTTCAATTAGTACA GCCATTTGGTGTTGTCACTAAGCTTGTCATGTTAAGGGCTAAAAATCAGGCACTTCTTCAGATGCAAGATGTGGCAGCTG CTGTTGATGTGATACAGTACTTCACTAATGTTCAACCTAGTGTCAGAGGGAGGAATGTTTACATTCAGTTCTCTTCACAT CAAGAATTGACAACAATGGATCAGAATGGTCAAGGACGCAAGAGTGGTGAACAGATATCTCAGGAAACAGAACCCAATCG AATTCTATTAGTATCAATTCATCACCTGCTCTATCCTATAACGGTGGAAGTGCTGCATCAAGTGTTCTCTCCTCATGGGT ATGTGGAGAAGATCGTCACGTTTCAGAAGTCAGCTGGTTCTCAAGCCCTTATACAATTTCAAACACGCCAGAGTGCTGTT GCTGCAAGGACAGCTCTCCAAGGACGCAATATTTATGATGGTTGTTGTCAGCTGGATGTTCAGTTCTCAAACCTCAGTGA GTTACAAGTAAACTTCAACAATGAGCGCTCTAGGGATTACACCAACCCATCTTTGCCTACTGAACAAAAAGGCAGATCCT CCCAGCCTAACTATGCTGAGGGAGGTTTATATGGTGTACAACCTTCTGGAGCTAGGCCAGGTGGATATCCACAGATGGGA AATGCGGCAGCTGTAGCAGCTGCATTTGGAGGCGGGTTGCCTCCTGGTATTAGCGGTACCAATGAACGATGCACAGTCTT GGTTTCCAACCTTGATCCCGATAGAATTGATGAGGATAAGCTCTTCAACCTATTCTCCATTTATGGAAACATCGTGAGAA TCAAACTTCTCCGCAACAAACCAGATCATGCCCTTGTTCAGATGGGTGATGGATTTCAAGCTGAATTGGCTGTACACTTC TTGAAGGGAGCAATGCTGTTTGAAAAGCGTATGGAGGTGAACTTTTCAAAGCATCCAACTATTACTGCAGCTCCTGACAC ACATGAGTACCAGAATTCGAACCTGAATCGGTTCAATCGCAATGCAGCAAAGAATTACCGTTACTGCTGTTCCCCAACCA AGATTATCCACTTGTCAACCCTCCCTCAAGAAATTACAGAGGAAGAAATTGTTTGCCACCTCGAGGAGCATGGAACCATA GTGAACACCAAGCTTTTTGAAGTGAATGGCAAAAAACAGGCTCTTATCATGTTTGAAACAGAGGAGCAGGCCACTGAGGC TCTCGTGTGCAAGCACGCAATAACCATAAATCGCTCAGTCATCCGGATCTCCTTCTCCCAGCTGCAGAACATCTAA |
| Microexon DNA seq | GTGGATATCCACAG |
| Microexon Amino Acid seq | GGYPQ |
| Microexon-tag DNA Seq | GCTGAGGGAGGTTTATATGGTGTACAACCTTCTGGAGCTAGGCCAGGTGGATATCCACAGATGGGAAATGCGGCAGCTGTAGCAGCTGCATTTGGAGGCGGGTTGCCT |
| Microexon-tag Amino Acid seq | AEGGLYGVQPSGARPGGYPQMGNAAAVAAAFGGGLP |
| Transcript ID | XM_026533031.1 |
| Gene ID | Ps.1346 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026533031.1 MTEPSKVIHVRNVGHEIAENDLLQLVQPFGVVTKLVMLRAKNQALLQMQDVAAAVDVIQYFTNVQPSVRGRNVYIQFSSH QELTTMDQNGQGRKSGEQETEPNRILLVSIHHLLYPITVEVLHQVFSPHGYVEKIVTFQKSAGSQALIQFQTRQSAVAAR TALQGRNIYDGCCQLDVQFSNLSELQVNFNNERSRDYTNPSLPTEQKGRSSQPNYAEGGLYGVQPSGARPGGYPQMGNAA AVAAAFGGGLPPGISGTNERCTVLVSNLDPDRIDEDKLFNLFSIYGNIVRIKLLRNKPDHALVQMGDGFQAELAVHFLKG AMLFEKRMEVNFSKHPTITAAPDTHEYQNSNLNRFNRNAAKNYRYCCSPTKIIHLSTLPQEITEEEIVCHLEEHGTIVNT KLFEVNGKKQALIMFETEEQATEALVCKHAITINRSVIRISFSQLQNI* |
| CDS seq | >XM_026533031.1 ATGACTGAACCTTCTAAGGTCATTCATGTTCGTAATGTAGGCCACGAAATAGCCGAGAATGATTTGCTTCAATTAGTACA GCCATTTGGTGTTGTCACTAAGCTTGTCATGTTAAGGGCTAAAAATCAGGCACTTCTTCAGATGCAAGATGTGGCAGCTG CTGTTGATGTGATACAGTACTTCACTAATGTTCAACCTAGTGTCAGAGGGAGGAATGTTTACATTCAGTTCTCTTCACAT CAAGAATTGACAACAATGGATCAGAATGGTCAAGGACGCAAGAGTGGTGAACAGGAAACAGAACCCAATCGAATTCTATT AGTATCAATTCATCACCTGCTCTATCCTATAACGGTGGAAGTGCTGCATCAAGTGTTCTCTCCTCATGGGTATGTGGAGA AGATCGTCACGTTTCAGAAGTCAGCTGGTTCTCAAGCCCTTATACAATTTCAAACACGCCAGAGTGCTGTTGCTGCAAGG ACAGCTCTCCAAGGACGCAATATTTATGATGGTTGTTGTCAGCTGGATGTTCAGTTCTCAAACCTCAGTGAGTTACAAGT AAACTTCAACAATGAGCGCTCTAGGGATTACACCAACCCATCTTTGCCTACTGAACAAAAAGGCAGATCCTCCCAGCCTA ACTATGCTGAGGGAGGTTTATATGGTGTACAACCTTCTGGAGCTAGGCCAGGTGGATATCCACAGATGGGAAATGCGGCA GCTGTAGCAGCTGCATTTGGAGGCGGGTTGCCTCCTGGTATTAGCGGTACCAATGAACGATGCACAGTCTTGGTTTCCAA CCTTGATCCCGATAGAATTGATGAGGATAAGCTCTTCAACCTATTCTCCATTTATGGAAACATCGTGAGAATCAAACTTC TCCGCAACAAACCAGATCATGCCCTTGTTCAGATGGGTGATGGATTTCAAGCTGAATTGGCTGTACACTTCTTGAAGGGA GCAATGCTGTTTGAAAAGCGTATGGAGGTGAACTTTTCAAAGCATCCAACTATTACTGCAGCTCCTGACACACATGAGTA CCAGAATTCGAACCTGAATCGGTTCAATCGCAATGCAGCAAAGAATTACCGTTACTGCTGTTCCCCAACCAAGATTATCC ACTTGTCAACCCTCCCTCAAGAAATTACAGAGGAAGAAATTGTTTGCCACCTCGAGGAGCATGGAACCATAGTGAACACC AAGCTTTTTGAAGTGAATGGCAAAAAACAGGCTCTTATCATGTTTGAAACAGAGGAGCAGGCCACTGAGGCTCTCGTGTG CAAGCACGCAATAACCATAAATCGCTCAGTCATCCGGATCTCCTTCTCCCAGCTGCAGAACATCTAA |