| Microexon ID | Gm_10:45433085-45433098:- |
| Species | Glycine max | Coordinates | 10:45433085..45433098 |
| Microexon Cluster ID | MEP39 |
| Size | 14 |
| Phase | 1 |
| Pfam Domain Motif | Unknown |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 24,22,14,48 |
| Microexon location in the Microexon-tag | 3 |
| Microexon-tag DNA Seq | GRWGMWGGAGRYATGTAYKSYBTYCAASSTTCTGGAGCYMGKGCAGKTGGATTTCCWCAGATGGSMAATGCTGCAGCMATTGCAGCTGCCTTTGSKGGWGGTTTGCCT |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 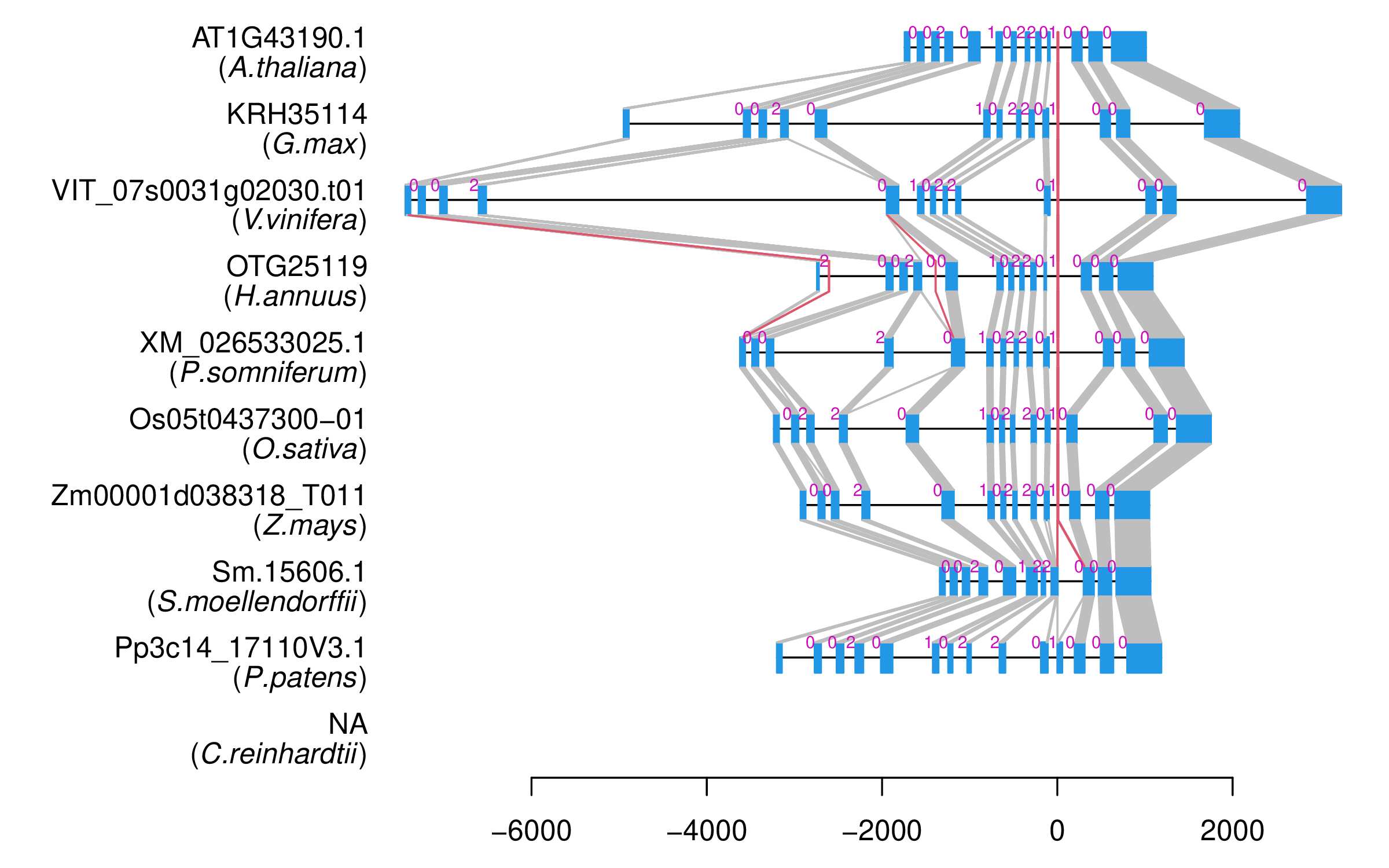 |
| Microexon DNA seq | TTGGATTTCCACAG |
| Microexon Amino Acid seq | VGFPQ |
| Microexon-tag DNA Seq | GATGCAGGAAACATGTATGCTGCCCAGGGTTCAGGAGCCAGGGCAGTTGGATTTCCACAGATGGCAAATGCTGCAGCCATTGCAGCTGCCTTTGGGGGAGGTCTGCCT |
| Microexon-tag Amino Acid Seq | DAGNMYAAQGSGARAVGFPQMANAAAIAAAFGGGLP |
| Microexon-tag spanning region | 45432556-45433246 |
| Microexon-tag prediction score | 0.9813 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | KRH35114x |
| Reference Transcript ID | KRH35114 |
| Gene ID | GLYMA_10G223300 |
| Gene Name | NA |
| Transcript ID | KRH35114 |
| Protein ID | KRH35114 |
| Gene ID | GLYMA_10G223300 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >KRH35114 MTEPSKVIHVRNVGHEISENDLLQLFQPFGVITKLVMLRAKNQALIQMQDVPSAVNALQFYANVQPSIRGRNVYVQFSSH QELTTMDQSQGRGDEPNRILLVTVHHMLYPMTVDVLYQVFSPHGSVEKIVTFQKSAGFQALIQYQSRQSAVAARSTLQGR NIYDGCCQLDIQFSNLDELQVNYNNDRSRDFTNPNLPTEQKGRPSQPGYGDAGNMYAAQGSGARAVGFPQMANAAAIAAA FGGGLPPGITGTNDRCTVLVSNLNPDRIDEDKLFNLFSIYGNIMRIKLLRNKPDHALIQMGDGFQAKLAVHFLRGAMLFE KRLEVNFSKHPKITPGADTHEYISSNLNRFNRNAAKNYRYCCPPTKMIHLSTLPLDITEEEIVSLVEEHGIIVNSKVFEM NGKKQALVQFENEEQATEALVCKHASTLSGSVIRISFSQLQNI* |
| CDS seq | >KRH35114 ATGACCGAACCTTCCAAGGTCATTCACGTTCGAAATGTGGGCCACGAAATATCTGAAAATGACTTACTTCAGCTGTTTCA GCCTTTTGGAGTCATAACAAAGCTTGTCATGCTGCGTGCAAAAAATCAGGCTCTTATCCAAATGCAAGATGTTCCTTCTG CAGTTAATGCTTTACAATTTTATGCAAATGTTCAGCCAAGCATAAGGGGGAGGAATGTTTATGTTCAATTTTCCTCACAT CAGGAATTAACAACAATGGATCAAAGTCAAGGACGAGGAGATGAGCCAAACCGAATTCTCTTAGTCACAGTTCATCACAT GTTGTATCCTATGACTGTGGATGTGCTGTATCAAGTATTTTCTCCCCATGGATCTGTGGAAAAGATTGTAACATTTCAGA AGTCAGCTGGCTTTCAGGCTCTCATCCAGTATCAATCACGTCAGAGTGCTGTTGCAGCAAGAAGTACACTTCAGGGACGC AATATTTATGATGGTTGCTGTCAGCTGGACATTCAGTTCTCAAACCTTGATGAATTACAAGTGAACTACAATAATGACCG TTCAAGGGACTTCACAAACCCAAATCTCCCCACAGAGCAGAAAGGCAGACCTTCACAACCTGGATATGGTGATGCAGGAA ACATGTATGCTGCCCAGGGTTCAGGAGCCAGGGCAGTTGGATTTCCACAGATGGCAAATGCTGCAGCCATTGCAGCTGCC TTTGGGGGAGGTCTGCCTCCTGGAATAACTGGGACAAATGACAGGTGTACAGTTCTTGTATCAAATCTTAATCCTGATAG AATTGATGAGGATAAACTATTCAACTTGTTCTCTATTTATGGGAACATTATGAGAATTAAACTTCTCCGAAATAAGCCAG ATCATGCACTTATCCAGATGGGAGATGGTTTTCAAGCAAAACTGGCTGTACACTTTCTGAGGGGAGCCATGTTGTTTGAG AAACGATTAGAGGTCAACTTCTCCAAGCATCCAAAAATAACCCCAGGTGCTGACACACATGAATACATCAGTTCAAATCT CAATCGTTTCAACCGTAATGCAGCCAAAAACTATCGGTATTGCTGCCCCCCAACAAAGATGATTCATTTGTCCACACTTC CACTAGACATCACTGAAGAGGAGATTGTGAGCCTTGTAGAGGAACATGGAATCATTGTCAACAGCAAAGTCTTCGAGATG AACGGGAAAAAGCAGGCTCTGGTTCAGTTTGAAAATGAGGAGCAGGCTACTGAAGCCCTTGTGTGCAAGCATGCAAGTAC ACTTTCTGGCTCAGTAATCCGTATCTCCTTTTCGCAGTTACAGAATATATGA |
| Microexon DNA seq | TTGGATTTCCACAG |
| Microexon Amino Acid seq | VGFPQ |
| Microexon-tag DNA Seq | GATGCAGGAAACATGTATGCTGCCCAGGGTTCAGGAGCCAGGGCAGTTGGATTTCCACAGATGGCAAATGCTGCAGCCATTGCAGCTGCCTTTGGGGGAGGTCTGCCT |
| Microexon-tag Amino Acid seq | DAGNMYAAQGSGARAVGFPQMANAAAIAAAFGGGLP |
| Transcript ID | Gm.4536.1 |
| Gene ID | Gm.4536 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >Gm.4536.1 MTEPSKVIHVRNVGHEISENDLLQLFQPFGVITKLVMLRAKNQALIQMQDVPSAVNALQFYANVQPSIRGRNVYVQFSSH QELTTMDQSQGRGDEPNRILLVTVHHMLYPMTVDVLYQVFSPHGSVEKIVTFQKSAGFQALIQYQSRQSAVAARSTLQGR NIYDGCCQLDIQFSNLDELQVNYNNDRSRDFTNPNLPTEQKGRPSQPGYGDAGNMYAAQGSGARAVGFPQMANAAAIAAA FGGGLPPGITGTNDRCTVLVSNLNPDRIDEDKLFNLFSIYGNIMRIKLLRNKPDHALIQMGDGFQAKLAVHFLRGAMLFE KRLEVNFSKHPKITPGADTHEYISSNLNRFNRNAAKNYRYCCPPTKMIHLSTLPLDITEEEIVSLVEEHGIIVNSKVFEM NGKKQALVQFENEEQATEALVCKHASTLSGSVIRISFSQLQNI* |
| CDS seq | >Gm.4536.1 ATGACCGAACCTTCCAAGGTCATTCACGTTCGAAATGTGGGCCACGAAATATCTGAAAATGACTTACTTCAGCTGTTTCA GCCTTTTGGAGTCATAACAAAGCTTGTCATGCTGCGTGCAAAAAATCAGGCTCTTATCCAAATGCAAGATGTTCCTTCTG CAGTTAATGCTTTACAATTTTATGCAAATGTTCAGCCAAGCATAAGGGGGAGGAATGTTTATGTTCAATTTTCCTCACAT CAGGAATTAACAACAATGGATCAAAGTCAAGGACGAGGAGATGAGCCAAACCGAATTCTCTTAGTCACAGTTCATCACAT GTTGTATCCTATGACTGTGGATGTGCTGTATCAAGTATTTTCTCCCCATGGATCTGTGGAAAAGATTGTAACATTTCAGA AGTCAGCTGGCTTTCAGGCTCTCATCCAGTATCAATCACGTCAGAGTGCTGTTGCAGCAAGAAGTACACTTCAGGGACGC AATATTTATGATGGTTGCTGTCAGCTGGACATTCAGTTCTCAAACCTTGATGAATTACAAGTGAACTACAATAATGACCG TTCAAGGGACTTCACAAACCCAAATCTCCCCACAGAGCAGAAAGGCAGACCTTCACAACCTGGATATGGTGATGCAGGAA ACATGTATGCTGCCCAGGGTTCAGGAGCCAGGGCAGTTGGATTTCCACAGATGGCAAATGCTGCAGCCATTGCAGCTGCC TTTGGGGGAGGTCTGCCTCCTGGAATAACTGGGACAAATGACAGGTGTACAGTTCTTGTATCAAATCTTAATCCTGATAG AATTGATGAGGATAAACTATTCAACTTGTTCTCTATTTATGGGAACATTATGAGAATTAAACTTCTCCGAAATAAGCCAG ATCATGCACTTATCCAGATGGGAGATGGTTTTCAAGCAAAACTGGCTGTACACTTTCTGAGGGGAGCCATGTTGTTTGAG AAACGATTAGAGGTCAACTTCTCCAAGCATCCAAAAATAACCCCAGGTGCTGACACACATGAATACATCAGTTCAAATCT CAATCGTTTCAACCGTAATGCAGCCAAAAACTATCGGTATTGCTGCCCCCCAACAAAGATGATTCATTTGTCCACACTTC CACTAGACATCACTGAAGAGGAGATTGTGAGCCTTGTAGAGGAACATGGAATCATTGTCAACAGCAAAGTCTTCGAGATG AACGGGAAAAAGCAGGCTCTGGTTCAGTTTGAAAATGAGGAGCAGGCTACTGAAGCCCTTGTGTGCAAGCATGCAAGTAC ACTTTCTGGCTCAGTAATCCGTATCTCCTTTTCGCAGTTACAGAATATATGA |