| Microexon ID | Ps_NC_039365.1:145945757-145945770:- |
| Species | Papaver somniferum | Coordinates | NC_039365.1:145945757..145945770 |
| Microexon Cluster ID | MEP38 |
| Size | 14 |
| Phase | 1 |
| Pfam Domain Motif | Myosin_head |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 46,14,48 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | CAYTTYARTRMAACTGGRAARATATSTGGTGCYAADATTCAAACWTTTYTRCTTGARAAGTCWAGAGTWGTYCARYKTGCWGAWGGWGARAGRTCATAYCATATWTTT |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 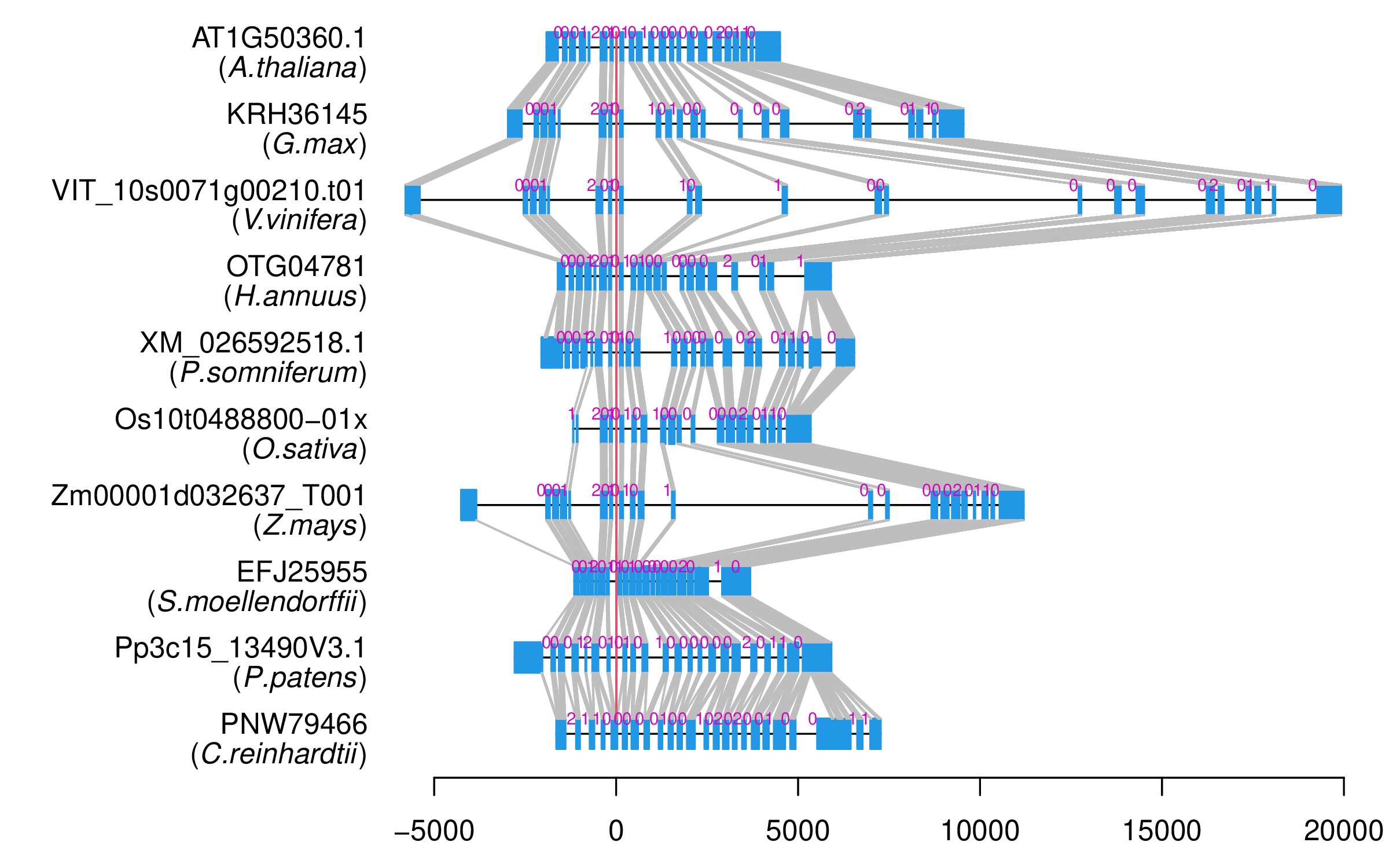 |
| Microexon DNA seq | TTCTACTTGAAAAG |
| Microexon Amino Acid seq | FLLEK |
| Microexon-tag DNA Seq | CACTTCAGTGAGACTGGGAAAATATCTGGTGCCAAGATTCAAACATTTCTACTTGAAAAGTCAAGGGTCGTCCAGTGTGCAGATGGAGAAAGATCGTACCATATATTT |
| Microexon-tag Amino Acid Seq | HFSETGKISGAKIQTFLLEKSRVVQCADGERSYHIF |
| Microexon-tag spanning region | 145945625-145945942 |
| Microexon-tag prediction score | 0.9842 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026552391.1x |
| Reference Transcript ID | XM_026552391.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026552391.1 |
| Protein ID | XP_026408176.1 |
| Gene ID | LOC113303361 |
| Gene Name | NA |
| Pfam domain motif | Myosin_head |
| Motif E-value | 1.6e-243 |
| Motif start | 183 |
| Motif end | 841 |
| Protein seq | >XP_026408176.1 MPQKPISSKKMPKKPPSKPRVPPSLQSIKSLPGDFRYIDSATGTSDGTNGGNNRMMASESIPENDDLTDSNMEVINEESP YSNGTISVEEVPSEGNNGCMGSVKSGLPALSPSHNENRWSDTSSYSGKKKLQYWCQLPNGNWALGKIVSTSGTESIISLN EGEVLKVNAESLLPANPDILDGVDNLMQLSYLHEPSVLYNLQYRYNQDMIYTKAGPVLVAINPFKKVPLYGNDYIEAYRR KSTDSPHVYAITDTAIREMTRDEVNQSIIISGESGAGKTETAKIAMQYLAALGGGSGIENEILKTNPILEAFGNAKTSRN DNSSRFGKLIEIHFSETGKISGAKIQTFLLEKSRVVQCADGERSYHIFYQLCAGATPALKEKLNLKHANDYNYLRQSNCY TIAGVDDAERFRLVMEALDIVHVTKKDQESVFAMLTAVLWLGNISFAVVDNENHVEPVADEGLETVAKLIGCEVQELNLA LSTRNMKVGNDNIVQKLSLSQAVDTRDALAKSLYACLFEWLVDQVNKSLEVGKRRTGRSISILDIYGFESFDKNSFEQFC INYANERLQQHFNRHLFKLEQEEYINDGIDWAKVDFEDNQDCLNLFEKKPLGLLSLLDEESTFPNGTDITLANKLKQHLS SNSCFRGDRGKAFSVSHYAGEVTYETSGFLEKNRDLLHLDSIQLLSSCKCQLPQIFASSMLKQSEKQVVGPLYRSGGADS QKLSVATKFKGQLFQLMQRLENTTPHFIRCIKPNSLQRPGTYEQGLVLQQLRCCGVLEVVRISRSGFPTRVTHLKFARRY GFLLLESVASQDPLSVSVAILHQFKILPEMYQVGYTKLFFRTGQIGVLEDTRNHTLHGILRVQSCFRGHQARSYLKELKR GILTLQSFIRGEKIRKEYEILVQKHKAAKVIQLHVKGKVSRKDFVNIRDASLVIQSVIRGWLVRRCSGDINLLTYTTKPE GTKAPDEVLVKASTLAELQRRVLKAEAALREKEDENDILQQRLHQYENRWAEYEVKMKSMEEVWQKQMKSLQSSLSVAKK SLAVDDADRNSDASTNMVDNGEYSWDLGSRNTTSRDSNGARSAPRGMNREMNTGLSVISRLAEEFEQRSQVFGDDAKFLV EVKSGQAEASLDPDRELRRLKQIFETWKKDYGNRLRETKVILHKLGNEEGSADKQVRKKWWARRNSMRIN* |
| CDS seq | >XM_026552391.1 ATGCCTCAGAAGCCAATTTCTTCTAAGAAAATGCCCAAGAAGCCGCCTTCAAAACCCCGGGTTCCACCTTCGTTACAGTC AATTAAGTCATTGCCTGGTGATTTTAGGTATATTGATTCAGCTACAGGTACGTCTGATGGCACAAATGGAGGAAATAACC GAATGATGGCTTCTGAGAGTATTCCCGAAAATGATGATTTGACTGACAGCAATATGGAAGTGATTAATGAAGAATCGCCA TATAGTAATGGCACCATTTCTGTTGAAGAGGTGCCATCTGAAGGGAATAATGGGTGCATGGGTTCCGTAAAATCAGGCTT GCCGGCTTTATCACCTTCCCATAATGAAAATAGGTGGAGTGACACAAGCTCTTACTCGGGGAAGAAGAAGCTCCAATATT GGTGTCAACTACCAAATGGCAACTGGGCGTTGGGGAAGATAGTGTCAACTTCAGGGACGGAGTCTATTATTTCACTTAAT GAAGGAGAGGTTTTAAAAGTAAATGCCGAAAGTCTTTTACCTGCAAATCCTGACATCCTTGATGGTGTAGACAATCTCAT GCAGCTTAGTTATTTACATGAACCTTCGGTCCTGTACAATCTACAATACAGATACAACCAAGATATGATCTATACTAAAG CCGGACCTGTTTTGGTTGCCATCAACCCTTTTAAAAAAGTCCCACTATATGGAAATGATTATATTGAAGCATATCGGCGC AAATCAACTGATAGTCCACATGTCTATGCTATCACCGACACAGCAATTAGGGAGATGACAAGAGATGAAGTAAACCAGTC CATCATTATAAGCGGTGAAAGTGGTGCAGGAAAAACTGAAACAGCAAAGATAGCCATGCAATACTTGGCTGCTCTTGGAG GGGGTAGTGGAATAGAGAATGAAATACTGAAAACTAATCCCATTTTGGAAGCTTTTGGTAATGCAAAAACATCAAGGAAT GATAACTCAAGTCGTTTTGGTAAATTAATTGAAATTCACTTCAGTGAGACTGGGAAAATATCTGGTGCCAAGATTCAAAC ATTTCTACTTGAAAAGTCAAGGGTCGTCCAGTGTGCAGATGGAGAAAGATCGTACCATATATTTTATCAGCTATGCGCTG GGGCTACCCCCGCTCTTAAAGAAAAACTGAATCTGAAGCATGCAAATGATTATAACTATTTGAGGCAGAGCAACTGCTAT ACCATTGCTGGAGTAGATGATGCCGAACGGTTTCGCTTGGTTATGGAAGCTCTAGATATAGTACATGTTACCAAGAAGGA TCAGGAGAGTGTGTTCGCCATGCTTACAGCAGTATTGTGGCTGGGGAACATCTCCTTTGCGGTGGTGGATAACGAAAATC ACGTTGAACCTGTGGCAGATGAAGGCCTAGAAACGGTTGCCAAATTGATCGGCTGTGAAGTTCAGGAGTTAAACCTAGCT TTGTCAACTCGCAACATGAAAGTTGGCAATGACAACATTGTCCAAAAACTTTCGTTATCTCAGGCAGTTGATACAAGAGA CGCATTGGCAAAATCACTGTATGCTTGTTTGTTTGAGTGGCTGGTAGACCAAGTTAACAAGTCACTGGAAGTAGGCAAGC GGCGTACAGGCAGATCCATCAGTATTCTTGATATCTATGGATTTGAATCTTTTGATAAGAATAGCTTCGAGCAGTTTTGC ATAAACTACGCAAATGAGAGATTACAGCAACACTTCAATCGGCATTTGTTTAAGTTAGAACAAGAGGAATATATCAATGA CGGAATTGACTGGGCAAAGGTTGACTTTGAAGACAACCAAGACTGTCTGAATCTTTTTGAGAAGAAACCACTGGGTCTAC TGTCTCTGCTGGACGAGGAGTCTACTTTTCCAAATGGAACTGATATAACTTTGGCCAACAAGCTTAAGCAGCACTTGAGT TCAAATTCCTGTTTCAGAGGAGATCGGGGCAAAGCTTTCAGTGTTAGCCATTATGCTGGAGAGGTTACATACGAAACATC TGGTTTTTTGGAGAAGAACAGAGATTTACTGCATTTAGACTCTATCCAACTTCTGTCATCCTGCAAGTGCCAACTTCCTC AGATTTTTGCATCCAGTATGCTTAAACAATCTGAAAAGCAAGTAGTGGGTCCATTGTACAGATCAGGTGGAGCAGATTCC CAAAAGCTAAGTGTTGCAACAAAGTTTAAGGGTCAACTGTTCCAACTTATGCAACGACTGGAGAACACAACTCCACACTT CATACGCTGTATTAAGCCAAACAGCTTGCAGCGTCCTGGAACATATGAACAAGGTCTTGTATTGCAGCAGCTGAGGTGTT GTGGAGTCTTAGAGGTCGTTCGCATATCTAGATCCGGCTTTCCTACCAGGGTTACTCACCTAAAATTTGCAAGAAGGTAT GGCTTTCTTCTTCTGGAGAGTGTTGCTTCTCAGGATCCGCTTAGTGTTTCAGTTGCAATTCTTCATCAATTTAAAATTCT TCCAGAGATGTATCAAGTTGGCTACACCAAATTGTTTTTCCGAACTGGACAGATTGGTGTTCTCGAGGATACAAGAAACC ATACCCTACATGGCATTTTACGGGTGCAGAGTTGTTTCAGAGGCCACCAGGCTCGGTCTTATCTCAAAGAGCTAAAAAGA GGAATTTTGACACTTCAGTCATTCATTCGGGGTGAGAAAATCAGAAAAGAGTATGAGATTCTGGTACAGAAACATAAAGC TGCCAAGGTAATACAACTACATGTGAAAGGCAAGGTTTCCAGGAAAGACTTCGTTAATATTCGAGATGCGTCATTAGTGA TACAGTCAGTTATTCGCGGTTGGTTAGTCAGAAGGTGTTCTGGAGACATAAACTTACTGACCTATACAACGAAACCTGAA GGCACTAAGGCACCAGATGAAGTTTTGGTCAAGGCATCAACTCTCGCTGAACTACAACGGAGAGTACTTAAAGCCGAAGC AGCTTTAAGAGAGAAAGAAGACGAGAATGACATCCTCCAACAACGGCTCCATCAGTACGAAAATCGGTGGGCAGAGTACG AAGTTAAAATGAAATCTATGGAAGAAGTGTGGCAGAAGCAGATGAAATCACTACAGTCCAGTCTCTCCGTTGCAAAGAAA AGCCTTGCTGTAGATGATGCTGACAGAAACTCTGATGCCTCAACAAATATGGTTGATAATGGAGAATATAGTTGGGACCT CGGAAGTAGAAATACCACTAGCCGTGACAGTAATGGAGCAAGATCTGCTCCGCGAGGTATGAATAGAGAAATGAATACAG GATTAAGTGTGATAAGTCGCTTGGCTGAGGAATTTGAGCAACGAAGTCAAGTATTTGGTGATGATGCGAAGTTCTTAGTG GAGGTAAAATCTGGTCAGGCAGAAGCTAGTCTGGATCCTGACCGCGAGTTAAGAAGATTGAAGCAGATTTTTGAAACTTG GAAGAAGGATTATGGGAATAGACTGCGGGAGACAAAGGTAATTCTTCACAAACTTGGGAATGAGGAAGGGAGTGCTGATA AGCAAGTGAGGAAGAAGTGGTGGGCAAGGAGGAACAGCATGAGGATAAATTAG |
| Microexon DNA seq | TTCTACTTGAAAAG |
| Microexon Amino Acid seq | FLLEK |
| Microexon-tag DNA Seq | CACTTCAGTGAGACTGGGAAAATATCTGGTGCCAAGATTCAAACATTTCTACTTGAAAAGTCAAGGGTCGTCCAGTGTGCAGATGGAGAAAGATCGTACCATATATTT |
| Microexon-tag Amino Acid seq | HFSETGKISGAKIQTFLLEKSRVVQCADGERSYHIF |
| Transcript ID | Ps.51798.1 |
| Gene ID | Ps.51798 |
| Gene Name | NA |
| Pfam domain motif | Myosin_head |
| Motif E-value | 2.7e-119 |
| Motif start | 183 |
| Motif end | 501 |
| Protein seq | >Ps.51798.1 MPQKPISSKKMPKKPPSKPRVPPSLQSIKSLPGDFRYIDSATGTSDGTNGGNNRMMASESIPENDDLTDSNMEVINEESP YSNGTISVEEVPSEGNNGCMGSVKSGLPALSPSHNENRWSDTSSYSGKKKLQYWCQLPNGNWALGKIVSTSGTESIISLN EGEVLKVNAESLLPANPDILDGVDNLMQLSYLHEPSVLYNLQYRYNQDMIYTKAGPVLVAINPFKKVPLYGNDYIEAYRR KSTDSPHVYAITDTAIREMTRDEVNQSIIISGESGAGKTETAKIAMQYLAALGGGSGIENEILKTNPILEAFGNAKTSRN DNSSRFGKLIEIHFSETGKISGAKIQTFLLEKSRVVQCADGERSYHIFYQLCAGATPALKEKLNLKHANDYNYLRQSNCY TIAGVDDAERFRLVMEALDIVHVTKKDQESVFAMLTAVLWLGNISFAVVDNENHVEPVADEGLETVAKLIGCEVQELNLA LSTRNMKVGNDNIVQKLSLSQKNSFEQFCINYANERLQQHFNRHLFKLEQEEYINDGIDWAKVDFEDNQDCLNLFEKKPL GLLSLLDEESTFPNGTDITLANKLKQHLSSNSCFRGDRGKAFSVSHYAGEVTYETSGFLEKNRDLLHLDSIQLLSSCKCQ LPQIFASSMLKQSEKQVVGPLYRSGGADSQKLSVATKFKGQLFQLMQRLENTTPHFIRCIKPNSLQRPGTYEQGLVLQQL RCCGVLEVVRISRSGFPTRVTHLKFARRYGFLLLESVASQDPLSVSVAILHQFKILPEMYQVGYTKLFFRTGQIGVLEDT RNHTLHGILRVQSCFRGHQARSYLKELKRGILTLQSFIRGEKIRKEYEILVQKHKAAKVIQLHVKGKVSRKDFVNIRDAS LVIQSVIRGWLVRRCSGDINLLTYTTKPEGTKVCKMLLNGKEILFSGFGYQT* |
| CDS seq | >Ps.51798.1 ATGCCTCAGAAGCCAATTTCTTCTAAGAAAATGCCCAAGAAGCCGCCTTCAAAACCCCGGGTTCCACCTTCGTTACAGTC AATTAAGTCATTGCCTGGTGATTTTAGGTATATTGATTCAGCTACAGGTACGTCTGATGGCACAAATGGAGGAAATAACC GAATGATGGCTTCTGAGAGTATTCCCGAAAATGATGATTTGACTGACAGCAATATGGAAGTGATTAATGAAGAATCGCCA TATAGTAATGGCACCATTTCTGTTGAAGAGGTGCCATCTGAAGGGAATAATGGGTGCATGGGTTCCGTAAAATCAGGCTT GCCGGCTTTATCACCTTCCCATAATGAAAATAGGTGGAGTGACACAAGCTCTTACTCGGGGAAGAAGAAGCTCCAATATT GGTGTCAACTACCAAATGGCAACTGGGCGTTGGGGAAGATAGTGTCAACTTCAGGGACGGAGTCTATTATTTCACTTAAT GAAGGAGAGGTTTTAAAAGTAAATGCCGAAAGTCTTTTACCTGCAAATCCTGACATCCTTGATGGTGTAGACAATCTCAT GCAGCTTAGTTATTTACATGAACCTTCGGTCCTGTACAATCTACAATACAGATACAACCAAGATATGATCTATACTAAAG CCGGACCTGTTTTGGTTGCCATCAACCCTTTTAAAAAAGTCCCACTATATGGAAATGATTATATTGAAGCATATCGGCGC AAATCAACTGATAGTCCACATGTCTATGCTATCACCGACACAGCAATTAGGGAGATGACAAGAGATGAAGTAAACCAGTC CATCATTATAAGCGGTGAAAGTGGTGCAGGAAAAACTGAAACAGCAAAGATAGCCATGCAATACTTGGCTGCTCTTGGAG GGGGTAGTGGAATAGAGAATGAAATACTGAAAACTAATCCCATTTTGGAAGCTTTTGGTAATGCAAAAACATCAAGGAAT GATAACTCAAGTCGTTTTGGTAAATTAATTGAAATTCACTTCAGTGAGACTGGGAAAATATCTGGTGCCAAGATTCAAAC ATTTCTACTTGAAAAGTCAAGGGTCGTCCAGTGTGCAGATGGAGAAAGATCGTACCATATATTTTATCAGCTATGCGCTG GGGCTACCCCCGCTCTTAAAGAAAAACTGAATCTGAAGCATGCAAATGATTATAACTATTTGAGGCAGAGCAACTGCTAT ACCATTGCTGGAGTAGATGATGCCGAACGGTTTCGCTTGGTTATGGAAGCTCTAGATATAGTACATGTTACCAAGAAGGA TCAGGAGAGTGTGTTCGCCATGCTTACAGCAGTATTGTGGCTGGGGAACATCTCCTTTGCGGTGGTGGATAACGAAAATC ACGTTGAACCTGTGGCAGATGAAGGCCTAGAAACGGTTGCCAAATTGATCGGCTGTGAAGTTCAGGAGTTAAACCTAGCT TTGTCAACTCGCAACATGAAAGTTGGCAATGACAACATTGTCCAAAAACTTTCGTTATCTCAGAAGAATAGCTTCGAGCA GTTTTGCATAAACTACGCAAATGAGAGATTACAGCAACACTTCAATCGGCATTTGTTTAAGTTAGAACAAGAGGAATATA TCAATGACGGAATTGACTGGGCAAAGGTTGACTTTGAAGACAACCAAGACTGTCTGAATCTTTTTGAGAAGAAACCACTG GGTCTACTGTCTCTGCTGGACGAGGAGTCTACTTTTCCAAATGGAACTGATATAACTTTGGCCAACAAGCTTAAGCAGCA CTTGAGTTCAAATTCCTGTTTCAGAGGAGATCGGGGCAAAGCTTTCAGTGTTAGCCATTATGCTGGAGAGGTTACATACG AAACATCTGGTTTTTTGGAGAAGAACAGAGATTTACTGCATTTAGACTCTATCCAACTTCTGTCATCCTGCAAGTGCCAA CTTCCTCAGATTTTTGCATCCAGTATGCTTAAACAATCTGAAAAGCAAGTAGTGGGTCCATTGTACAGATCAGGTGGAGC AGATTCCCAAAAGCTAAGTGTTGCAACAAAGTTTAAGGGTCAACTGTTCCAACTTATGCAACGACTGGAGAACACAACTC CACACTTCATACGCTGTATTAAGCCAAACAGCTTGCAGCGTCCTGGAACATATGAACAAGGTCTTGTATTGCAGCAGCTG AGGTGTTGTGGAGTCTTAGAGGTCGTTCGCATATCTAGATCCGGCTTTCCTACCAGGGTTACTCACCTAAAATTTGCAAG AAGGTATGGCTTTCTTCTTCTGGAGAGTGTTGCTTCTCAGGATCCGCTTAGTGTTTCAGTTGCAATTCTTCATCAATTTA AAATTCTTCCAGAGATGTATCAAGTTGGCTACACCAAATTGTTTTTCCGAACTGGACAGATTGGTGTTCTCGAGGATACA AGAAACCATACCCTACATGGCATTTTACGGGTGCAGAGTTGTTTCAGAGGCCACCAGGCTCGGTCTTATCTCAAAGAGCT AAAAAGAGGAATTTTGACACTTCAGTCATTCATTCGGGGTGAGAAAATCAGAAAAGAGTATGAGATTCTGGTACAGAAAC ATAAAGCTGCCAAGGTAATACAACTACATGTGAAAGGCAAGGTTTCCAGGAAAGACTTCGTTAATATTCGAGATGCGTCA TTAGTGATACAGTCAGTTATTCGCGGTTGGTTAGTCAGAAGGTGTTCTGGAGACATAAACTTACTGACCTATACAACGAA ACCTGAAGGCACTAAGGTATGTAAAATGTTACTAAACGGAAAAGAAATCTTGTTCTCTGGTTTTGGTTACCAGACGTAG |