| Microexon ID | Gm_6:43334786-43334799:+ |
| Species | Glycine max | Coordinates | 6:43334786..43334799 |
| Microexon Cluster ID | MEP38 |
| Size | 14 |
| Phase | 1 |
| Pfam Domain Motif | Myosin_head |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 46,14,48 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | CAYTTYARTRMAACTGGRAARATATSTGGTGCYAADATTCAAACWTTTYTRCTTGARAAGTCWAGAGTWGTYCARYKTGCWGAWGGWGARAGRTCATAYCATATWTTT |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 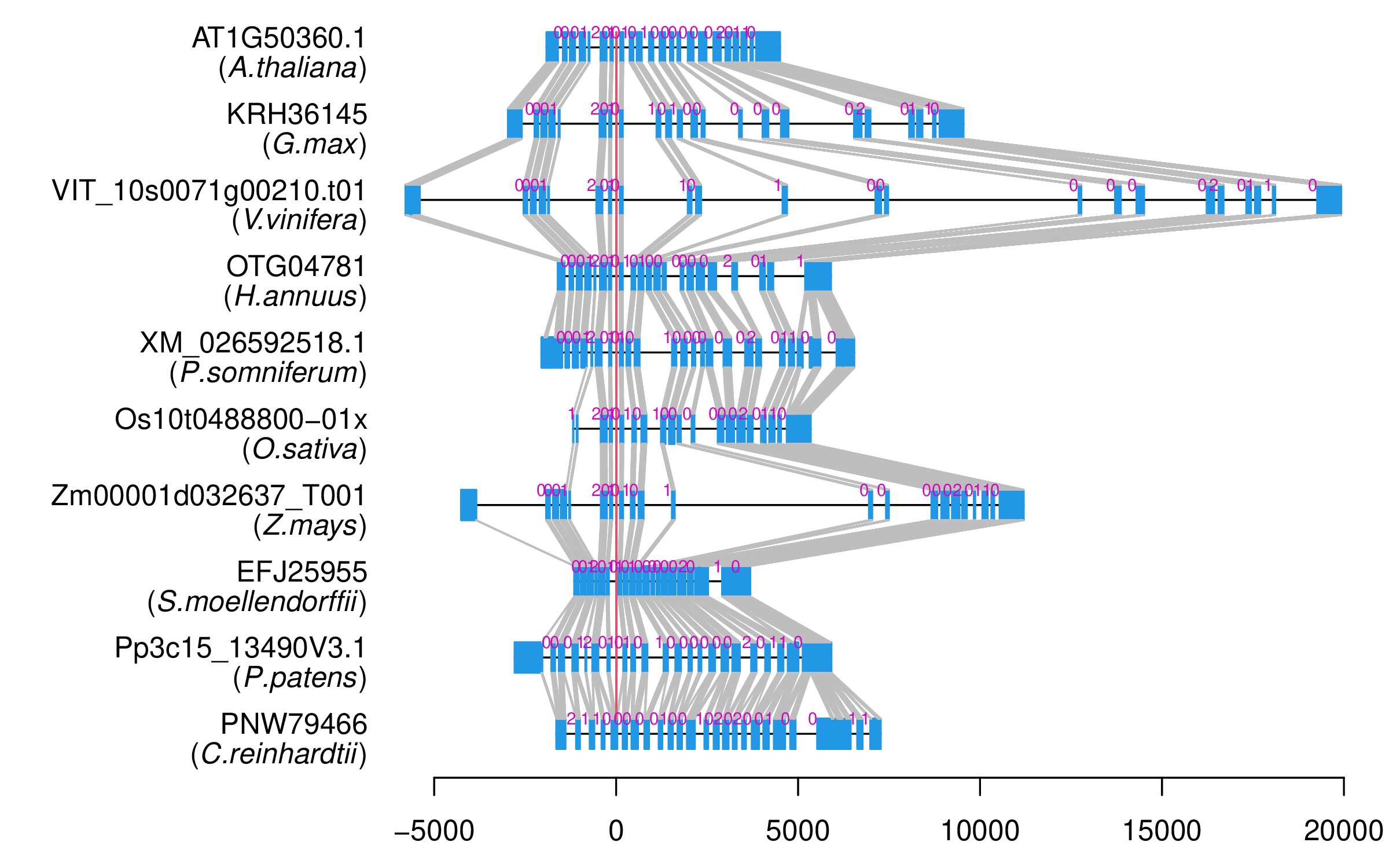 |
| Microexon DNA seq | TAATGTTAGAAAAG |
| Microexon Amino Acid seq | LMLEK |
| Microexon-tag DNA Seq | CATTTCAGCTCCATGGGTAAAATATGTGGGGCTAAAATTCAAACCTTAATGTTAGAAAAGTCTAGAGTTGTTCAACTGGCCAATGGTGAGAGATCATATCACATATTT |
| Microexon-tag Amino Acid Seq | HFSSMGKICGAKIQTLMLEKSRVVQLANGERSYHIF |
| Microexon-tag spanning region | 43334603-43334936 |
| Microexon-tag prediction score | 0.9405 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | KRH55425x |
| Reference Transcript ID | KRH55425 |
| Gene ID | GLYMA_06G254500 |
| Gene Name | NA |
| Transcript ID | KRH55425 |
| Protein ID | KRH55425 |
| Gene ID | GLYMA_06G254500 |
| Gene Name | NA |
| Pfam domain motif | Myosin_head |
| Motif E-value | 1e-218 |
| Motif start | 187 |
| Motif end | 828 |
| Protein seq | >KRH55425 MVLSASPCSLARSSLEEMLDSLRRRDEEEERKKDSPPALPARPASRARLPPARRSLPNNFKVSGSELAVAPEHGAGTNGE NDLGQKRRRNGFGSKRVNKDVESPYVELSSSDSSGMIWELEGDDSVSYFIKKKLRVWSRQPRGQWELGTIQSTSGEEASI SLSNGNVMKVVRSEILPANPDVLEGADDLNKLCYLNEPSVLHNLKLRYSQGMIYSKAGPILIALNPFKDLQTYGNDSVSA YRQRIIDSPHVYAVADTAYNKVIRDEVNQSIIISGESGSGKTETAKIALQYLAALGGGGSCAIENEFLQINRILEAFGNA KTSRNNNSSRFGKLIEVHFSSMGKICGAKIQTLMLEKSRVVQLANGERSYHIFYQLCTGSSSGLKERLNLRAVSEYKYLV QSDCTLIDGVNDANNFHQLMKALDTVQICKEDQEMIFKMLAAILWLGNISFQVDSENHIEVVDDEAVTSTAQLMGCSSQE LMTALCTLKTQFDEDTIAKNLTLRQATERRDAIAKFIYASLFDWLVEQVNKSLEVGKPHTGKSISILDIYGFQTFQKNSF EQFYINYANERIQQHFNRHLFKLEQEDYELDGVDWTKVDFEDNEGCLDLFEKKPHGLFSLLDEESNLAKASDLTFANKLR HHLGANPCFKGERGRAFRVRHYAGEVLYDTNDFLEKNRDTLSSDSIQFLSSCNCELLQLLSKMFNQSQKQSVATKFKVQL FKLMQKLESTTPHFIRCIKPNSKDLPGIFDEGLVLQQLRCCEVLEVVRLSRAGYPIRMGHQEFSRRYGFLLSEANISQDP LSISVAVLQKFYIPYEMYHVGYTKLYLRAGQIDALENKRKQVLQGILEIQKCFRGHQARGYFCELKNGMTTLQSFIRGEN TRRRYGVMVKSSITIYSRKLEEIHAIILLQSVIRGWLVRRDASHVNRSKRYPENAKPRRKSFMKIIPEVKDLSKEPVQNL LSALAGLQRRVDKADAIVEQKEEENTELREQLRQSERKRIEYETKMKSMEEAWQKQMASLQMSLVAARKSLAPENATVQP VRRDFVLPRGYDSEDATSMGSQTPGGSTPMLSGSLSVSDAGRQVNGTLTTVGNLMKEFEQQRQNFDDEVKALNEVKPEQS ANMNSFEELRKLKQKFEGWKNQYKVRLRETKTRLYKSETEKSRRSWWGKFSSKA* |
| CDS seq | >KRH55425 ATGGTGTTATCGGCTTCGCCATGTTCCTTGGCGAGAAGCTCGCTAGAGGAGATGCTCGATTCCCTTCGTCGGAGAGATGA GGAGGAGGAGAGGAAAAAGGACTCGCCGCCGGCGTTGCCCGCGAGGCCGGCCTCGCGGGCACGGCTTCCTCCGGCGCGGC GGTCGCTGCCGAACAACTTCAAGGTTAGCGGCAGCGAGCTCGCCGTCGCGCCAGAGCATGGAGCTGGGACTAACGGGGAG AATGATTTGGGGCAGAAAAGGAGAAGAAATGGTTTTGGGAGCAAGAGGGTGAATAAGGATGTGGAGTCTCCTTACGTGGA ACTTTCTTCCAGTGATTCATCTGGGATGATTTGGGAATTGGAGGGTGATGATAGCGTTTCTTATTTCATCAAAAAGAAGC TTCGTGTTTGGTCTAGGCAACCAAGAGGTCAGTGGGAACTAGGAACGATACAGTCAACTTCAGGAGAGGAAGCATCCATT TCACTCTCAAATGGAAATGTTATGAAAGTGGTCAGATCAGAGATTCTGCCAGCTAATCCTGATGTTTTGGAGGGTGCGGA TGATCTTAATAAACTTTGTTATTTGAACGAGCCATCGGTTCTTCACAATCTGAAGTTAAGATATTCTCAAGGAATGATTT ATAGTAAAGCAGGGCCAATTTTAATTGCACTCAATCCTTTCAAAGATCTTCAAACATATGGAAATGATTCTGTCTCAGCT TATAGGCAGAGAATTATTGATAGTCCTCATGTTTATGCTGTGGCAGATACGGCTTATAACAAGGTGATAAGAGATGAAGT AAATCAGTCCATTATCATAAGTGGCGAGAGTGGATCTGGGAAAACAGAAACAGCTAAAATTGCATTGCAGTACTTAGCTG CTCTTGGTGGTGGTGGAAGTTGTGCGATAGAAAATGAATTTCTTCAGATAAATCGTATACTAGAAGCTTTTGGGAATGCA AAAACATCTAGGAATAACAACTCTAGCAGATTTGGAAAGTTGATTGAAGTTCATTTCAGCTCCATGGGTAAAATATGTGG GGCTAAAATTCAAACCTTAATGTTAGAAAAGTCTAGAGTTGTTCAACTGGCCAATGGTGAGAGATCATATCACATATTTT ATCAACTTTGTACTGGATCTTCATCTGGTCTTAAAGAGAGACTGAATCTTAGAGCAGTCAGTGAATATAAATATCTAGTT CAGAGTGACTGCACGTTAATTGATGGTGTCAATGATGCTAACAACTTTCATCAGCTGATGAAAGCGCTGGATACTGTTCA AATTTGTAAAGAAGATCAAGAGATGATCTTTAAGATGCTCGCTGCAATACTATGGCTGGGAAATATATCATTCCAAGTAG ACAGTGAAAATCACATTGAGGTTGTTGATGATGAAGCTGTAACCAGTACTGCCCAGCTGATGGGTTGCAGTTCCCAGGAA TTAATGACAGCATTATGTACCCTTAAAACTCAATTTGACGAGGATACTATTGCCAAAAATTTGACATTGAGGCAGGCAAC TGAAAGAAGAGATGCAATTGCAAAATTCATCTATGCAAGCTTGTTTGACTGGCTTGTAGAACAAGTTAACAAGTCACTTG AAGTGGGTAAACCACATACTGGGAAATCCATAAGTATCCTTGATATTTATGGGTTTCAGACTTTCCAGAAAAACAGCTTT GAACAGTTTTATATAAATTATGCCAATGAGAGGATTCAACAACATTTTAATCGGCATCTATTTAAACTTGAGCAGGAGGA CTATGAATTGGATGGTGTTGATTGGACTAAGGTAGATTTTGAGGATAATGAAGGGTGCTTGGATCTTTTTGAGAAGAAAC CTCACGGTCTATTCTCTTTATTGGATGAGGAGTCAAATTTAGCCAAGGCTTCTGATTTAACATTTGCCAACAAACTTAGG CACCACCTGGGTGCTAATCCTTGCTTCAAAGGAGAAAGAGGCAGAGCTTTCCGTGTTCGTCATTATGCAGGGGAGGTTCT GTATGATACAAATGACTTTCTGGAAAAAAATAGAGACACGTTGTCTTCTGATTCCATTCAATTCCTGTCATCCTGTAACT GTGAACTGCTGCAATTGCTTTCCAAAATGTTTAACCAGTCTCAAAAGCAGAGTGTTGCAACAAAGTTCAAGGTTCAATTG TTCAAGTTGATGCAGAAGTTGGAGAGCACCACACCTCACTTTATTCGCTGCATAAAGCCAAATAGTAAGGATCTTCCTGG AATTTTTGATGAAGGCCTTGTCCTACAACAGCTCAGGTGTTGTGAAGTTCTAGAAGTTGTTAGACTTTCAAGGGCTGGAT ATCCTATTCGAATGGGCCATCAAGAGTTTTCCAGAAGGTATGGGTTTCTGCTTTCTGAGGCCAACATATCGCAAGATCCA TTGAGCATCTCGGTTGCTGTTTTGCAAAAATTTTATATCCCTTATGAAATGTACCATGTTGGCTACACCAAATTGTATCT TCGAGCAGGGCAGATTGATGCACTGGAGAATAAGAGAAAACAGGTTTTGCAGGGAATACTTGAGATTCAAAAATGCTTCC GTGGTCATCAAGCTCGTGGTTATTTCTGTGAACTTAAGAATGGAATGACAACATTACAATCATTTATTCGTGGAGAAAAT ACAAGAAGGAGATATGGTGTTATGGTGAAGTCTTCAATAACAATTTATTCTAGAAAACTGGAGGAGATCCATGCAATCAT ACTATTACAATCTGTAATTCGAGGTTGGCTGGTAAGAAGGGATGCTAGTCATGTAAATAGGTCTAAGAGATATCCTGAAA ATGCTAAACCTAGGCGAAAGTCCTTTATGAAGATAATACCAGAAGTAAAGGACTTGTCCAAAGAGCCGGTTCAGAATCTG CTTTCAGCTTTAGCAGGACTCCAAAGGCGGGTTGACAAGGCTGATGCAATTGTGGAGCAAAAGGAAGAAGAAAATACTGA ATTGAGGGAACAGCTAAGACAATCTGAGAGGAAGAGGATAGAATATGAGACAAAAATGAAATCAATGGAGGAGGCTTGGC AAAAACAGATGGCATCTTTGCAAATGAGTCTTGTTGCTGCTAGAAAGAGCCTTGCTCCTGAGAATGCTACAGTTCAGCCT GTAAGACGTGATTTTGTGTTGCCTCGTGGTTATGATTCTGAAGATGCTACTTCCATGGGATCTCAAACACCTGGTGGGAG CACACCAATGCTTTCTGGTAGTCTATCTGTCTCTGATGCTGGGAGACAGGTCAATGGTACTTTGACCACAGTTGGCAATC TGATGAAGGAATTCGAGCAGCAAAGACAGAACTTTGATGATGAAGTAAAAGCTTTGAATGAGGTTAAACCGGAGCAGTCT GCCAATATGAATTCCTTTGAAGAACTTCGGAAACTTAAACAGAAATTTGAGGGATGGAAGAATCAATACAAGGTTAGATT ACGCGAGACTAAAACAAGGCTTTATAAATCAGAAACGGAAAAAAGTCGGCGATCATGGTGGGGGAAGTTCAGCTCAAAAG CATAA |
| Microexon DNA seq | TAATGTTAGAAAAG |
| Microexon Amino Acid seq | LMLEK |
| Microexon-tag DNA Seq | CATTTCAGCTCCATGGGTAAAATATGTGGGGCTAAAATTCAAACCTTAATGTTAGAAAAGTCTAGAGTTGTTCAACTGGCCAATGGTGAGAGATCATATCACATATTT |
| Microexon-tag Amino Acid seq | HFSSMGKICGAKIQTLMLEKSRVVQLANGERSYHIF |
| Transcript ID | KRH55425 |
| Gene ID | Gm.44802 |
| Gene Name | NA |
| Pfam domain motif | Myosin_head |
| Motif E-value | 1e-218 |
| Motif start | 187 |
| Motif end | 828 |
| Protein seq | >KRH55425 MVLSASPCSLARSSLEEMLDSLRRRDEEEERKKDSPPALPARPASRARLPPARRSLPNNFKVSGSELAVAPEHGAGTNGE NDLGQKRRRNGFGSKRVNKDVESPYVELSSSDSSGMIWELEGDDSVSYFIKKKLRVWSRQPRGQWELGTIQSTSGEEASI SLSNGNVMKVVRSEILPANPDVLEGADDLNKLCYLNEPSVLHNLKLRYSQGMIYSKAGPILIALNPFKDLQTYGNDSVSA YRQRIIDSPHVYAVADTAYNKVIRDEVNQSIIISGESGSGKTETAKIALQYLAALGGGGSCAIENEFLQINRILEAFGNA KTSRNNNSSRFGKLIEVHFSSMGKICGAKIQTLMLEKSRVVQLANGERSYHIFYQLCTGSSSGLKERLNLRAVSEYKYLV QSDCTLIDGVNDANNFHQLMKALDTVQICKEDQEMIFKMLAAILWLGNISFQVDSENHIEVVDDEAVTSTAQLMGCSSQE LMTALCTLKTQFDEDTIAKNLTLRQATERRDAIAKFIYASLFDWLVEQVNKSLEVGKPHTGKSISILDIYGFQTFQKNSF EQFYINYANERIQQHFNRHLFKLEQEDYELDGVDWTKVDFEDNEGCLDLFEKKPHGLFSLLDEESNLAKASDLTFANKLR HHLGANPCFKGERGRAFRVRHYAGEVLYDTNDFLEKNRDTLSSDSIQFLSSCNCELLQLLSKMFNQSQKQSVATKFKVQL FKLMQKLESTTPHFIRCIKPNSKDLPGIFDEGLVLQQLRCCEVLEVVRLSRAGYPIRMGHQEFSRRYGFLLSEANISQDP LSISVAVLQKFYIPYEMYHVGYTKLYLRAGQIDALENKRKQVLQGILEIQKCFRGHQARGYFCELKNGMTTLQSFIRGEN TRRRYGVMVKSSITIYSRKLEEIHAIILLQSVIRGWLVRRDASHVNRSKRYPENAKPRRKSFMKIIPEVKDLSKEPVQNL LSALAGLQRRVDKADAIVEQKEEENTELREQLRQSERKRIEYETKMKSMEEAWQKQMASLQMSLVAARKSLAPENATVQP VRRDFVLPRGYDSEDATSMGSQTPGGSTPMLSGSLSVSDAGRQVNGTLTTVGNLMKEFEQQRQNFDDEVKALNEVKPEQS ANMNSFEELRKLKQKFEGWKNQYKVRLRETKTRLYKSETEKSRRSWWGKFSSKA* |
| CDS seq | >KRH55425 ATGGTGTTATCGGCTTCGCCATGTTCCTTGGCGAGAAGCTCGCTAGAGGAGATGCTCGATTCCCTTCGTCGGAGAGATGA GGAGGAGGAGAGGAAAAAGGACTCGCCGCCGGCGTTGCCCGCGAGGCCGGCCTCGCGGGCACGGCTTCCTCCGGCGCGGC GGTCGCTGCCGAACAACTTCAAGGTTAGCGGCAGCGAGCTCGCCGTCGCGCCAGAGCATGGAGCTGGGACTAACGGGGAG AATGATTTGGGGCAGAAAAGGAGAAGAAATGGTTTTGGGAGCAAGAGGGTGAATAAGGATGTGGAGTCTCCTTACGTGGA ACTTTCTTCCAGTGATTCATCTGGGATGATTTGGGAATTGGAGGGTGATGATAGCGTTTCTTATTTCATCAAAAAGAAGC TTCGTGTTTGGTCTAGGCAACCAAGAGGTCAGTGGGAACTAGGAACGATACAGTCAACTTCAGGAGAGGAAGCATCCATT TCACTCTCAAATGGAAATGTTATGAAAGTGGTCAGATCAGAGATTCTGCCAGCTAATCCTGATGTTTTGGAGGGTGCGGA TGATCTTAATAAACTTTGTTATTTGAACGAGCCATCGGTTCTTCACAATCTGAAGTTAAGATATTCTCAAGGAATGATTT ATAGTAAAGCAGGGCCAATTTTAATTGCACTCAATCCTTTCAAAGATCTTCAAACATATGGAAATGATTCTGTCTCAGCT TATAGGCAGAGAATTATTGATAGTCCTCATGTTTATGCTGTGGCAGATACGGCTTATAACAAGGTGATAAGAGATGAAGT AAATCAGTCCATTATCATAAGTGGCGAGAGTGGATCTGGGAAAACAGAAACAGCTAAAATTGCATTGCAGTACTTAGCTG CTCTTGGTGGTGGTGGAAGTTGTGCGATAGAAAATGAATTTCTTCAGATAAATCGTATACTAGAAGCTTTTGGGAATGCA AAAACATCTAGGAATAACAACTCTAGCAGATTTGGAAAGTTGATTGAAGTTCATTTCAGCTCCATGGGTAAAATATGTGG GGCTAAAATTCAAACCTTAATGTTAGAAAAGTCTAGAGTTGTTCAACTGGCCAATGGTGAGAGATCATATCACATATTTT ATCAACTTTGTACTGGATCTTCATCTGGTCTTAAAGAGAGACTGAATCTTAGAGCAGTCAGTGAATATAAATATCTAGTT CAGAGTGACTGCACGTTAATTGATGGTGTCAATGATGCTAACAACTTTCATCAGCTGATGAAAGCGCTGGATACTGTTCA AATTTGTAAAGAAGATCAAGAGATGATCTTTAAGATGCTCGCTGCAATACTATGGCTGGGAAATATATCATTCCAAGTAG ACAGTGAAAATCACATTGAGGTTGTTGATGATGAAGCTGTAACCAGTACTGCCCAGCTGATGGGTTGCAGTTCCCAGGAA TTAATGACAGCATTATGTACCCTTAAAACTCAATTTGACGAGGATACTATTGCCAAAAATTTGACATTGAGGCAGGCAAC TGAAAGAAGAGATGCAATTGCAAAATTCATCTATGCAAGCTTGTTTGACTGGCTTGTAGAACAAGTTAACAAGTCACTTG AAGTGGGTAAACCACATACTGGGAAATCCATAAGTATCCTTGATATTTATGGGTTTCAGACTTTCCAGAAAAACAGCTTT GAACAGTTTTATATAAATTATGCCAATGAGAGGATTCAACAACATTTTAATCGGCATCTATTTAAACTTGAGCAGGAGGA CTATGAATTGGATGGTGTTGATTGGACTAAGGTAGATTTTGAGGATAATGAAGGGTGCTTGGATCTTTTTGAGAAGAAAC CTCACGGTCTATTCTCTTTATTGGATGAGGAGTCAAATTTAGCCAAGGCTTCTGATTTAACATTTGCCAACAAACTTAGG CACCACCTGGGTGCTAATCCTTGCTTCAAAGGAGAAAGAGGCAGAGCTTTCCGTGTTCGTCATTATGCAGGGGAGGTTCT GTATGATACAAATGACTTTCTGGAAAAAAATAGAGACACGTTGTCTTCTGATTCCATTCAATTCCTGTCATCCTGTAACT GTGAACTGCTGCAATTGCTTTCCAAAATGTTTAACCAGTCTCAAAAGCAGAGTGTTGCAACAAAGTTCAAGGTTCAATTG TTCAAGTTGATGCAGAAGTTGGAGAGCACCACACCTCACTTTATTCGCTGCATAAAGCCAAATAGTAAGGATCTTCCTGG AATTTTTGATGAAGGCCTTGTCCTACAACAGCTCAGGTGTTGTGAAGTTCTAGAAGTTGTTAGACTTTCAAGGGCTGGAT ATCCTATTCGAATGGGCCATCAAGAGTTTTCCAGAAGGTATGGGTTTCTGCTTTCTGAGGCCAACATATCGCAAGATCCA TTGAGCATCTCGGTTGCTGTTTTGCAAAAATTTTATATCCCTTATGAAATGTACCATGTTGGCTACACCAAATTGTATCT TCGAGCAGGGCAGATTGATGCACTGGAGAATAAGAGAAAACAGGTTTTGCAGGGAATACTTGAGATTCAAAAATGCTTCC GTGGTCATCAAGCTCGTGGTTATTTCTGTGAACTTAAGAATGGAATGACAACATTACAATCATTTATTCGTGGAGAAAAT ACAAGAAGGAGATATGGTGTTATGGTGAAGTCTTCAATAACAATTTATTCTAGAAAACTGGAGGAGATCCATGCAATCAT ACTATTACAATCTGTAATTCGAGGTTGGCTGGTAAGAAGGGATGCTAGTCATGTAAATAGGTCTAAGAGATATCCTGAAA ATGCTAAACCTAGGCGAAAGTCCTTTATGAAGATAATACCAGAAGTAAAGGACTTGTCCAAAGAGCCGGTTCAGAATCTG CTTTCAGCTTTAGCAGGACTCCAAAGGCGGGTTGACAAGGCTGATGCAATTGTGGAGCAAAAGGAAGAAGAAAATACTGA ATTGAGGGAACAGCTAAGACAATCTGAGAGGAAGAGGATAGAATATGAGACAAAAATGAAATCAATGGAGGAGGCTTGGC AAAAACAGATGGCATCTTTGCAAATGAGTCTTGTTGCTGCTAGAAAGAGCCTTGCTCCTGAGAATGCTACAGTTCAGCCT GTAAGACGTGATTTTGTGTTGCCTCGTGGTTATGATTCTGAAGATGCTACTTCCATGGGATCTCAAACACCTGGTGGGAG CACACCAATGCTTTCTGGTAGTCTATCTGTCTCTGATGCTGGGAGACAGGTCAATGGTACTTTGACCACAGTTGGCAATC TGATGAAGGAATTCGAGCAGCAAAGACAGAACTTTGATGATGAAGTAAAAGCTTTGAATGAGGTTAAACCGGAGCAGTCT GCCAATATGAATTCCTTTGAAGAACTTCGGAAACTTAAACAGAAATTTGAGGGATGGAAGAATCAATACAAGGTTAGATT ACGCGAGACTAAAACAAGGCTTTATAAATCAGAAACGGAAAAAAGTCGGCGATCATGGTGGGGGAAGTTCAGCTCAAAAG CATAA |