| Microexon ID | Gm_20:34589145-34589158:- |
| Species | Glycine max | Coordinates | 20:34589145..34589158 |
| Microexon Cluster ID | MEP38 |
| Size | 14 |
| Phase | 1 |
| Pfam Domain Motif | Myosin_head |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 46,14,48 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | CAYTTYARTRMAACTGGRAARATATSTGGTGCYAADATTCAAACWTTTYTRCTTGARAAGTCWAGAGTWGTYCARYKTGCWGAWGGWGARAGRTCATAYCATATWTTT |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 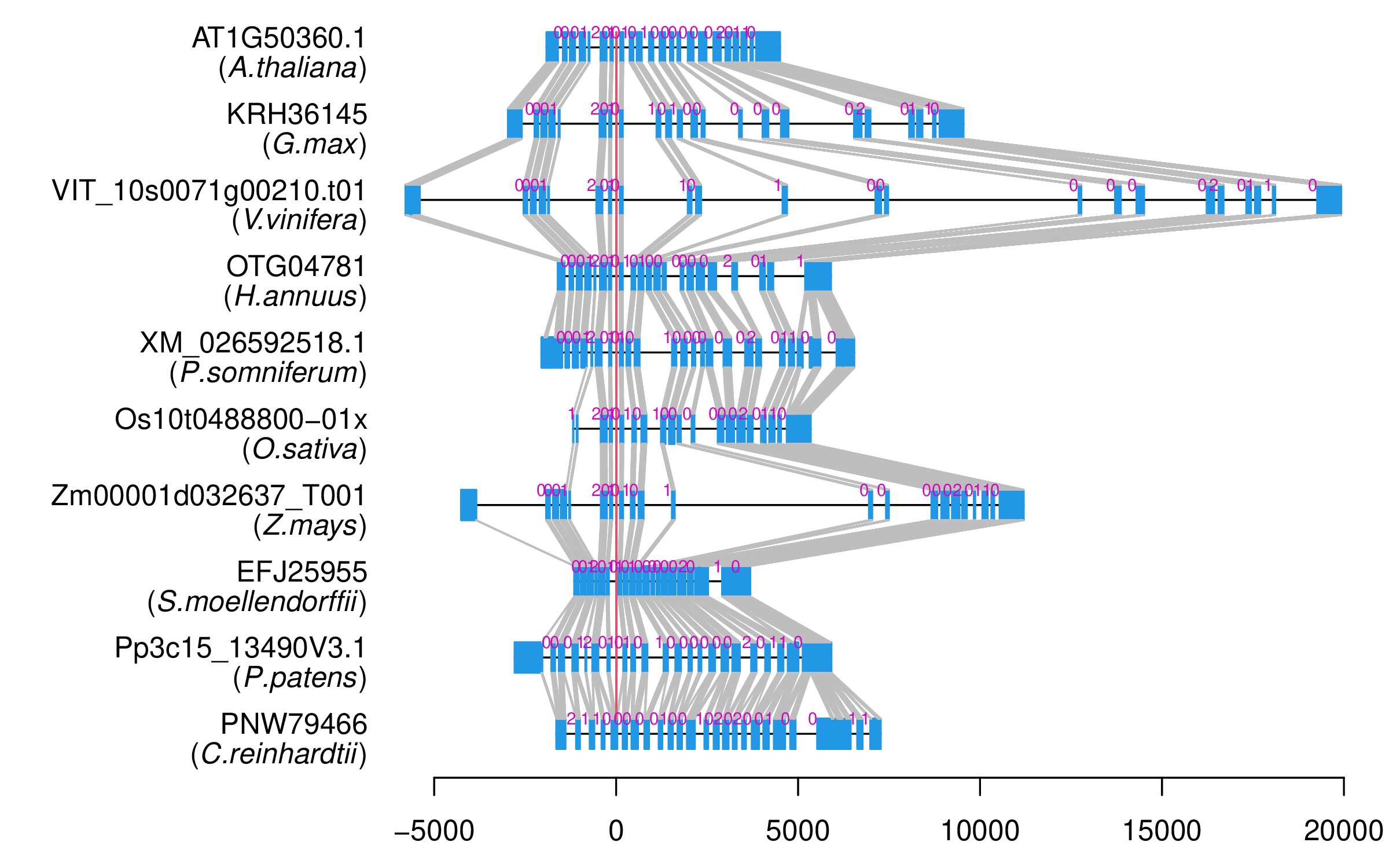 |
| Microexon DNA seq | TTTTGCTGGAAAAG |
| Microexon Amino Acid seq | FLLEK |
| Microexon-tag DNA Seq | CACTTCAGTGAAACTGGAAAAATATCTGGTGCTAATATTCAAACATTTTTGCTGGAAAAGTCTAGAGTAGTCCAATGCAACGAAGGGGAAAGGTCATATCATATATTT |
| Microexon-tag Amino Acid Seq | HFSETGKISGANIQTFLLEKSRVVQCNEGERSYHIF |
| Microexon-tag spanning region | 34589014-34589335 |
| Microexon-tag prediction score | 0.9799 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | KRG90612x |
| Reference Transcript ID | KRG90612 |
| Gene ID | GLYMA_20G102900 |
| Gene Name | NA |
| Transcript ID | KRG90612 |
| Protein ID | KRG90612 |
| Gene ID | GLYMA_20G102900 |
| Gene Name | NA |
| Pfam domain motif | Myosin_head |
| Motif E-value | 1.9e-245 |
| Motif start | 175 |
| Motif end | 833 |
| Protein seq | >KRG90612 MSQTSTVLPAFHSIKSLPPEFNPVLVEKHGDVKFRHTNPIGSNGLENGALVAEISKEVNCRAGGMDLFDEDSPYGGKGRS LKDRPSNADEDSVSVSLPLPSILTSSRESRWNDANPYGSKKKLQSWLQLPNGDWELVKIITTSGAESVISLPDGKVLKVK EESLVPANPDILDGVDDLMQLSYLNEPSVLFNLQYRYNHNMIYTKAGPVLVAVNPFKKVPLYGNDYIEAYKCKSIESPHV YAITDTAIQEMIRDEVNQSIIISGESGAGKTETAKIAMQYLATLGGGSGIENEILKTNPILEAFGNGKTLRNDNSSRFGK LIEIHFSETGKISGANIQTFLLEKSRVVQCNEGERSYHIFYQLCAGAPSSLREKLNLTSAEDYKYLRQSNCYSITGVDDA EEFRIVKEALDVVHISKGDQENVFAMLAAVLWLGNISFTVVDNENHVQAVEDEGLFTVAKLIGCEIEDLKLTLSTRKMKV GNDIIVQKLTLSQAIDARDALAKSIYACLFDWLVEQINQSLAVGKRRTGRSISILDIYGFESFNRNSFEQFCINYANERL QQHFNRHLFKLEQEEYIQDGIDWAKVEFEDNQDCLNLFEKKPLGLLSLLDEESTFPNGTDLTFANKLKQHLNSNSCFKGE REKAFTVRHYAGEVTYDTSGFLEKNRDLLHLDSIQLLSSSKCHLPKLFASHMLTQSEKPVVGPLHKSGGADSQKLSVATK FKGQLFQLMQRLESTTPHFIRCIKPNNLQSPGSYEQSLVLQQLRCCGVLEVVRISRSGFPTRVSHQKFARRYGFLLLENV ASQDPLSVSVAILHQFNILPEMYQVGYTKLFFRTGQIGVLEDTRNRTLHGVLRVQSCFRGYRARCYRKELWRGITTLQSF IRGEKSRKEYAALLQRHRAAVIIQKRMKTVLARNRMKSINGAAVVIQSFIRGWLVRRCSGDIGLSKPRGIKTNESDEVLV KSSFLAELQRRVLKAEASLREKEEENDILHQRLQQYENRWSEYELKMKSMEEVWQKQMRSLQSSLSIAKKSLAMDDSERN SDASVNASDDRDFSWDVGTNHRRQESNGARSMSAGLSVISRLAEEFEQRSQVFGDDAKFLVEVKSGQVEASLNPDRELRR LKQMFEAWKKDYGARLRETKVILHKLGSEDGSIEKVKKSWWGRRNSTRIS* |
| CDS seq | >KRG90612 ATGTCTCAGACATCCACTGTCCTGCCTGCCTTCCACTCCATCAAATCATTGCCTCCTGAGTTCAACCCCGTTCTCGTGGA AAAACATGGAGATGTTAAATTTAGACACACCAATCCGATTGGATCAAATGGCCTTGAAAATGGTGCACTGGTAGCGGAGA TTTCTAAGGAAGTTAACTGCCGTGCTGGTGGCATGGATCTTTTTGACGAGGACTCGCCGTATGGTGGAAAAGGTAGATCA TTAAAAGACCGGCCGTCTAATGCAGATGAAGACTCAGTATCTGTTTCATTGCCCCTCCCATCGATTTTGACATCCTCTAG GGAAAGCAGGTGGAATGATGCAAATCCTTATGGTTCAAAAAAGAAGCTTCAGTCCTGGCTTCAGCTACCGAATGGGGATT GGGAGCTGGTAAAGATAATAACAACTTCTGGAGCTGAATCTGTCATTTCACTGCCTGATGGGAAAGTTTTAAAGGTGAAA GAGGAGAGTTTGGTGCCAGCTAATCCTGATATTCTTGATGGAGTGGATGACCTCATGCAACTAAGTTATTTAAATGAGCC ATCGGTTTTATTCAACCTGCAATATAGATACAATCATAATATGATCTATACAAAAGCTGGGCCTGTTTTGGTTGCTGTAA ATCCATTTAAGAAAGTTCCTCTGTATGGTAATGACTACATTGAAGCCTACAAGTGTAAATCAATTGAAAGCCCTCATGTA TATGCAATTACTGACACAGCCATCCAAGAAATGATACGGGATGAAGTGAATCAATCTATAATTATAAGTGGTGAGAGTGG AGCAGGGAAGACTGAGACGGCAAAAATAGCAATGCAGTACTTGGCTACCCTTGGTGGTGGAAGTGGAATAGAGAATGAGA TATTAAAGACTAATCCGATACTAGAAGCCTTTGGTAATGGAAAAACATTAAGAAATGACAACTCAAGTCGTTTTGGAAAG CTCATTGAGATTCACTTCAGTGAAACTGGAAAAATATCTGGTGCTAATATTCAAACATTTTTGCTGGAAAAGTCTAGAGT AGTCCAATGCAACGAAGGGGAAAGGTCATATCATATATTTTATCAGCTATGTGCTGGAGCACCATCATCACTTAGGGAAA AGCTAAATCTAACAAGTGCTGAGGACTATAAATATCTGAGGCAGAGCAATTGTTATTCAATTACGGGAGTTGATGACGCA GAAGAATTTCGCATAGTCAAGGAAGCTCTGGATGTTGTCCACATTAGCAAAGGAGACCAGGAGAATGTATTTGCAATGCT TGCTGCAGTATTATGGTTAGGAAACATATCATTTACTGTGGTAGATAATGAAAATCATGTTCAAGCTGTTGAGGATGAAG GACTGTTCACTGTTGCCAAGTTAATTGGCTGTGAAATTGAAGACCTGAAGTTGACTTTATCAACTCGCAAAATGAAAGTT GGTAATGATATTATTGTCCAGAAGTTGACTCTATCTCAGGCTATTGATGCAAGAGATGCTTTGGCGAAGTCAATATATGC TTGTCTGTTTGATTGGTTGGTTGAACAAATAAACCAATCCCTTGCGGTTGGCAAAAGACGAACTGGCAGATCAATCAGCA TCCTAGATATTTATGGCTTTGAGTCATTCAATAGGAACAGTTTTGAGCAGTTCTGCATAAATTATGCAAATGAGAGATTA CAACAACACTTCAATCGTCATTTATTCAAGTTAGAACAGGAGGAATATATCCAAGATGGAATTGATTGGGCTAAAGTTGA ATTTGAAGACAATCAAGATTGCCTTAATCTTTTTGAAAAGAAACCACTGGGGCTACTATCCCTGTTAGATGAAGAGTCAA CTTTCCCTAATGGCACAGATTTAACCTTTGCTAACAAGCTTAAGCAGCATTTGAATTCCAACTCATGCTTCAAAGGAGAA CGAGAAAAAGCCTTTACTGTGCGTCATTATGCAGGGGAGGTCACTTACGATACATCTGGATTCCTGGAAAAGAACAGGGA CCTATTGCACTTGGATTCCATCCAACTTCTATCCTCAAGCAAATGTCATCTTCCTAAGTTATTTGCATCCCATATGCTTA CTCAATCTGAGAAGCCTGTAGTAGGTCCCTTACACAAGTCAGGTGGGGCAGATTCCCAAAAGCTAAGCGTTGCCACAAAA TTCAAGGGACAATTGTTCCAATTGATGCAACGTTTAGAGAGTACTACACCACATTTTATCCGATGCATCAAGCCCAATAA TCTCCAATCACCTGGATCATATGAGCAAAGCCTTGTACTGCAGCAGTTGAGATGTTGTGGGGTCCTGGAAGTGGTTCGGA TATCAAGATCGGGCTTTCCTACTAGAGTATCTCACCAAAAGTTTGCCAGAAGATATGGTTTTCTTCTCCTTGAAAATGTT GCCTCTCAGGATCCACTTAGTGTTTCAGTTGCTATTCTTCATCAATTCAACATTTTGCCTGAGATGTATCAAGTTGGCTA CACGAAACTATTCTTTCGAACAGGGCAGATTGGAGTGCTTGAAGATACCAGAAATCGTACCCTGCATGGAGTTTTACGTG TGCAAAGTTGCTTCAGGGGTTACCGAGCTCGTTGTTATCGCAAGGAGCTTTGGAGAGGAATCACTACTCTCCAATCATTT ATTAGAGGAGAGAAAAGCAGAAAGGAATATGCAGCTTTGCTTCAGAGACATAGGGCTGCTGTTATTATACAAAAGCGGAT GAAAACAGTACTTGCAAGGAACAGAATGAAAAGTATTAATGGTGCTGCAGTTGTCATACAATCATTTATTCGTGGTTGGT TAGTCAGAAGATGCTCAGGAGATATAGGACTATCAAAACCTCGGGGCATTAAGACTAATGAGTCAGATGAGGTTCTGGTG AAGTCATCTTTCCTGGCTGAATTACAGCGCCGGGTACTTAAGGCAGAAGCTTCCCTGAGAGAGAAAGAAGAGGAAAATGA CATTCTTCACCAACGCCTTCAACAGTATGAGAACAGATGGTCTGAATATGAATTAAAGATGAAATCCATGGAAGAAGTAT GGCAGAAACAAATGAGGTCTCTACAGTCTAGCCTCTCTATTGCAAAGAAGAGCCTTGCTATGGATGATTCTGAAAGAAAT TCAGATGCTTCTGTTAATGCAAGTGATGACAGGGATTTCAGCTGGGATGTAGGAACCAATCACCGGCGCCAAGAAAGCAA TGGGGCAAGATCAATGAGTGCTGGTTTGAGTGTTATAAGTCGGTTGGCTGAAGAATTTGAGCAGAGGAGTCAAGTGTTTG GTGATGATGCAAAGTTCTTGGTAGAGGTAAAATCTGGTCAAGTTGAAGCAAGTTTGAACCCAGACAGAGAGCTTAGAAGG TTAAAACAAATGTTTGAGGCTTGGAAAAAGGATTATGGTGCAAGACTACGTGAAACAAAGGTCATTTTGCATAAACTTGG AAGTGAAGATGGATCAATTGAGAAAGTGAAGAAAAGTTGGTGGGGAAGAAGGAATAGTACAAGAATAAGTTGA |
| Microexon DNA seq | TTTTGCTGGAAAAG |
| Microexon Amino Acid seq | FLLEK |
| Microexon-tag DNA Seq | CACTTCAGTGAAACTGGAAAAATATCTGGTGCTAATATTCAAACATTTTTGCTGGAAAAGTCTAGAGTAGTCCAATGCAACGAAGGGGAAAGGTCATATCATATATTT |
| Microexon-tag Amino Acid seq | HFSETGKISGANIQTFLLEKSRVVQCNEGERSYHIF |
| Transcript ID | Gm.33335.1 |
| Gene ID | Gm.33335 |
| Gene Name | NA |
| Pfam domain motif | Myosin_head |
| Motif E-value | 1.9e-245 |
| Motif start | 175 |
| Motif end | 833 |
| Protein seq | >Gm.33335.1 MSQTSTVLPAFHSIKSLPPEFNPVLVEKHGDVKFRHTNPIGSNGLENGALVAEISKEVNCRAGGMDLFDEDSPYGGKGRS LKDRPSNADEDSVSVSLPLPSILTSSRESRWNDANPYGSKKKLQSWLQLPNGDWELVKIITTSGAESVISLPDGKVLKVK EESLVPANPDILDGVDDLMQLSYLNEPSVLFNLQYRYNHNMIYTKAGPVLVAVNPFKKVPLYGNDYIEAYKCKSIESPHV YAITDTAIQEMIRDEVNQSIIISGESGAGKTETAKIAMQYLATLGGGSGIENEILKTNPILEAFGNGKTLRNDNSSRFGK LIEIHFSETGKISGANIQTFLLEKSRVVQCNEGERSYHIFYQLCAGAPSSLREKLNLTSAEDYKYLRQSNCYSITGVDDA EEFRIVKEALDVVHISKGDQENVFAMLAAVLWLGNISFTVVDNENHVQAVEDEGLFTVAKLIGCEIEDLKLTLSTRKMKV GNDIIVQKLTLSQAIDARDALAKSIYACLFDWLVEQINQSLAVGKRRTGRSISILDIYGFESFNRNSFEQFCINYANERL QQHFNRHLFKLEQEEYIQDGIDWAKVEFEDNQDCLNLFEKKPLGLLSLLDEESTFPNGTDLTFANKLKQHLNSNSCFKGE REKAFTVRHYAGEVTYDTSGFLEKNRDLLHLDSIQLLSSSKCHLPKLFASHMLTQSEKPVVGPLHKSGGADSQKLSVATK FKGQLFQLMQRLESTTPHFIRCIKPNNLQSPGSYEQSLVLQQLRCCGVLEVVRISRSGFPTRVSHQKFARRYGFLLLENV ASQDPLSVSVAILHQFNILPEMYQVGYTKLFFRTGQIGVLEDTRNRTLHGVLRVQSCFRGYRARCYRKELWRGITTLQSF IRGEKSRKEYAALLQRHRAAVIIQKRMKTVLARNRMKSINGAAVVIQSFIRGWLVRRCSGDIGLSKPRGIKTNESDEVLV KSSFLAELQRRVLKAEASLREKEEENDILHQRLQQYENRWSEYELKMKSMEEVWQKQMRSLQSSLSIAKKSLAMDDSERN SDASVNASDDRDFSWDVGTNHRRQESNGARSMSAGLSVISRLAEEFEQRSQVFGDDAKFLVEVKSGQVEASLNPDRELRR LKQMFEAWKKDYGARLRETKVILHKLGSEDGSIEKVKKSWWGRRNSTRIS* |
| CDS seq | >Gm.33335.1 ATGTCTCAGACATCCACTGTCCTGCCTGCCTTCCACTCCATCAAATCATTGCCTCCTGAGTTCAACCCCGTTCTCGTGGA AAAACATGGAGATGTTAAATTTAGACACACCAATCCGATTGGATCAAATGGCCTTGAAAATGGTGCACTGGTAGCGGAGA TTTCTAAGGAAGTTAACTGCCGTGCTGGTGGCATGGATCTTTTTGACGAGGACTCGCCGTATGGTGGAAAAGGTAGATCA TTAAAAGACCGGCCGTCTAATGCAGATGAAGACTCAGTATCTGTTTCATTGCCCCTCCCATCGATTTTGACATCCTCTAG GGAAAGCAGGTGGAATGATGCAAATCCTTATGGTTCAAAAAAGAAGCTTCAGTCCTGGCTTCAGCTACCGAATGGGGATT GGGAGCTGGTAAAGATAATAACAACTTCTGGAGCTGAATCTGTCATTTCACTGCCTGATGGGAAAGTTTTAAAGGTGAAA GAGGAGAGTTTGGTGCCAGCTAATCCTGATATTCTTGATGGAGTGGATGACCTCATGCAACTAAGTTATTTAAATGAGCC ATCGGTTTTATTCAACCTGCAATATAGATACAATCATAATATGATCTATACAAAAGCTGGGCCTGTTTTGGTTGCTGTAA ATCCATTTAAGAAAGTTCCTCTGTATGGTAATGACTACATTGAAGCCTACAAGTGTAAATCAATTGAAAGCCCTCATGTA TATGCAATTACTGACACAGCCATCCAAGAAATGATACGGGATGAAGTGAATCAATCTATAATTATAAGTGGTGAGAGTGG AGCAGGGAAGACTGAGACGGCAAAAATAGCAATGCAGTACTTGGCTACCCTTGGTGGTGGAAGTGGAATAGAGAATGAGA TATTAAAGACTAATCCGATACTAGAAGCCTTTGGTAATGGAAAAACATTAAGAAATGACAACTCAAGTCGTTTTGGAAAG CTCATTGAGATTCACTTCAGTGAAACTGGAAAAATATCTGGTGCTAATATTCAAACATTTTTGCTGGAAAAGTCTAGAGT AGTCCAATGCAACGAAGGGGAAAGGTCATATCATATATTTTATCAGCTATGTGCTGGAGCACCATCATCACTTAGGGAAA AGCTAAATCTAACAAGTGCTGAGGACTATAAATATCTGAGGCAGAGCAATTGTTATTCAATTACGGGAGTTGATGACGCA GAAGAATTTCGCATAGTCAAGGAAGCTCTGGATGTTGTCCACATTAGCAAAGGAGACCAGGAGAATGTATTTGCAATGCT TGCTGCAGTATTATGGTTAGGAAACATATCATTTACTGTGGTAGATAATGAAAATCATGTTCAAGCTGTTGAGGATGAAG GACTGTTCACTGTTGCCAAGTTAATTGGCTGTGAAATTGAAGACCTGAAGTTGACTTTATCAACTCGCAAAATGAAAGTT GGTAATGATATTATTGTCCAGAAGTTGACTCTATCTCAGGCTATTGATGCAAGAGATGCTTTGGCGAAGTCAATATATGC TTGTCTGTTTGATTGGTTGGTTGAACAAATAAACCAATCCCTTGCGGTTGGCAAAAGACGAACTGGCAGATCAATCAGCA TCCTAGATATTTATGGCTTTGAGTCATTCAATAGGAACAGTTTTGAGCAGTTCTGCATAAATTATGCAAATGAGAGATTA CAACAACACTTCAATCGTCATTTATTCAAGTTAGAACAGGAGGAATATATCCAAGATGGAATTGATTGGGCTAAAGTTGA ATTTGAAGACAATCAAGATTGCCTTAATCTTTTTGAAAAGAAACCACTGGGGCTACTATCCCTGTTAGATGAAGAGTCAA CTTTCCCTAATGGCACAGATTTAACCTTTGCTAACAAGCTTAAGCAGCATTTGAATTCCAACTCATGCTTCAAAGGAGAA CGAGAAAAAGCCTTTACTGTGCGTCATTATGCAGGGGAGGTCACTTACGATACATCTGGATTCCTGGAAAAGAACAGGGA CCTATTGCACTTGGATTCCATCCAACTTCTATCCTCAAGCAAATGTCATCTTCCTAAGTTATTTGCATCCCATATGCTTA CTCAATCTGAGAAGCCTGTAGTAGGTCCCTTACACAAGTCAGGTGGGGCAGATTCCCAAAAGCTAAGCGTTGCCACAAAA TTCAAGGGACAATTGTTCCAATTGATGCAACGTTTAGAGAGTACTACACCACATTTTATCCGATGCATCAAGCCCAATAA TCTCCAATCACCTGGATCATATGAGCAAAGCCTTGTACTGCAGCAGTTGAGATGTTGTGGGGTCCTGGAAGTGGTTCGGA TATCAAGATCGGGCTTTCCTACTAGAGTATCTCACCAAAAGTTTGCCAGAAGATATGGTTTTCTTCTCCTTGAAAATGTT GCCTCTCAGGATCCACTTAGTGTTTCAGTTGCTATTCTTCATCAATTCAACATTTTGCCTGAGATGTATCAAGTTGGCTA CACGAAACTATTCTTTCGAACAGGGCAGATTGGAGTGCTTGAAGATACCAGAAATCGTACCCTGCATGGAGTTTTACGTG TGCAAAGTTGCTTCAGGGGTTACCGAGCTCGTTGTTATCGCAAGGAGCTTTGGAGAGGAATCACTACTCTCCAATCATTT ATTAGAGGAGAGAAAAGCAGAAAGGAATATGCAGCTTTGCTTCAGAGACATAGGGCTGCTGTTATTATACAAAAGCGGAT GAAAACAGTACTTGCAAGGAACAGAATGAAAAGTATTAATGGTGCTGCAGTTGTCATACAATCATTTATTCGTGGTTGGT TAGTCAGAAGATGCTCAGGAGATATAGGACTATCAAAACCTCGGGGCATTAAGACTAATGAGTCAGATGAGGTTCTGGTG AAGTCATCTTTCCTGGCTGAATTACAGCGCCGGGTACTTAAGGCAGAAGCTTCCCTGAGAGAGAAAGAAGAGGAAAATGA CATTCTTCACCAACGCCTTCAACAGTATGAGAACAGATGGTCTGAATATGAATTAAAGATGAAATCCATGGAAGAAGTAT GGCAGAAACAAATGAGGTCTCTACAGTCTAGCCTCTCTATTGCAAAGAAGAGCCTTGCTATGGATGATTCTGAAAGAAAT TCAGATGCTTCTGTTAATGCAAGTGATGACAGGGATTTCAGCTGGGATGTAGGAACCAATCACCGGCGCCAAGAAAGCAA TGGGGCAAGATCAATGAGTGCTGGTTTGAGTGTTATAAGTCGGTTGGCTGAAGAATTTGAGCAGAGGAGTCAAGTGTTTG GTGATGATGCAAAGTTCTTGGTAGAGGTAAAATCTGGTCAAGTTGAAGCAAGTTTGAACCCAGACAGAGAGCTTAGAAGG TTAAAACAAATGTTTGAGGCTTGGAAAAAGGATTATGGTGCAAGACTACGTGAAACAAAGGTCATTTTGCATAAACTTGG AAGTGAAGATGGATCAATTGAGAAAGTGAAGAAAAGTTGGTGGGGAAGAAGGAATAGTACAAGAATAAGTTGA |