| Microexon ID | Gm_20:135910-135923:- |
| Species | Glycine max | Coordinates | 20:135910..135923 |
| Microexon Cluster ID | MEP38 |
| Size | 14 |
| Phase | 1 |
| Pfam Domain Motif | Myosin_head |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 46,14,48 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | CAYTTYARTRMAACTGGRAARATATSTGGTGCYAADATTCAAACWTTTYTRCTTGARAAGTCWAGAGTWGTYCARYKTGCWGAWGGWGARAGRTCATAYCATATWTTT |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 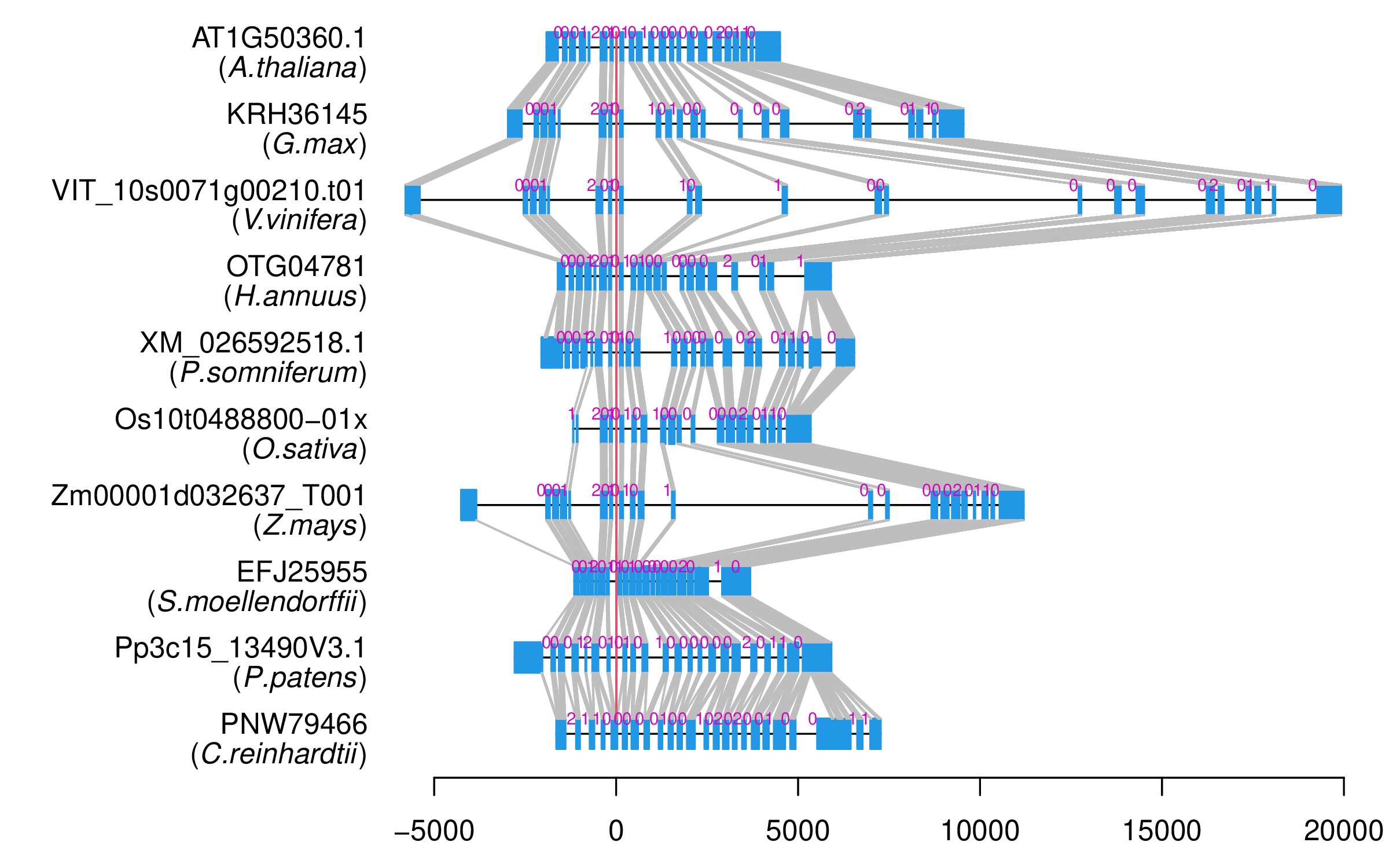 |
| Microexon DNA seq | TTTTGCTTGAAAAG |
| Microexon Amino Acid seq | FLLEK |
| Microexon-tag DNA Seq | CACTTCAGTGAAACTGGAAAAATCTCCGGTGCTAATATTCAAACTTTTTTGCTTGAAAAGTCTAGAGTAGTCCAATGCAATGAAGGGGAAAGATCATATCATATATTT |
| Microexon-tag Amino Acid Seq | HFSETGKISGANIQTFLLEKSRVVQCNEGERSYHIF |
| Microexon-tag spanning region | 135692-136101 |
| Microexon-tag prediction score | 0.9745 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | KRG89103x |
| Reference Transcript ID | KRG89103 |
| Gene ID | GLYMA_20G001300 |
| Gene Name | NA |
| Transcript ID | KRG89103 |
| Protein ID | KRG89103 |
| Gene ID | GLYMA_20G001300 |
| Gene Name | NA |
| Pfam domain motif | Myosin_head |
| Motif E-value | 2.6e-244 |
| Motif start | 182 |
| Motif end | 839 |
| Protein seq | >KRG89103 MSATSKVLPALHPIKSLPPKFKITSGNPTAGLMENHGDAKFRSNDVIRSGSPENDALIGEVAEEAQNCAGDMGVYGEDLA YSRKGVSLEDRPSIADEDLESVPLPFPSISMSSRERRWSDTTPYASKKKLQSWFQLPNGNWELGKIITTSGNESIISLFD GKVLKVKEESLVPANPDILDGVDDLMQLSYLNEPSVLFNLQYRYNQNMIYTKAGPVLVAINPFKKVPLYGNDYIEAYKRK AIESPHVYAITDTAIREMIRDEVNQSIIISGESGAGKTETAKIAMQYLAALGGGSGIEYEILKTNPILEAFGNAKTLRND NSSRFGKLIEIHFSETGKISGANIQTFLLEKSRVVQCNEGERSYHIFYQLCAGAPPSLRGKLNLQNAEDYNYLRQSNCYS ITGVNDAEEFRTVMEALDVVHISKEDQENVFAMLAAVLWLGNISFTVIDNENHVQAVEDEGLFHVAKLIGCSIEDLKLTL STRKMKVGNDNIVQKLTLSQAIDARDALAKSIYACLFDWLVEQINKSLAVGKRRTGRSISILDIYGFESFNRNSFEQFCI NYANERLQQHFNRHLFKLEQEEYIQDGIDWAKVEFEDNQDCLNLFEKRPLGLLSLLDEESTFPNGTDLTLANKLKQHLNS NSCFKGERDQAFTVHHYAGQVTYDTTGFLEKNRDLLHVDSIQLLSSCTCPLPQIFASHMLTQSDKPVVGPLHKSGGADSQ KLSVATKFKGQLFQLMQRLESTTPHFIRCIKPNNLQSPESYEQGLVLQQLRCCGVLEVVRISRSGFPTRMSHQKFARRYG FLLDNVASQDPLSVSVAILHQFNILSEMYQVGYTKLFFRTGQIGVLEDTRNRTLHGILRVQSCFRGFQARRSLKDLRGGI TTLQSFIRGDKTRKAYSALLKRHRAAVIIQKQIKAVFARNRMRTISDAAIVIQAVIRGWLVRRCSGNIGFLKSGDMKMKE SDEVLVKSSFLAELQCRVLKAEAALREKEEENDILHQRLQQYESRWSEYELKMKSMEEVWQKQMRSLQSSLSIAKKSLAI DDSERNSDTSVNASDERDYSWDVGGNHRRQESNGARSTSAGLSVISRLAEEFEHRSQVFGDDAKFLVEVKSGQVEASLNP DQELRRLKQMFEAWKKDYGARLRETKVIINKLGSEDGALEKMKKKWWGRRNSTRIN* |
| CDS seq | >KRG89103 ATGTCTGCAACATCCAAGGTCCTGCCTGCTCTCCACCCTATCAAATCATTGCCTCCCAAGTTCAAGATTACTTCTGGTAA TCCGACTGCTGGTCTAATGGAAAACCATGGAGATGCTAAGTTCAGAAGCAATGATGTGATCAGATCAGGTAGTCCAGAAA ATGATGCTTTGATAGGGGAGGTTGCTGAGGAAGCTCAGAACTGTGCTGGTGACATGGGTGTTTACGGTGAGGACTTGGCG TACAGCAGAAAAGGTGTGTCGTTAGAAGACAGGCCATCAATTGCTGATGAAGACTTAGAATCTGTTCCTCTGCCCTTCCC ATCAATTTCAATGTCCTCTAGGGAACGCAGGTGGAGTGATACAACACCTTATGCTTCAAAGAAGAAACTTCAGTCTTGGT TTCAACTTCCGAATGGGAATTGGGAGCTGGGGAAGATAATAACAACTTCTGGAAATGAATCTATCATTTCACTGTTTGAC GGGAAGGTTTTGAAAGTGAAAGAAGAAAGTTTAGTACCAGCAAATCCTGATATCCTTGATGGAGTGGATGACCTCATGCA ACTTAGTTATTTAAATGAGCCGTCAGTTTTATTCAACCTGCAATATAGATACAATCAAAACATGATTTATACAAAAGCAG GGCCTGTTTTGGTTGCTATAAATCCCTTTAAGAAAGTTCCTCTATATGGTAATGATTATATTGAAGCCTACAAGCGTAAA GCAATTGAAAGCCCTCATGTATATGCAATAACAGACACGGCCATCCGAGAAATGATACGAGATGAAGTCAATCAATCTAT AATTATAAGTGGGGAGAGTGGAGCAGGGAAGACTGAGACAGCAAAAATAGCAATGCAGTACTTGGCTGCCCTTGGCGGTG GAAGTGGAATAGAGTATGAGATTTTAAAGACTAATCCAATACTAGAAGCCTTTGGCAATGCAAAAACATTGAGAAATGAC AACTCAAGTCGTTTTGGAAAGCTCATTGAGATTCACTTCAGTGAAACTGGAAAAATCTCCGGTGCTAATATTCAAACTTT TTTGCTTGAAAAGTCTAGAGTAGTCCAATGCAATGAAGGGGAAAGATCATATCATATATTTTATCAGCTATGTGCTGGTG CACCTCCATCTCTCAGGGGGAAGCTAAACCTACAAAATGCAGAAGACTATAATTATCTGAGGCAGAGCAATTGTTATTCA ATTACTGGTGTTAATGATGCAGAAGAATTTCGTACAGTCATGGAAGCCCTTGATGTTGTCCACATTAGTAAAGAAGACCA GGAGAATGTATTTGCAATGCTTGCTGCAGTATTATGGTTAGGAAACATATCATTTACTGTGATTGATAATGAAAATCATG TTCAAGCTGTAGAAGATGAGGGTCTGTTCCATGTAGCTAAATTAATTGGCTGTAGCATTGAAGATCTCAAGTTGACACTA TCAACTCGCAAAATGAAAGTTGGTAATGATAATATTGTCCAAAAGTTGACGCTATCACAGGCCATTGATGCAAGAGATGC TTTGGCAAAGTCAATATATGCATGCCTGTTTGATTGGTTGGTTGAACAGATAAATAAATCACTTGCTGTTGGCAAAAGAC GTACCGGCAGATCAATCAGTATTCTAGATATCTACGGCTTTGAATCTTTCAATAGGAACAGTTTTGAACAGTTCTGCATA AATTATGCAAATGAGAGATTACAGCAACACTTCAATCGTCATTTATTCAAGTTAGAACAGGAGGAATATATTCAAGATGG CATTGACTGGGCTAAAGTTGAATTTGAAGACAACCAAGACTGCCTTAATCTTTTTGAGAAGAGGCCACTGGGTTTATTAT CCTTGTTAGATGAAGAGTCCACTTTCCCAAATGGCACAGATCTAACACTTGCTAACAAGCTTAAACAGCATTTGAATTCT AATTCGTGCTTCAAAGGAGAAAGAGACCAAGCCTTTACTGTACACCATTATGCTGGGCAGGTAACCTATGATACAACTGG ATTTCTGGAGAAAAACAGAGACCTATTGCACGTGGATTCCATCCAACTTCTATCCTCATGCACGTGTCCTCTTCCTCAAA TATTTGCATCTCATATGCTCACTCAGTCTGATAAGCCGGTAGTTGGTCCCTTACACAAGTCAGGTGGGGCAGATTCCCAA AAGCTAAGTGTTGCAACAAAATTCAAGGGTCAATTGTTTCAACTGATGCAACGACTGGAGAGTACTACTCCACATTTTAT TCGCTGCATTAAACCCAATAATCTCCAATCACCTGAATCATATGAGCAAGGGCTTGTATTGCAACAGCTGAGATGCTGTG GGGTCCTGGAAGTAGTTCGAATATCGAGATCAGGCTTTCCAACAAGAATGTCTCACCAAAAATTTGCCAGAAGATATGGT TTTCTCCTTGATAATGTTGCATCTCAGGATCCACTTAGTGTTTCGGTTGCAATTCTTCATCAGTTTAATATTTTGTCGGA GATGTATCAAGTTGGCTACACAAAATTATTTTTCCGGACAGGGCAGATTGGTGTGCTTGAAGATACTAGAAATCGTACCC TCCATGGCATTTTACGTGTCCAAAGTTGTTTCAGGGGTTTCCAAGCACGTCGTTCTCTCAAGGATCTTCGGGGAGGAATC ACTACTTTGCAGTCATTTATTAGGGGAGACAAAACCAGAAAGGCATATTCAGCTTTACTTAAGAGGCATAGAGCTGCTGT TATTATACAGAAGCAAATCAAAGCAGTATTTGCAAGAAACAGAATGAGGACTATTAGTGATGCTGCAATAGTCATACAAG CAGTTATTCGTGGTTGGTTGGTCAGAAGATGCTCAGGAAATATTGGATTTTTGAAATCTGGAGACATGAAGATGAAAGAG TCTGATGAGGTTCTGGTTAAGTCATCTTTCCTGGCCGAATTACAGTGCCGAGTACTTAAGGCTGAAGCTGCCCTTAGAGA GAAAGAAGAGGAAAATGACATCCTTCATCAACGTCTCCAACAATATGAGAGCAGATGGTCTGAGTATGAACTAAAGATGA AATCCATGGAAGAAGTGTGGCAGAAACAAATGAGATCCCTACAATCTAGCCTCTCCATTGCAAAGAAGAGCCTTGCTATC GATGACTCTGAAAGAAATTCAGACACATCTGTTAATGCAAGTGATGAGCGGGATTACAGCTGGGATGTGGGAGGCAATCA TCGGCGCCAAGAAAGCAATGGGGCAAGATCAACGAGTGCTGGTCTAAGTGTTATAAGTCGGCTGGCTGAAGAATTCGAGC ACAGGAGTCAAGTATTTGGTGATGATGCCAAGTTCTTGGTTGAGGTAAAATCTGGTCAGGTAGAAGCAAGTTTGAACCCA GATCAAGAGCTTAGAAGGTTAAAACAGATGTTTGAAGCTTGGAAAAAGGATTATGGGGCAAGACTGCGTGAAACAAAAGT TATTATAAATAAACTTGGAAGCGAAGATGGCGCACTTGAGAAAATGAAGAAAAAGTGGTGGGGAAGAAGGAACAGTACAA GGATAAATTGA |
| Microexon DNA seq | TTTTGCTTGAAAAG |
| Microexon Amino Acid seq | FLLEK |
| Microexon-tag DNA Seq | CACTTCAGTGAAACTGGAAAAATCTCCGGTGCTAATATTCAAACTTTTTTGCTTGAAAAGTCTAGAGTAGTCCAATGCAATGAAGGGGAAAGATCATATCATATATTT |
| Microexon-tag Amino Acid seq | HFSETGKISGANIQTFLLEKSRVVQCNEGERSYHIF |
| Transcript ID | Gm.32452.2 |
| Gene ID | Gm.32452 |
| Gene Name | NA |
| Pfam domain motif | Myosin_head |
| Motif E-value | 1.1e-190 |
| Motif start | 182 |
| Motif end | 660 |
| Protein seq | >Gm.32452.2 MSATSKVLPALHPIKSLPPKFKITSGNPTAGLMENHGDAKFRSNDVIRSGSPENDALIGEVAEEAQNCAGDMGVYGEDLA YSRKGVSLEDRPSIADEDLESVPLPFPSISMSSRERRWSDTTPYASKKKLQSWFQLPNGNWELGKIITTSGNESIISLFD GKVLKVKEESLVPANPDILDGVDDLMQLSYLNEPSVLFNLQYRYNQNMIYTKAGPVLVAINPFKKVPLYGNDYIEAYKRK AIESPHVYAITDTAIREMIRDEVNQSIIISGESGAGKTETAKIAMQYLAALGGGSGIEYEILKTNPILEAFGNAKTLRND NSSRFGKLIEIHFSETGKISGANIQTFLLEKSRVVQCNEGERSYHIFYQLCAGAPPSLRGKLNLQNAEDYNYLRQSNCYS ITGVNDAEEFRTVMEALDVVHISKEDQENVFAMLAAVLWLGNISFTVIDNENHVQAVEDEGLFHVAKLIGCSIEDLKLTL STRKMKVGNDNIVQKLTLSQAIDARDALAKSIYACLFDWLVEQINKSLAVGKRRTGRSISILDIYGFESFNRNSFEQFCI NYANERLQQHFNRHLFKLEQEEYIQDGIDWAKVEFEDNQDCLNLFEKRPLGLLSLLDEESTFPNGTDLTLANKLKQHLNS NSCFKGERDQAFTVHHYAGQFYLFLHSGNL* |
| CDS seq | >Gm.32452.2 ATGTCTGCAACATCCAAGGTCCTGCCTGCTCTCCACCCTATCAAATCATTGCCTCCCAAGTTCAAGATTACTTCTGGTAA TCCGACTGCTGGTCTAATGGAAAACCATGGAGATGCTAAGTTCAGAAGCAATGATGTGATCAGATCAGGTAGTCCAGAAA ATGATGCTTTGATAGGGGAGGTTGCTGAGGAAGCTCAGAACTGTGCTGGTGACATGGGTGTTTACGGTGAGGACTTGGCG TACAGCAGAAAAGGTGTGTCGTTAGAAGACAGGCCATCAATTGCTGATGAAGACTTAGAATCTGTTCCTCTGCCCTTCCC ATCAATTTCAATGTCCTCTAGGGAACGCAGGTGGAGTGATACAACACCTTATGCTTCAAAGAAGAAACTTCAGTCTTGGT TTCAACTTCCGAATGGGAATTGGGAGCTGGGGAAGATAATAACAACTTCTGGAAATGAATCTATCATTTCACTGTTTGAC GGGAAGGTTTTGAAAGTGAAAGAAGAAAGTTTAGTACCAGCAAATCCTGATATCCTTGATGGAGTGGATGACCTCATGCA ACTTAGTTATTTAAATGAGCCGTCAGTTTTATTCAACCTGCAATATAGATACAATCAAAACATGATTTATACAAAAGCAG GGCCTGTTTTGGTTGCTATAAATCCCTTTAAGAAAGTTCCTCTATATGGTAATGATTATATTGAAGCCTACAAGCGTAAA GCAATTGAAAGCCCTCATGTATATGCAATAACAGACACGGCCATCCGAGAAATGATACGAGATGAAGTCAATCAATCTAT AATTATAAGTGGGGAGAGTGGAGCAGGGAAGACTGAGACAGCAAAAATAGCAATGCAGTACTTGGCTGCCCTTGGCGGTG GAAGTGGAATAGAGTATGAGATTTTAAAGACTAATCCAATACTAGAAGCCTTTGGCAATGCAAAAACATTGAGAAATGAC AACTCAAGTCGTTTTGGAAAGCTCATTGAGATTCACTTCAGTGAAACTGGAAAAATCTCCGGTGCTAATATTCAAACTTT TTTGCTTGAAAAGTCTAGAGTAGTCCAATGCAATGAAGGGGAAAGATCATATCATATATTTTATCAGCTATGTGCTGGTG CACCTCCATCTCTCAGGGGGAAGCTAAACCTACAAAATGCAGAAGACTATAATTATCTGAGGCAGAGCAATTGTTATTCA ATTACTGGTGTTAATGATGCAGAAGAATTTCGTACAGTCATGGAAGCCCTTGATGTTGTCCACATTAGTAAAGAAGACCA GGAGAATGTATTTGCAATGCTTGCTGCAGTATTATGGTTAGGAAACATATCATTTACTGTGATTGATAATGAAAATCATG TTCAAGCTGTAGAAGATGAGGGTCTGTTCCATGTAGCTAAATTAATTGGCTGTAGCATTGAAGATCTCAAGTTGACACTA TCAACTCGCAAAATGAAAGTTGGTAATGATAATATTGTCCAAAAGTTGACGCTATCACAGGCCATTGATGCAAGAGATGC TTTGGCAAAGTCAATATATGCATGCCTGTTTGATTGGTTGGTTGAACAGATAAATAAATCACTTGCTGTTGGCAAAAGAC GTACCGGCAGATCAATCAGTATTCTAGATATCTACGGCTTTGAATCTTTCAATAGGAACAGTTTTGAACAGTTCTGCATA AATTATGCAAATGAGAGATTACAGCAACACTTCAATCGTCATTTATTCAAGTTAGAACAGGAGGAATATATTCAAGATGG CATTGACTGGGCTAAAGTTGAATTTGAAGACAACCAAGACTGCCTTAATCTTTTTGAGAAGAGGCCACTGGGTTTATTAT CCTTGTTAGATGAAGAGTCCACTTTCCCAAATGGCACAGATCTAACACTTGCTAACAAGCTTAAACAGCATTTGAATTCT AATTCGTGCTTCAAAGGAGAAAGAGACCAAGCCTTTACTGTACACCATTATGCTGGGCAGTTCTACTTGTTCCTCCACTC AGGTAACCTATGA |