| Microexon ID | At_1:18652603-18652616:+ |
| Species | Arabidopsis thaliana | Coordinates | 1:18652603..18652616 |
| Microexon Cluster ID | MEP38 |
| Size | 14 |
| Phase | 1 |
| Pfam Domain Motif | Myosin_head |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 46,14,48 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | CAYTTYARTRMAACTGGRAARATATSTGGTGCYAADATTCAAACWTTTYTRCTTGARAAGTCWAGAGTWGTYCARYKTGCWGAWGGWGARAGRTCATAYCATATWTTT |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 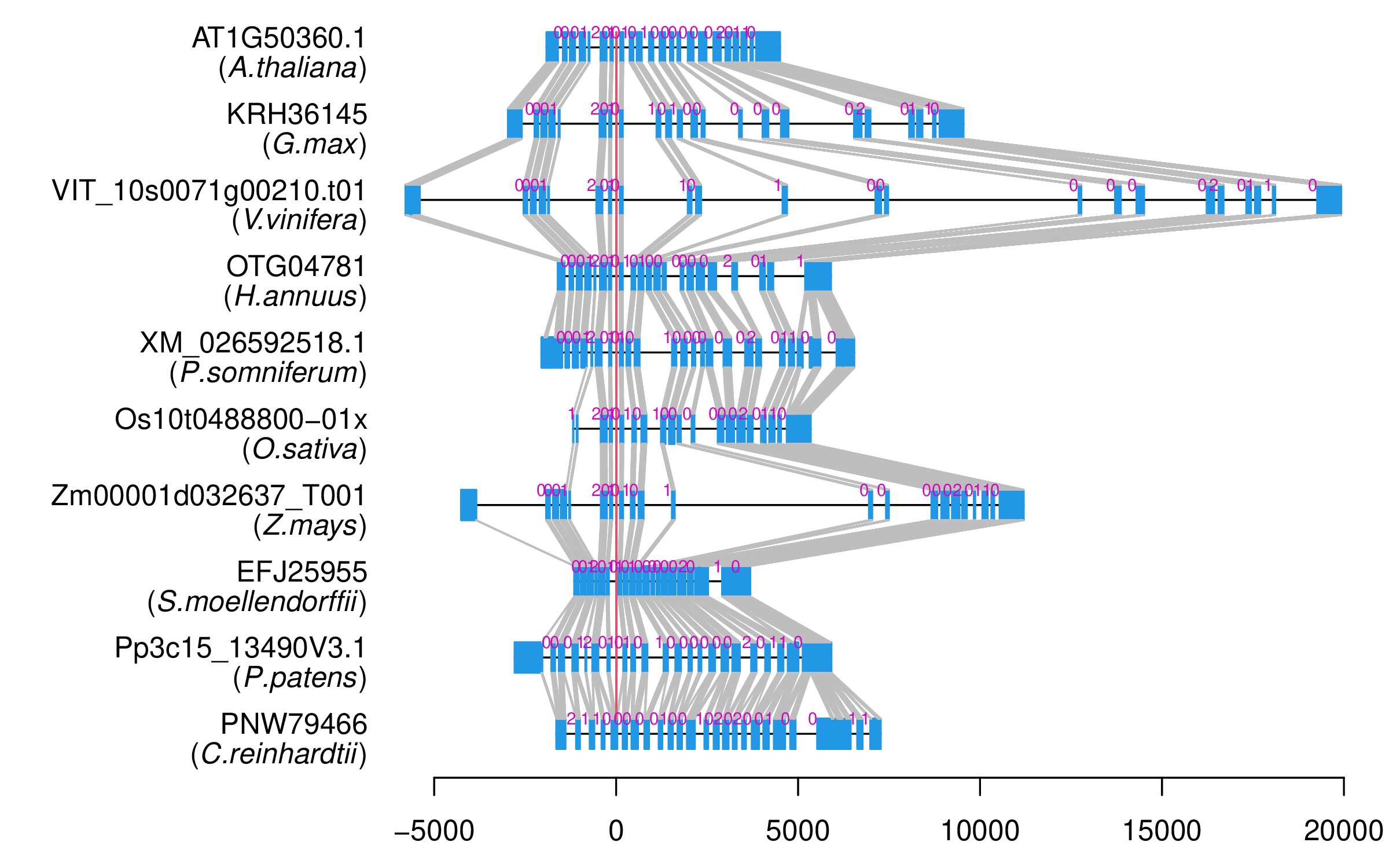 |
| Microexon DNA seq | TTTTACTAGAAAAG |
| Microexon Amino Acid seq | FLLEK |
| Microexon-tag DNA Seq | CATTTTAGTGAAACAGGGAAGATTTCGGGTGCTCAAATTCAAACATTTTTACTAGAAAAGTCAAGAGTGGTTCAATGTACGGAAGGAGAAAGGTCATATCATATATTC |
| Microexon-tag Amino Acid Seq | HFSETGKISGAQIQTFLLEKSRVVQCTEGERSYHIF |
| Microexon-tag spanning region | 18652464-18652763 |
| Microexon-tag prediction score | 0.9661 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | AT1G50360.1x |
| Reference Transcript ID | AT1G50360.1 |
| Gene ID | AT1G50360 |
| Gene Name | VIII-A |
| Transcript ID | AT1G50360.1 |
| Protein ID | AT1G50360.1 |
| Gene ID | AT1G50360 |
| Gene Name | VIII-A |
| Pfam domain motif | Myosin_head |
| Motif E-value | 8e-245 |
| Motif start | 159 |
| Motif end | 817 |
| Protein seq | >AT1G50360.1 MAHKVKASFQSLKTMPADYRFLGSPISDHLETNLITPPNGHLKNGVNGTASSVGGMDSVNEDSPYSVRSILNGERSSIGD GDSILPLPESNDRKWSDTNVYARKKVLQFWVQLPNGNWELGKIMSTSGEESVIVVTEGKVLKVKSETLVPANPDILDGVD DLMQLSYLNEPAVLYNLEYRYNQDMIYTKAGPVLVAVNPFKEVPLYGNRNIEAYRKRSNESPHVYAIADTAIREMIRDEV NQSIIISGESGAGKTETAKIAMQYLAALGGGSGIEYEILKTNPILEAFGNAKTLRNDNSSRFGKLIEIHFSETGKISGAQ IQTFLLEKSRVVQCTEGERSYHIFYQLCAGASPTLREKLNLTSAKQYNYLKQSNCYSINGVDDAERFHAVKEALDIVHVS KEDQENVFAMLAAVLWLGNVSFTIIDNENHVEPEPDESLSTVAKLIGCNINELKLALSKRNMRVNNDTIVQKLTLSQAID ARDALAKSIYACLFDWLVEQINKSLAVGKRRTGRSISILDIYGFESFNKNSFEQFCINYANERLQQHFNRHLFKLEQEEY IQDGIDWTRVDFEDNQECLSLFEKKPLGLLSLLDEESTFPNGTDLTLANKLKQHLNDNSCFRGDRGKAFTVAHYAGEVTY ETTGFLEKNRDLLHSDSIQLLSSCSCHLPQAFASSMLIYSEKPLVGPLHKAGGADSQRLSVATKFKGQLFQLMQRLGNTT PHFIRCIKPNNVQSAGLYEQGLVLQQLRCCGVLEVVRISRSGFPTRMFHHKFARRYGFLLLENIAAKDPLSVSVAILHQF NILPEMYQVGYTKLFFRTGQIGVLEDTRNRTLHGILRLQSYFRGHQARCRLKELKTGITILQSFVRGEKMRKEYTELLQR HRASAAIQSHVKRRIASQQYKATVDASAVIQSAIRGELVRRCAGDIGWLSSGGTKRNESDEVLVKASYLSDLQRRVLRTE AALREKEEENDILRQRVQQYDNRWSEYETKMKSMEEIWQKQMKSLQSSLSIAKKSLEVEDSARNSDASVNASDATDLDSG GSHYQMGHGRSRSVGVGLSVISRLAEEFGQRAQVFGDDRKFLMEVKSGQVEANLNPDRELRRLKQMFETWKKDYGGRLRE TKLILSKLGSEETGGSAEKVKMNWWGRLRSTRY* |
| CDS seq | >AT1G50360.1 ATGGCACACAAGGTTAAGGCATCTTTTCAGTCACTTAAAACGATGCCGGCTGACTATAGATTTCTTGGTTCACCAATCTC TGATCACCTTGAGACCAATTTGATTACTCCACCAAATGGTCACTTAAAGAATGGGGTTAATGGCACTGCAAGTTCTGTTG GTGGAATGGATAGTGTTAATGAGGATTCACCTTATAGTGTCCGCAGCATTTTAAATGGAGAGCGGTCTTCAATTGGTGAT GGAGATTCTATTTTGCCCTTGCCTGAGAGTAATGATCGCAAGTGGAGCGACACAAATGTATATGCTCGGAAAAAGGTACT GCAATTTTGGGTCCAACTTCCAAACGGTAACTGGGAGCTGGGAAAGATAATGTCAACTTCAGGAGAAGAGTCTGTTATCG TGGTAACTGAGGGAAAAGTTTTAAAAGTCAAATCAGAGACTTTAGTACCTGCAAATCCTGATATTCTTGATGGAGTAGAC GATCTCATGCAACTAAGTTATTTAAATGAGCCAGCAGTGTTGTACAACCTTGAGTATAGGTACAACCAGGACATGATATA TACAAAAGCAGGGCCGGTTCTGGTGGCTGTGAATCCCTTCAAGGAGGTTCCTTTGTACGGTAATCGCAACATTGAAGCAT ACAGGAAGAGATCAAATGAGAGCCCTCATGTCTATGCTATTGCAGATACAGCAATACGTGAAATGATACGAGATGAAGTT AACCAATCAATCATTATCAGTGGAGAGAGTGGAGCAGGAAAGACTGAGACAGCAAAGATAGCGATGCAATACTTGGCTGC TCTTGGAGGTGGAAGTGGGATCGAGTATGAGATACTAAAGACTAATCCCATCTTGGAAGCATTTGGAAATGCAAAAACAT TGAGAAACGATAATTCTAGTCGTTTTGGTAAGTTGATAGAAATTCATTTTAGTGAAACAGGGAAGATTTCGGGTGCTCAA ATTCAAACATTTTTACTAGAAAAGTCAAGAGTGGTTCAATGTACGGAAGGAGAAAGGTCATATCATATATTCTATCAACT TTGTGCTGGGGCTTCACCTACACTTAGAGAGAAGTTAAATTTGACAAGTGCAAAACAGTATAACTATTTGAAACAAAGCA ATTGCTATTCAATTAACGGAGTTGATGACGCTGAACGTTTTCACGCCGTTAAGGAAGCTTTAGATATTGTGCATGTTAGT AAAGAAGATCAAGAAAATGTATTTGCAATGCTTGCTGCAGTATTATGGCTAGGGAATGTTTCTTTTACCATTATTGACAA CGAAAATCACGTTGAACCTGAACCAGATGAAAGTTTGTCAACTGTTGCTAAATTGATTGGGTGCAACATCAATGAGCTTA AGCTAGCTCTATCAAAGCGTAATATGAGAGTTAATAATGATACTATTGTACAGAAGCTAACACTATCGCAGGCCATTGAC GCAAGAGATGCTTTAGCAAAGTCAATCTATGCCTGCCTATTTGACTGGCTAGTTGAACAGATTAACAAATCTCTTGCGGT GGGAAAGAGGAGAACTGGCAGATCCATCAGCATTCTTGATATCTATGGCTTTGAATCATTCAATAAAAATAGTTTTGAGC AGTTCTGTATAAATTATGCAAATGAGAGATTGCAGCAACACTTCAACCGTCATCTCTTCAAGCTTGAGCAGGAGGAATAT ATTCAGGATGGCATTGACTGGACAAGGGTTGATTTTGAGGACAACCAAGAATGTCTTAGTCTCTTTGAAAAGAAACCATT AGGGCTGCTTTCTCTTCTGGATGAGGAATCCACATTTCCAAATGGCACAGATTTGACACTTGCCAACAAGCTTAAACAAC ATCTAAATGATAATTCCTGTTTTAGAGGAGATCGGGGGAAGGCTTTCACAGTTGCGCATTATGCTGGAGAGGTTACATAT GAGACGACTGGATTTCTAGAGAAGAACCGAGATTTGTTGCATTCAGATTCTATTCAACTTTTGTCGTCTTGCTCTTGCCA CCTCCCTCAGGCGTTTGCTTCTAGTATGCTCATTTATTCTGAAAAACCTCTTGTCGGTCCTTTACACAAAGCAGGTGGAG CTGATTCCCAGCGACTGAGTGTAGCAACTAAATTTAAGGGTCAACTTTTCCAATTGATGCAACGTCTAGGGAACACTACC CCACATTTTATTCGCTGCATAAAGCCAAACAATGTTCAGTCTGCCGGGTTGTATGAGCAAGGACTTGTCTTACAGCAGCT AAGATGTTGTGGTGTCCTAGAGGTCGTTCGAATATCCCGGTCTGGATTTCCCACGAGAATGTTTCATCATAAATTTGCCC GAAGGTATGGTTTCCTTCTGCTGGAGAACATTGCAGCAAAAGATCCTCTAAGTGTTTCGGTTGCAATTCTCCATCAGTTT AATATCTTGCCAGAGATGTACCAAGTTGGCTACACAAAATTGTTTTTCAGAACTGGCCAGATTGGGGTTCTTGAAGATAC AAGGAATCGCACTCTGCATGGCATTTTACGTCTTCAAAGTTATTTTAGAGGGCACCAAGCTCGCTGTCGTCTAAAAGAGC TTAAAACCGGAATTACTATTCTTCAATCATTTGTTCGTGGAGAAAAGATGAGAAAGGAATACACGGAGTTACTGCAGAGG CATCGAGCTTCTGCTGCTATACAAAGCCATGTTAAGAGAAGGATTGCTAGCCAACAGTATAAAGCCACAGTTGATGCATC TGCTGTAATACAATCAGCAATTCGTGGAGAGCTGGTTAGAAGATGTGCGGGGGATATTGGATGGCTTAGTTCTGGTGGCA CCAAGAGAAATGAGTCAGACGAGGTGCTAGTGAAGGCATCATATCTTTCCGATCTTCAGCGTAGGGTTCTTAGAACCGAA GCTGCTCTTCGTGAGAAAGAAGAGGAGAACGACATCCTCCGACAAAGAGTCCAGCAGTACGATAACCGGTGGTCTGAATA TGAAACAAAGATGAAATCCATGGAAGAAATTTGGCAAAAGCAGATGAAATCTTTGCAATCCAGTCTTTCCATCGCAAAGA AAAGCCTAGAGGTTGAGGACTCAGCGAGAAACTCGGATGCATCGGTGAATGCAAGCGATGCAACAGATTTAGATTCAGGA GGTAGTCATTACCAAATGGGCCATGGCAGGTCAAGAAGTGTAGGCGTGGGTTTAAGCGTGATAAGCCGGTTAGCTGAGGA ATTTGGACAAAGAGCTCAGGTATTTGGTGACGACAGAAAGTTCTTGATGGAAGTGAAATCTGGTCAGGTGGAAGCAAACT TGAATCCGGACCGGGAGCTACGAAGGCTGAAACAGATGTTTGAGACATGGAAGAAAGATTATGGAGGGAGACTAAGGGAA ACGAAACTGATACTTAGCAAACTTGGGAGTGAAGAAACAGGTGGTTCAGCGGAGAAGGTGAAGATGAATTGGTGGGGGAG GTTGAGGAGTACTAGGTATTAA |
| Microexon DNA seq | TTTTACTAGAAAAG |
| Microexon Amino Acid seq | FLLEK |
| Microexon-tag DNA Seq | CATTTTAGTGAAACAGGGAAGATTTCGGGTGCTCAAATTCAAACATTTTTACTAGAAAAGTCAAGAGTGGTTCAATGTACGGAAGGAGAAAGGTCATATCATATATTC |
| Microexon-tag Amino Acid seq | HFSETGKISGAQIQTFLLEKSRVVQCTEGERSYHIF |
| Transcript ID | AT1G50360.1 |
| Gene ID | At.4242 |
| Gene Name | VIII-A |
| Pfam domain motif | Myosin_head |
| Motif E-value | 8e-245 |
| Motif start | 159 |
| Motif end | 817 |
| Protein seq | >AT1G50360.1 MAHKVKASFQSLKTMPADYRFLGSPISDHLETNLITPPNGHLKNGVNGTASSVGGMDSVNEDSPYSVRSILNGERSSIGD GDSILPLPESNDRKWSDTNVYARKKVLQFWVQLPNGNWELGKIMSTSGEESVIVVTEGKVLKVKSETLVPANPDILDGVD DLMQLSYLNEPAVLYNLEYRYNQDMIYTKAGPVLVAVNPFKEVPLYGNRNIEAYRKRSNESPHVYAIADTAIREMIRDEV NQSIIISGESGAGKTETAKIAMQYLAALGGGSGIEYEILKTNPILEAFGNAKTLRNDNSSRFGKLIEIHFSETGKISGAQ IQTFLLEKSRVVQCTEGERSYHIFYQLCAGASPTLREKLNLTSAKQYNYLKQSNCYSINGVDDAERFHAVKEALDIVHVS KEDQENVFAMLAAVLWLGNVSFTIIDNENHVEPEPDESLSTVAKLIGCNINELKLALSKRNMRVNNDTIVQKLTLSQAID ARDALAKSIYACLFDWLVEQINKSLAVGKRRTGRSISILDIYGFESFNKNSFEQFCINYANERLQQHFNRHLFKLEQEEY IQDGIDWTRVDFEDNQECLSLFEKKPLGLLSLLDEESTFPNGTDLTLANKLKQHLNDNSCFRGDRGKAFTVAHYAGEVTY ETTGFLEKNRDLLHSDSIQLLSSCSCHLPQAFASSMLIYSEKPLVGPLHKAGGADSQRLSVATKFKGQLFQLMQRLGNTT PHFIRCIKPNNVQSAGLYEQGLVLQQLRCCGVLEVVRISRSGFPTRMFHHKFARRYGFLLLENIAAKDPLSVSVAILHQF NILPEMYQVGYTKLFFRTGQIGVLEDTRNRTLHGILRLQSYFRGHQARCRLKELKTGITILQSFVRGEKMRKEYTELLQR HRASAAIQSHVKRRIASQQYKATVDASAVIQSAIRGELVRRCAGDIGWLSSGGTKRNESDEVLVKASYLSDLQRRVLRTE AALREKEEENDILRQRVQQYDNRWSEYETKMKSMEEIWQKQMKSLQSSLSIAKKSLEVEDSARNSDASVNASDATDLDSG GSHYQMGHGRSRSVGVGLSVISRLAEEFGQRAQVFGDDRKFLMEVKSGQVEANLNPDRELRRLKQMFETWKKDYGGRLRE TKLILSKLGSEETGGSAEKVKMNWWGRLRSTRY* |
| CDS seq | >AT1G50360.1 ATGGCACACAAGGTTAAGGCATCTTTTCAGTCACTTAAAACGATGCCGGCTGACTATAGATTTCTTGGTTCACCAATCTC TGATCACCTTGAGACCAATTTGATTACTCCACCAAATGGTCACTTAAAGAATGGGGTTAATGGCACTGCAAGTTCTGTTG GTGGAATGGATAGTGTTAATGAGGATTCACCTTATAGTGTCCGCAGCATTTTAAATGGAGAGCGGTCTTCAATTGGTGAT GGAGATTCTATTTTGCCCTTGCCTGAGAGTAATGATCGCAAGTGGAGCGACACAAATGTATATGCTCGGAAAAAGGTACT GCAATTTTGGGTCCAACTTCCAAACGGTAACTGGGAGCTGGGAAAGATAATGTCAACTTCAGGAGAAGAGTCTGTTATCG TGGTAACTGAGGGAAAAGTTTTAAAAGTCAAATCAGAGACTTTAGTACCTGCAAATCCTGATATTCTTGATGGAGTAGAC GATCTCATGCAACTAAGTTATTTAAATGAGCCAGCAGTGTTGTACAACCTTGAGTATAGGTACAACCAGGACATGATATA TACAAAAGCAGGGCCGGTTCTGGTGGCTGTGAATCCCTTCAAGGAGGTTCCTTTGTACGGTAATCGCAACATTGAAGCAT ACAGGAAGAGATCAAATGAGAGCCCTCATGTCTATGCTATTGCAGATACAGCAATACGTGAAATGATACGAGATGAAGTT AACCAATCAATCATTATCAGTGGAGAGAGTGGAGCAGGAAAGACTGAGACAGCAAAGATAGCGATGCAATACTTGGCTGC TCTTGGAGGTGGAAGTGGGATCGAGTATGAGATACTAAAGACTAATCCCATCTTGGAAGCATTTGGAAATGCAAAAACAT TGAGAAACGATAATTCTAGTCGTTTTGGTAAGTTGATAGAAATTCATTTTAGTGAAACAGGGAAGATTTCGGGTGCTCAA ATTCAAACATTTTTACTAGAAAAGTCAAGAGTGGTTCAATGTACGGAAGGAGAAAGGTCATATCATATATTCTATCAACT TTGTGCTGGGGCTTCACCTACACTTAGAGAGAAGTTAAATTTGACAAGTGCAAAACAGTATAACTATTTGAAACAAAGCA ATTGCTATTCAATTAACGGAGTTGATGACGCTGAACGTTTTCACGCCGTTAAGGAAGCTTTAGATATTGTGCATGTTAGT AAAGAAGATCAAGAAAATGTATTTGCAATGCTTGCTGCAGTATTATGGCTAGGGAATGTTTCTTTTACCATTATTGACAA CGAAAATCACGTTGAACCTGAACCAGATGAAAGTTTGTCAACTGTTGCTAAATTGATTGGGTGCAACATCAATGAGCTTA AGCTAGCTCTATCAAAGCGTAATATGAGAGTTAATAATGATACTATTGTACAGAAGCTAACACTATCGCAGGCCATTGAC GCAAGAGATGCTTTAGCAAAGTCAATCTATGCCTGCCTATTTGACTGGCTAGTTGAACAGATTAACAAATCTCTTGCGGT GGGAAAGAGGAGAACTGGCAGATCCATCAGCATTCTTGATATCTATGGCTTTGAATCATTCAATAAAAATAGTTTTGAGC AGTTCTGTATAAATTATGCAAATGAGAGATTGCAGCAACACTTCAACCGTCATCTCTTCAAGCTTGAGCAGGAGGAATAT ATTCAGGATGGCATTGACTGGACAAGGGTTGATTTTGAGGACAACCAAGAATGTCTTAGTCTCTTTGAAAAGAAACCATT AGGGCTGCTTTCTCTTCTGGATGAGGAATCCACATTTCCAAATGGCACAGATTTGACACTTGCCAACAAGCTTAAACAAC ATCTAAATGATAATTCCTGTTTTAGAGGAGATCGGGGGAAGGCTTTCACAGTTGCGCATTATGCTGGAGAGGTTACATAT GAGACGACTGGATTTCTAGAGAAGAACCGAGATTTGTTGCATTCAGATTCTATTCAACTTTTGTCGTCTTGCTCTTGCCA CCTCCCTCAGGCGTTTGCTTCTAGTATGCTCATTTATTCTGAAAAACCTCTTGTCGGTCCTTTACACAAAGCAGGTGGAG CTGATTCCCAGCGACTGAGTGTAGCAACTAAATTTAAGGGTCAACTTTTCCAATTGATGCAACGTCTAGGGAACACTACC CCACATTTTATTCGCTGCATAAAGCCAAACAATGTTCAGTCTGCCGGGTTGTATGAGCAAGGACTTGTCTTACAGCAGCT AAGATGTTGTGGTGTCCTAGAGGTCGTTCGAATATCCCGGTCTGGATTTCCCACGAGAATGTTTCATCATAAATTTGCCC GAAGGTATGGTTTCCTTCTGCTGGAGAACATTGCAGCAAAAGATCCTCTAAGTGTTTCGGTTGCAATTCTCCATCAGTTT AATATCTTGCCAGAGATGTACCAAGTTGGCTACACAAAATTGTTTTTCAGAACTGGCCAGATTGGGGTTCTTGAAGATAC AAGGAATCGCACTCTGCATGGCATTTTACGTCTTCAAAGTTATTTTAGAGGGCACCAAGCTCGCTGTCGTCTAAAAGAGC TTAAAACCGGAATTACTATTCTTCAATCATTTGTTCGTGGAGAAAAGATGAGAAAGGAATACACGGAGTTACTGCAGAGG CATCGAGCTTCTGCTGCTATACAAAGCCATGTTAAGAGAAGGATTGCTAGCCAACAGTATAAAGCCACAGTTGATGCATC TGCTGTAATACAATCAGCAATTCGTGGAGAGCTGGTTAGAAGATGTGCGGGGGATATTGGATGGCTTAGTTCTGGTGGCA CCAAGAGAAATGAGTCAGACGAGGTGCTAGTGAAGGCATCATATCTTTCCGATCTTCAGCGTAGGGTTCTTAGAACCGAA GCTGCTCTTCGTGAGAAAGAAGAGGAGAACGACATCCTCCGACAAAGAGTCCAGCAGTACGATAACCGGTGGTCTGAATA TGAAACAAAGATGAAATCCATGGAAGAAATTTGGCAAAAGCAGATGAAATCTTTGCAATCCAGTCTTTCCATCGCAAAGA AAAGCCTAGAGGTTGAGGACTCAGCGAGAAACTCGGATGCATCGGTGAATGCAAGCGATGCAACAGATTTAGATTCAGGA GGTAGTCATTACCAAATGGGCCATGGCAGGTCAAGAAGTGTAGGCGTGGGTTTAAGCGTGATAAGCCGGTTAGCTGAGGA ATTTGGACAAAGAGCTCAGGTATTTGGTGACGACAGAAAGTTCTTGATGGAAGTGAAATCTGGTCAGGTGGAAGCAAACT TGAATCCGGACCGGGAGCTACGAAGGCTGAAACAGATGTTTGAGACATGGAAGAAAGATTATGGAGGGAGACTAAGGGAA ACGAAACTGATACTTAGCAAACTTGGGAGTGAAGAAACAGGTGGTTCAGCGGAGAAGGTGAAGATGAATTGGTGGGGGAG GTTGAGGAGTACTAGGTATTAA |