| Microexon ID | Ps_NC_039368.1:82075849-82075861:+ |
| Species | Papaver somniferum | Coordinates | NC_039368.1:82075849..82075861 |
| Microexon Cluster ID | MEP32 |
| Size | 13 |
| Phase | 0 |
| Pfam Domain Motif | MCM6_C |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,13,47 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | AMYRTTGAWSTKWCWGATGTYCTYTCTARYTTCCCKGACATMTCARTGGHWCTGRYTGAAGAWATYATGGAKARRCTWSTWAAMSAWRRTRTACTRTCAARRRCRGGA |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 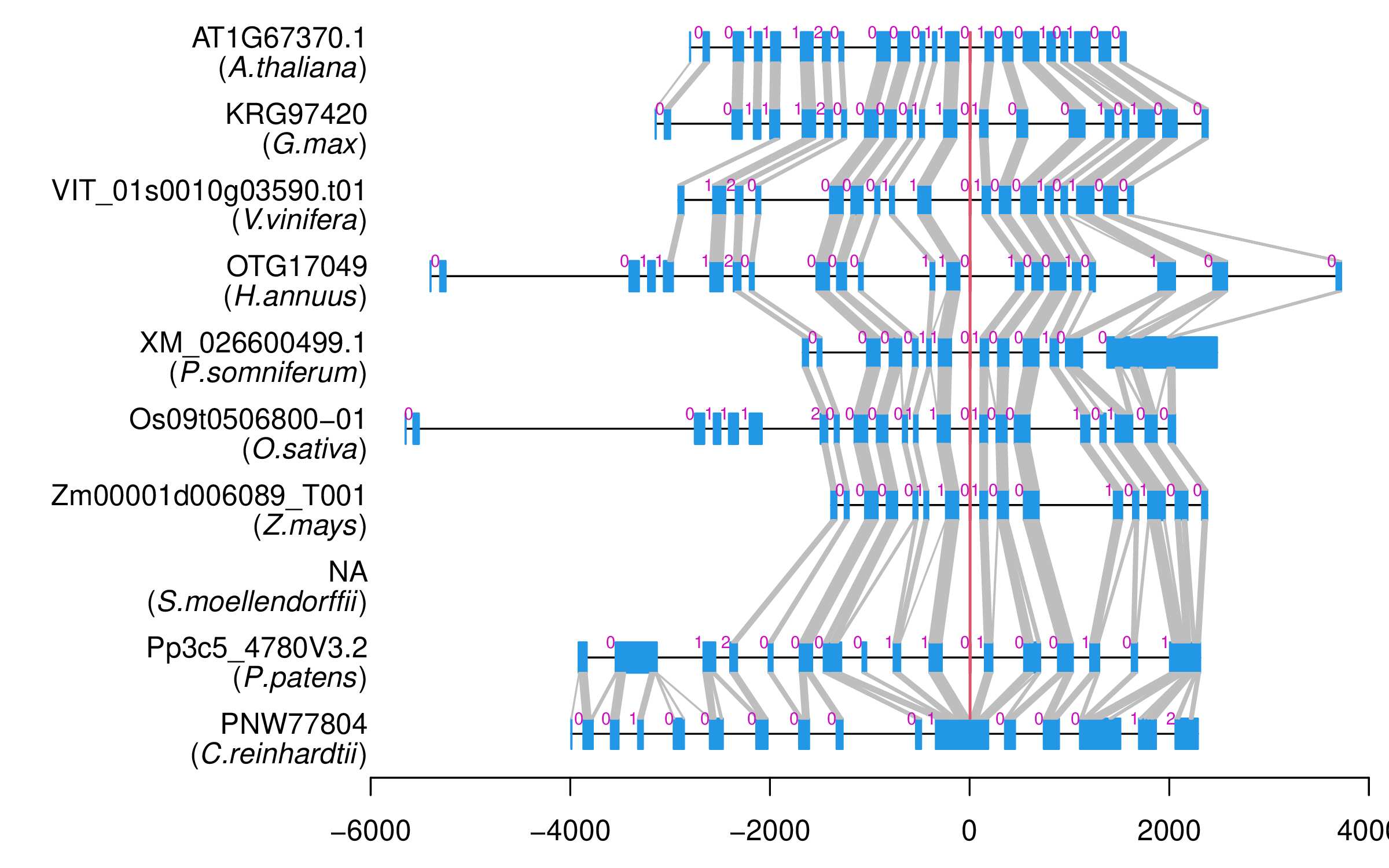 |
| Microexon DNA seq | GGTCTGACTGAAG |
| Microexon Amino Acid seq | GLTEE |
| Microexon-tag DNA Seq | AATGTTGAATTGACTGATGTTCTCTCTAGCTTCCCGGACATATCAGTGGGTCTGACTGAAGAAATCATGGATAAACTTGTAAACCAAAATATACTGTCAAGAACGGGA |
| Microexon-tag Amino Acid Seq | NVELTDVLSSFPDISVGLTEEIMDKLVNQNILSRTG |
| Microexon-tag spanning region | 82075476-82076004 |
| Microexon-tag prediction score | 0.9804 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026569184.1x |
| Reference Transcript ID | XM_026569184.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026569184.1 |
| Protein ID | XP_026424969.1 |
| Gene ID | LOC113321286 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026424969.1 MVVAQKLKEAEITEQDSLLLTRNLLRIAIFNISYIRGLFPENYFNDKSVPALEMKIKKLMPIDAESRRLIDWMEKGVYDA LQKKYLKTLLFCISEAIDGPMIEEYAFSFSYSNSDSEEVMMNISRTGNKKQGATFKSNGNTDITPNQMRSSACKMVRTLV QLMRTLDRIPEERTILMKLLYYEDVTPIDYEPPFFRGCSEQEANHPWSKNPLKMEIGNVNSKHFVLALKVKSILDPCQDE NNDMEDDEEISLGVSDSDSEMSHSANDDDGYFVAPVDKSRSRENNGMPDHEDDTQDAEEDGHQLTRVRDWISSRHIDNVE LTDVLSSFPDISVGLTEEIMDKLVNQNILSRTGKDSYSISKLKKPNQAIVVKEEMDVQVNQVDEKVQRGNDEDYLYLKAL YHVLPLDYVTISKLQSKLEGEANQATARKLLDKMACDGYLEAKSKPRLGKRVIRSELTDKKLLEVKNVLEIKLSEMEISE PQNISTCGGLHSVGSDLTRTRERSVDTQQNGSSRIQEQLGNNTPIGRNEPAVSRESGIPGNDKQNIVDERGFTNCREGDD TFCSRPRHEKRFRKTSTVKEPIHQNMKRQKSQGGGALE* |
| CDS seq | >XM_026569184.1 ATGGTTGTGGCACAGAAACTCAAGGAAGCAGAAATTACAGAACAGGATTCTCTATTACTGACGAGAAACCTGCTACGTAT TGCGATATTCAACATCAGCTACATCAGAGGGCTTTTCCCTGAAAATTACTTCAATGATAAATCAGTTCCTGCTTTAGAGA TGAAGATCAAGAAGCTCATGCCTATAGATGCTGAATCCAGAAGACTTATTGACTGGATGGAAAAAGGTGTTTATGATGCG TTACAGAAGAAATACCTCAAGACACTTCTGTTCTGCATATCTGAAGCTATTGATGGACCTATGATAGAAGAATATGCTTT TTCATTTAGCTATTCGAATTCTGACAGTGAAGAGGTGATGATGAACATAAGTCGAACTGGAAATAAAAAACAAGGAGCAA CATTCAAGTCTAATGGCAATACAGACATTACACCAAACCAAATGAGGAGTTCTGCTTGTAAAATGGTCCGAACTCTGGTT CAATTGATGCGAACACTGGACCGTATTCCAGAAGAGCGTACAATCTTGATGAAGCTTCTTTATTATGAGGATGTCACTCC TATAGACTATGAGCCTCCATTCTTCAGAGGCTGCTCAGAACAAGAAGCTAACCATCCATGGTCGAAGAACCCTCTCAAAA TGGAAATCGGGAATGTTAACAGCAAACATTTTGTACTAGCTCTCAAGGTCAAAAGCATCCTGGATCCATGTCAAGATGAA AACAATGACATGGAAGATGATGAGGAAATCAGCTTGGGTGTTTCAGATTCAGATAGCGAGATGAGCCATTCAGCAAATGA TGATGACGGGTACTTTGTAGCTCCTGTAGATAAATCCCGATCACGTGAAAACAATGGCATGCCGGATCATGAAGATGATA CACAGGATGCAGAAGAGGACGGACATCAGTTAACACGTGTAAGAGACTGGATTAGCTCTCGCCACATTGACAATGTTGAA TTGACTGATGTTCTCTCTAGCTTCCCGGACATATCAGTGGGTCTGACTGAAGAAATCATGGATAAACTTGTAAACCAAAA TATACTGTCAAGAACGGGAAAGGATTCTTACTCCATCAGCAAGCTGAAGAAACCCAATCAGGCAATTGTCGTGAAGGAAG AGATGGATGTACAAGTAAACCAAGTTGATGAGAAAGTTCAGCGAGGGAATGATGAAGACTACTTGTACTTGAAGGCTCTG TATCATGTCCTTCCACTGGATTATGTTACAATATCTAAACTTCAAAGTAAGCTGGAAGGAGAGGCAAATCAGGCAACTGC GCGTAAACTGCTCGATAAGATGGCTTGTGATGGATATTTGGAAGCCAAGAGCAAACCAAGATTAGGTAAACGTGTCATTC GATCTGAATTGACTGACAAGAAGCTACTTGAGGTCAAGAATGTTTTGGAGATCAAGTTATCGGAAATGGAGATAAGTGAA CCTCAAAACATATCAACCTGCGGTGGTCTCCACTCTGTTGGTTCTGATCTTACTAGAACTCGAGAAAGATCAGTTGATAC TCAGCAGAATGGATCGTCTAGAATCCAGGAGCAACTTGGAAACAACACACCCATTGGCAGAAATGAGCCTGCAGTGTCAA GGGAGAGTGGTATACCAGGGAATGATAAGCAAAACATTGTGGATGAGAGAGGATTCACCAACTGTCGTGAGGGTGATGAT ACCTTCTGTAGTCGTCCCAGGCATGAAAAGCGCTTCAGGAAAACTAGCACGGTGAAAGAGCCCATCCATCAAAACATGAA GCGTCAGAAATCTCAAGGTGGTGGCGCATTGGAGTAA |
| Microexon DNA seq | GGTCTGACTGAAG |
| Microexon Amino Acid seq | GLTEE |
| Microexon-tag DNA Seq | AATGTTGAATTGACTGATGTTCTCTCTAGCTTCCCGGACATATCAGTGGGTCTGACTGAAGAAATCATGGATAAACTTGTAAACCAAAATATACTGTCAAGAACGGGA |
| Microexon-tag Amino Acid seq | NVELTDVLSSFPDISVGLTEEIMDKLVNQNILSRTG |
| Transcript ID | XM_026569184.1 |
| Gene ID | Ps.66696 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026569184.1 MVVAQKLKEAEITEQDSLLLTRNLLRIAIFNISYIRGLFPENYFNDKSVPALEMKIKKLMPIDAESRRLIDWMEKGVYDA LQKKYLKTLLFCISEAIDGPMIEEYAFSFSYSNSDSEEVMMNISRTGNKKQGATFKSNGNTDITPNQMRSSACKMVRTLV QLMRTLDRIPEERTILMKLLYYEDVTPIDYEPPFFRGCSEQEANHPWSKNPLKMEIGNVNSKHFVLALKVKSILDPCQDE NNDMEDDEEISLGVSDSDSEMSHSANDDDGYFVAPVDKSRSRENNGMPDHEDDTQDAEEDGHQLTRVRDWISSRHIDNVE LTDVLSSFPDISVGLTEEIMDKLVNQNILSRTGKDSYSISKLKKPNQAIVVKEEMDVQVNQVDEKVQRGNDEDYLYLKAL YHVLPLDYVTISKLQSKLEGEANQATARKLLDKMACDGYLEAKSKPRLGKRVIRSELTDKKLLEVKNVLEIKLSEMEISE PQNISTCGGLHSVGSDLTRTRERSVDTQQNGSSRIQEQLGNNTPIGRNEPAVSRESGIPGNDKQNIVDERGFTNCREGDD TFCSRPRHEKRFRKTSTVKEPIHQNMKRQKSQGGGALE* |
| CDS seq | >XM_026569184.1 ATGGTTGTGGCACAGAAACTCAAGGAAGCAGAAATTACAGAACAGGATTCTCTATTACTGACGAGAAACCTGCTACGTAT TGCGATATTCAACATCAGCTACATCAGAGGGCTTTTCCCTGAAAATTACTTCAATGATAAATCAGTTCCTGCTTTAGAGA TGAAGATCAAGAAGCTCATGCCTATAGATGCTGAATCCAGAAGACTTATTGACTGGATGGAAAAAGGTGTTTATGATGCG TTACAGAAGAAATACCTCAAGACACTTCTGTTCTGCATATCTGAAGCTATTGATGGACCTATGATAGAAGAATATGCTTT TTCATTTAGCTATTCGAATTCTGACAGTGAAGAGGTGATGATGAACATAAGTCGAACTGGAAATAAAAAACAAGGAGCAA CATTCAAGTCTAATGGCAATACAGACATTACACCAAACCAAATGAGGAGTTCTGCTTGTAAAATGGTCCGAACTCTGGTT CAATTGATGCGAACACTGGACCGTATTCCAGAAGAGCGTACAATCTTGATGAAGCTTCTTTATTATGAGGATGTCACTCC TATAGACTATGAGCCTCCATTCTTCAGAGGCTGCTCAGAACAAGAAGCTAACCATCCATGGTCGAAGAACCCTCTCAAAA TGGAAATCGGGAATGTTAACAGCAAACATTTTGTACTAGCTCTCAAGGTCAAAAGCATCCTGGATCCATGTCAAGATGAA AACAATGACATGGAAGATGATGAGGAAATCAGCTTGGGTGTTTCAGATTCAGATAGCGAGATGAGCCATTCAGCAAATGA TGATGACGGGTACTTTGTAGCTCCTGTAGATAAATCCCGATCACGTGAAAACAATGGCATGCCGGATCATGAAGATGATA CACAGGATGCAGAAGAGGACGGACATCAGTTAACACGTGTAAGAGACTGGATTAGCTCTCGCCACATTGACAATGTTGAA TTGACTGATGTTCTCTCTAGCTTCCCGGACATATCAGTGGGTCTGACTGAAGAAATCATGGATAAACTTGTAAACCAAAA TATACTGTCAAGAACGGGAAAGGATTCTTACTCCATCAGCAAGCTGAAGAAACCCAATCAGGCAATTGTCGTGAAGGAAG AGATGGATGTACAAGTAAACCAAGTTGATGAGAAAGTTCAGCGAGGGAATGATGAAGACTACTTGTACTTGAAGGCTCTG TATCATGTCCTTCCACTGGATTATGTTACAATATCTAAACTTCAAAGTAAGCTGGAAGGAGAGGCAAATCAGGCAACTGC GCGTAAACTGCTCGATAAGATGGCTTGTGATGGATATTTGGAAGCCAAGAGCAAACCAAGATTAGGTAAACGTGTCATTC GATCTGAATTGACTGACAAGAAGCTACTTGAGGTCAAGAATGTTTTGGAGATCAAGTTATCGGAAATGGAGATAAGTGAA CCTCAAAACATATCAACCTGCGGTGGTCTCCACTCTGTTGGTTCTGATCTTACTAGAACTCGAGAAAGATCAGTTGATAC TCAGCAGAATGGATCGTCTAGAATCCAGGAGCAACTTGGAAACAACACACCCATTGGCAGAAATGAGCCTGCAGTGTCAA GGGAGAGTGGTATACCAGGGAATGATAAGCAAAACATTGTGGATGAGAGAGGATTCACCAACTGTCGTGAGGGTGATGAT ACCTTCTGTAGTCGTCCCAGGCATGAAAAGCGCTTCAGGAAAACTAGCACGGTGAAAGAGCCCATCCATCAAAACATGAA GCGTCAGAAATCTCAAGGTGGTGGCGCATTGGAGTAA |