| Microexon ID | Ps_NC_039366.1:29998045-29998057:+ |
| Species | Papaver somniferum | Coordinates | NC_039366.1:29998045..29998057 |
| Microexon Cluster ID | MEP32 |
| Size | 13 |
| Phase | 0 |
| Pfam Domain Motif | MCM6_C |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,13,47 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | AMYRTTGAWSTKWCWGATGTYCTYTCTARYTTCCCKGACATMTCARTGGHWCTGRYTGAAGAWATYATGGAKARRCTWSTWAAMSAWRRTRTACTRTCAARRRCRGGA |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 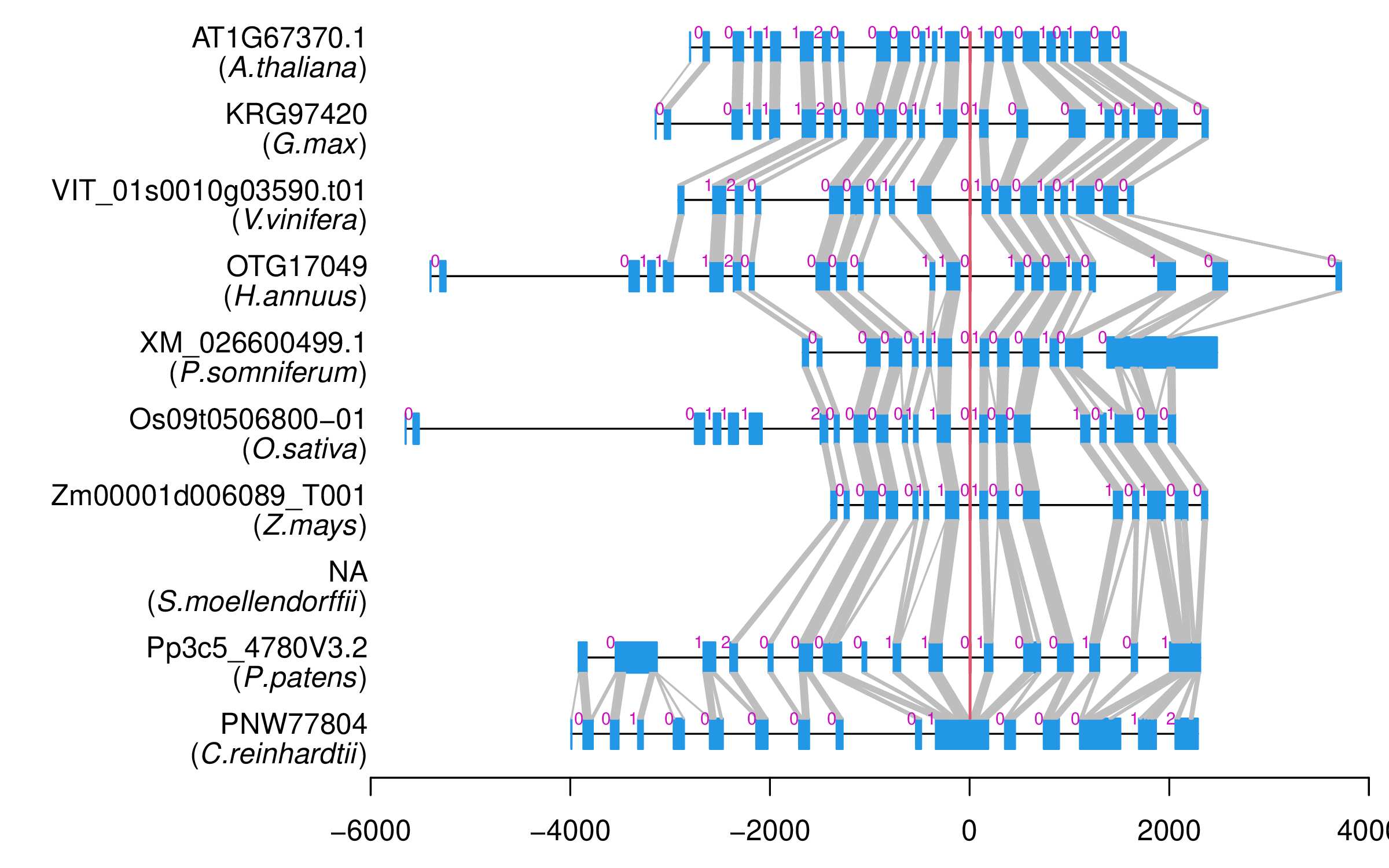 |
| Microexon DNA seq | GCTCTGACTGAAG |
| Microexon Amino Acid seq | ALTEE |
| Microexon-tag DNA Seq | AATGTTGAACTGACTGATGTTCTCTCTAGCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAATCATGGATAAACTTGTAAACCAAAATATACTGTCAAGAACGGGA |
| Microexon-tag Amino Acid Seq | NVELTDVLSSFPDISVALTEEIMDKLVNQNILSRTG |
| Microexon-tag spanning region | 29997675-29998200 |
| Microexon-tag prediction score | 0.9908 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026562358.1x |
| Reference Transcript ID | XM_026562358.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026562358.1 |
| Protein ID | XP_026418143.1 |
| Gene ID | LOC113313565 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026418143.1 MVVAQKLKEAEITEQDSLLLTRNLLRIAIFNISYIRGLFPENYFNDKSVPALEMKIKKLMPMDAESRRLIDWMEKGVYDA LQKKYLKTLLFCISEAIDGPMIEEYAFSFSYSNSDSKEVMMNISRTGNKKQGATFKSNGNTDITPNQMRNSACKMVRTLV QLMRTLDRMPEERTILMKLLYYEDVTPIDYEPPFFRGCSEQEANYPWLKNPLKMEIGNVNSKHFVLALKVKSILDPCQDE NNDMEDDEEISLGVDSTPTTDPSDSDSEMSHSANDVDGYIVAPVDKAQSRENNGMSDHEDDTQDAEEDEHQFTRVRDWIS SYHIDNVELTDVLSSFPDISVALTEEIMDKLVNQNILSRTGKDSYSISKLKKPNQANVVKEEMGLQVNQVDEKVQRGNDE DYLYLKALYHVLPLDYVTISKLQSKLEGEANQATVRKLLDKMACDGYVEAKSKPRLGKRVIRSELTGKKLLEVKNVLEIK LSAMEISEPQNISTCGGLHSVGSDLTRTRERSVDTQQNGSSRIQEQLRNNTPIGRNEPAVSRESGIPGSDKRNGVDGRGF TNCREGDDTFCSRPSHEKRSRKTSTVKDPIHQNIKRQKSQGGGALE* |
| CDS seq | >XM_026562358.1 ATGGTTGTGGCACAGAAACTCAAGGAAGCAGAAATTACAGAACAGGATTCTCTGTTACTGACGAGAAACCTGCTTCGTAT TGCGATATTCAACATCAGCTACATCAGAGGGCTTTTCCCCGAAAATTACTTCAATGATAAATCAGTTCCTGCTCTAGAGA TGAAGATCAAGAAGCTCATGCCTATGGATGCTGAATCCAGAAGACTTATTGACTGGATGGAAAAAGGTGTTTATGATGCA TTACAGAAGAAATACCTTAAGACACTTCTGTTCTGCATATCTGAAGCTATTGATGGACCTATGATAGAAGAATATGCTTT TTCATTTAGCTATTCGAATTCTGACAGTAAAGAGGTGATGATGAACATAAGTCGTACTGGGAATAAAAAACAAGGAGCAA CATTCAAGTCTAATGGCAATACAGACATTACACCAAACCAAATGAGGAATTCTGCTTGTAAAATGGTCCGAACTCTGGTT CAATTGATGCGAACACTGGATCGTATGCCAGAAGAGCGTACAATCTTGATGAAGCTTCTTTATTATGAGGATGTCACTCC TATAGACTATGAGCCTCCATTCTTCAGAGGCTGCTCAGAACAAGAAGCTAACTATCCATGGTTGAAGAACCCTCTCAAAA TGGAAATCGGAAATGTTAACAGCAAACATTTCGTACTAGCTCTCAAGGTCAAAAGCATCCTGGATCCATGTCAAGATGAA AACAATGACATGGAAGATGATGAGGAAATCAGCTTGGGTGTTGATTCAACGCCAACAACTGATCCTTCAGATTCAGATAG CGAGATGAGCCATTCAGCAAATGATGTCGACGGGTACATTGTAGCTCCTGTAGACAAAGCGCAATCACGTGAAAACAATG GCATGTCAGATCATGAAGATGATACACAGGATGCAGAGGAGGACGAACATCAGTTCACACGTGTAAGAGACTGGATTAGC TCTTACCACATTGACAATGTTGAACTGACTGATGTTCTCTCTAGCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAAT CATGGATAAACTTGTAAACCAAAATATACTGTCAAGAACGGGAAAGGATTCTTACTCCATCAGCAAGCTGAAGAAACCCA ATCAGGCAAATGTCGTGAAGGAAGAGATGGGCCTACAAGTAAACCAAGTTGATGAGAAAGTTCAGCGAGGGAATGATGAA GACTACTTGTACTTGAAGGCTCTGTATCATGTCCTTCCACTGGATTATGTTACAATATCTAAACTTCAAAGTAAGCTGGA AGGAGAGGCAAATCAGGCAACTGTGCGTAAACTGCTCGATAAGATGGCTTGTGATGGATATGTGGAAGCCAAGAGCAAAC CAAGATTAGGTAAACGTGTCATTCGATCTGAATTAACTGGCAAGAAGCTACTTGAGGTCAAGAATGTTTTGGAGATCAAG TTATCGGCAATGGAGATAAGTGAACCTCAAAACATATCAACCTGCGGTGGTCTCCACTCTGTTGGTTCTGATCTTACTAG AACTCGAGAAAGATCAGTTGATACTCAGCAGAATGGATCGTCTAGAATTCAGGAGCAACTTAGAAACAACACACCCATTG GCAGAAATGAGCCTGCAGTGTCAAGGGAGAGTGGTATACCAGGGAGCGATAAGCGAAATGGTGTGGATGGGAGAGGATTC ACTAACTGTCGTGAAGGTGATGATACCTTCTGTAGTCGTCCCAGTCATGAAAAGCGTTCCAGGAAAACTAGCACGGTGAA AGATCCCATCCATCAAAACATTAAGCGTCAGAAATCTCAAGGTGGTGGCGCGTTGGAGTAA |
| Microexon DNA seq | GCTCTGACTGAAG |
| Microexon Amino Acid seq | ALTEE |
| Microexon-tag DNA Seq | AATGTTGAACTGACTGATGTTCTCTCTAGCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAATCATGGATAAACTTGTAAACCAAAATATACTGTCAAGAACGGGA |
| Microexon-tag Amino Acid seq | NVELTDVLSSFPDISVALTEEIMDKLVNQNILSRTG |
| Transcript ID | XM_026562358.1 |
| Gene ID | Ps.54220 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026562358.1 MVVAQKLKEAEITEQDSLLLTRNLLRIAIFNISYIRGLFPENYFNDKSVPALEMKIKKLMPMDAESRRLIDWMEKGVYDA LQKKYLKTLLFCISEAIDGPMIEEYAFSFSYSNSDSKEVMMNISRTGNKKQGATFKSNGNTDITPNQMRNSACKMVRTLV QLMRTLDRMPEERTILMKLLYYEDVTPIDYEPPFFRGCSEQEANYPWLKNPLKMEIGNVNSKHFVLALKVKSILDPCQDE NNDMEDDEEISLGVDSTPTTDPSDSDSEMSHSANDVDGYIVAPVDKAQSRENNGMSDHEDDTQDAEEDEHQFTRVRDWIS SYHIDNVELTDVLSSFPDISVALTEEIMDKLVNQNILSRTGKDSYSISKLKKPNQANVVKEEMGLQVNQVDEKVQRGNDE DYLYLKALYHVLPLDYVTISKLQSKLEGEANQATVRKLLDKMACDGYVEAKSKPRLGKRVIRSELTGKKLLEVKNVLEIK LSAMEISEPQNISTCGGLHSVGSDLTRTRERSVDTQQNGSSRIQEQLRNNTPIGRNEPAVSRESGIPGSDKRNGVDGRGF TNCREGDDTFCSRPSHEKRSRKTSTVKDPIHQNIKRQKSQGGGALE* |
| CDS seq | >XM_026562358.1 ATGGTTGTGGCACAGAAACTCAAGGAAGCAGAAATTACAGAACAGGATTCTCTGTTACTGACGAGAAACCTGCTTCGTAT TGCGATATTCAACATCAGCTACATCAGAGGGCTTTTCCCCGAAAATTACTTCAATGATAAATCAGTTCCTGCTCTAGAGA TGAAGATCAAGAAGCTCATGCCTATGGATGCTGAATCCAGAAGACTTATTGACTGGATGGAAAAAGGTGTTTATGATGCA TTACAGAAGAAATACCTTAAGACACTTCTGTTCTGCATATCTGAAGCTATTGATGGACCTATGATAGAAGAATATGCTTT TTCATTTAGCTATTCGAATTCTGACAGTAAAGAGGTGATGATGAACATAAGTCGTACTGGGAATAAAAAACAAGGAGCAA CATTCAAGTCTAATGGCAATACAGACATTACACCAAACCAAATGAGGAATTCTGCTTGTAAAATGGTCCGAACTCTGGTT CAATTGATGCGAACACTGGATCGTATGCCAGAAGAGCGTACAATCTTGATGAAGCTTCTTTATTATGAGGATGTCACTCC TATAGACTATGAGCCTCCATTCTTCAGAGGCTGCTCAGAACAAGAAGCTAACTATCCATGGTTGAAGAACCCTCTCAAAA TGGAAATCGGAAATGTTAACAGCAAACATTTCGTACTAGCTCTCAAGGTCAAAAGCATCCTGGATCCATGTCAAGATGAA AACAATGACATGGAAGATGATGAGGAAATCAGCTTGGGTGTTGATTCAACGCCAACAACTGATCCTTCAGATTCAGATAG CGAGATGAGCCATTCAGCAAATGATGTCGACGGGTACATTGTAGCTCCTGTAGACAAAGCGCAATCACGTGAAAACAATG GCATGTCAGATCATGAAGATGATACACAGGATGCAGAGGAGGACGAACATCAGTTCACACGTGTAAGAGACTGGATTAGC TCTTACCACATTGACAATGTTGAACTGACTGATGTTCTCTCTAGCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAAT CATGGATAAACTTGTAAACCAAAATATACTGTCAAGAACGGGAAAGGATTCTTACTCCATCAGCAAGCTGAAGAAACCCA ATCAGGCAAATGTCGTGAAGGAAGAGATGGGCCTACAAGTAAACCAAGTTGATGAGAAAGTTCAGCGAGGGAATGATGAA GACTACTTGTACTTGAAGGCTCTGTATCATGTCCTTCCACTGGATTATGTTACAATATCTAAACTTCAAAGTAAGCTGGA AGGAGAGGCAAATCAGGCAACTGTGCGTAAACTGCTCGATAAGATGGCTTGTGATGGATATGTGGAAGCCAAGAGCAAAC CAAGATTAGGTAAACGTGTCATTCGATCTGAATTAACTGGCAAGAAGCTACTTGAGGTCAAGAATGTTTTGGAGATCAAG TTATCGGCAATGGAGATAAGTGAACCTCAAAACATATCAACCTGCGGTGGTCTCCACTCTGTTGGTTCTGATCTTACTAG AACTCGAGAAAGATCAGTTGATACTCAGCAGAATGGATCGTCTAGAATTCAGGAGCAACTTAGAAACAACACACCCATTG GCAGAAATGAGCCTGCAGTGTCAAGGGAGAGTGGTATACCAGGGAGCGATAAGCGAAATGGTGTGGATGGGAGAGGATTC ACTAACTGTCGTGAAGGTGATGATACCTTCTGTAGTCGTCCCAGTCATGAAAAGCGTTCCAGGAAAACTAGCACGGTGAA AGATCCCATCCATCAAAACATTAAGCGTCAGAAATCTCAAGGTGGTGGCGCGTTGGAGTAA |