| Microexon ID | Ps_NC_039365.1:23899430-23899442:- |
| Species | Papaver somniferum | Coordinates | NC_039365.1:23899430..23899442 |
| Microexon Cluster ID | MEP32 |
| Size | 13 |
| Phase | 0 |
| Pfam Domain Motif | MCM6_C |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,13,47 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | AMYRTTGAWSTKWCWGATGTYCTYTCTARYTTCCCKGACATMTCARTGGHWCTGRYTGAAGAWATYATGGAKARRCTWSTWAAMSAWRRTRTACTRTCAARRRCRGGA |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 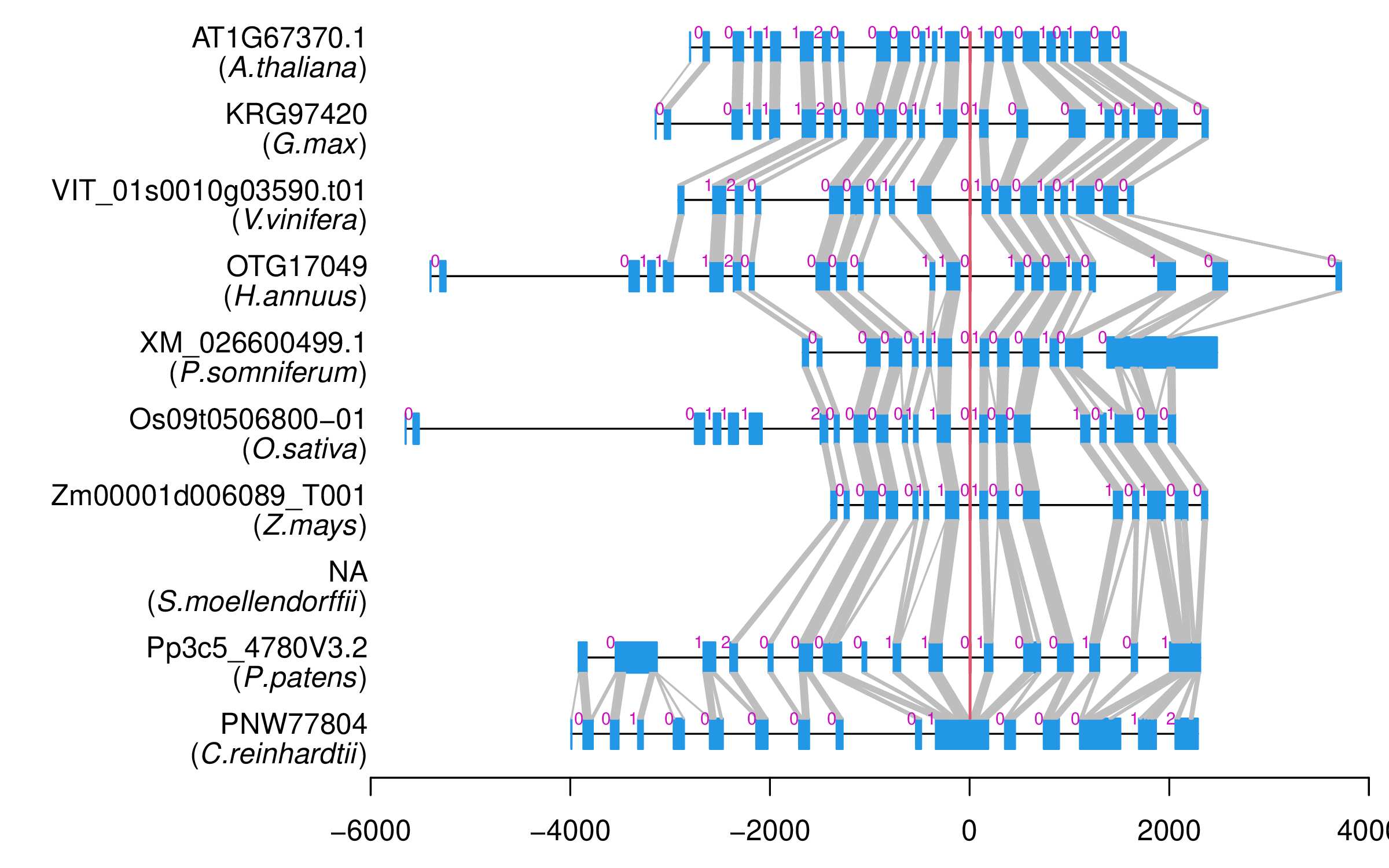 |
| Microexon DNA seq | GCTCTGACTGAAG |
| Microexon Amino Acid seq | ALTEE |
| Microexon-tag DNA Seq | AATGTTGAACTGACTGATGTTCTCTCTAGCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAATCATGGATAAACTTGTAAACCAAAACATACTGTCAAGAACAGGA |
| Microexon-tag Amino Acid Seq | NVELTDVLSSFPDISVALTEEIMDKLVNQNILSRTG |
| Microexon-tag spanning region | 23899287-23899809 |
| Microexon-tag prediction score | 0.9888 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026551649.1x |
| Reference Transcript ID | XM_026551649.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026551649.1 |
| Protein ID | XP_026407434.1 |
| Gene ID | LOC113302704 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026407434.1 MVVAQKLKEAEITEQDSLLLTRNLLRIAIFNISYIRGLFPENYFNDKSVPAIEMKIKKLMPIDAESRRLIDWMEKGVYDA LQKKYLKTLLFCISEAIDGPMIEEYAFSFSYSNSDNEEVMMNISRTGNKNKGATFKSNGNTDVTPNQMRSSACKMVRTLV QLMRTLDRMPEERTILMKLLYYEDVTPIDYEPPFFRGCSEQEANHPWLKNPLKMEIGNVNSKHFVLALKVKSILDPCQDE NNDMEDDEEISLGVDSMPTTDPSDSDSEMSHSANDDDGYIVAPVARSRENNSMTDHEDDTQDAEEDEHQLTRVRDWISSR HIDNVELTDVLSSFPDISVALTEEIMDKLVNQNILSRTGKDSYSISKLKKPNQAIVVKEEMDVQVNQVDEKIQRGNDEDY LYLKALYHVLPLDYVTISKLQSKLEGEANQATVRKLLDKMACDGYVEAKSKPRLGKRVIRSELTDKKLLEVKNVLEIKLS TMEISEPQNISTCGGLHSVGSDLTRTRERSVDTQQNGSSRIQEQLGNNTPIRRNEPAVSRESGIPGSDKRNGVDGRGFTN CREGDDTFCSRPSQEKRSRKTSTVKEPIHQNMKRQKSQGGGALE* |
| CDS seq | >XM_026551649.1 ATGGTTGTAGCACAGAAACTCAAGGAAGCAGAAATTACAGAACAGGATTCTCTATTACTGACGAGAAACCTGCTTCGTAT TGCAATATTCAACATCAGCTACATCAGAGGGCTTTTCCCTGAAAATTACTTCAATGATAAATCAGTTCCTGCTATAGAGA TGAAGATCAAGAAGCTCATGCCTATAGATGCTGAATCCAGAAGACTTATTGATTGGATGGAAAAAGGTGTTTATGATGCA TTACAGAAGAAATACCTTAAGACACTTCTGTTCTGCATATCTGAAGCTATTGATGGACCTATGATAGAAGAATATGCTTT TTCATTTAGCTATTCGAATTCTGACAATGAAGAGGTGATGATGAACATAAGTCGTACTGGAAATAAGAATAAAGGAGCAA CATTCAAGTCTAATGGCAATACAGACGTTACACCAAACCAAATGAGGAGTTCTGCTTGTAAAATGGTCCGAACTCTGGTT CAATTAATGCGAACACTGGACCGTATGCCAGAAGAGCGTACAATTTTGATGAAGCTTCTTTACTATGAGGATGTCACGCC TATAGACTATGAGCCTCCATTCTTCAGAGGCTGCTCAGAACAAGAAGCTAACCATCCATGGTTGAAGAACCCTCTCAAAA TGGAAATCGGAAATGTTAACAGCAAACATTTCGTACTAGCTCTCAAGGTCAAAAGCATCCTGGATCCATGTCAAGATGAA AACAATGACATGGAAGATGATGAGGAAATCAGCTTGGGTGTTGATTCAATGCCAACAACTGATCCTTCGGATTCAGATAG CGAGATGAGCCATTCAGCAAATGACGACGACGGGTACATTGTAGCTCCTGTAGCTCGATCACGTGAAAACAATTCCATGA CGGATCATGAAGATGATACACAGGATGCTGAAGAGGATGAACATCAGTTAACACGTGTAAGAGACTGGATTAGCTCTCGC CACATTGACAATGTTGAACTGACTGATGTTCTCTCTAGCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAATCATGGA TAAACTTGTAAACCAAAACATACTGTCAAGAACAGGAAAGGATTCCTACTCCATCAGCAAGCTGAAGAAACCCAATCAGG CAATTGTTGTGAAGGAAGAGATGGATGTACAAGTAAACCAAGTTGATGAGAAAATTCAGCGAGGGAATGATGAAGACTAC TTGTACTTGAAGGCTCTGTATCATGTCCTTCCACTGGATTATGTTACAATATCTAAACTTCAAAGTAAGCTGGAAGGAGA GGCAAATCAGGCAACTGTGCGTAAACTGCTCGATAAGATGGCTTGTGATGGATATGTGGAAGCCAAGAGTAAACCAAGAT TAGGTAAACGTGTCATTCGATCTGAGTTGACTGACAAGAAGCTACTTGAGGTCAAGAATGTTTTGGAGATTAAGTTATCG ACAATGGAGATAAGTGAACCTCAAAACATATCAACCTGCGGTGGTCTCCACTCTGTTGGTTCTGATCTTACTAGAACCCG AGAAAGATCAGTTGATACTCAGCAGAATGGATCGTCTAGAATTCAGGAGCAACTTGGAAACAACACACCCATTCGCAGAA ATGAGCCTGCAGTGTCAAGGGAGAGCGGTATACCAGGGAGCGATAAGCGAAATGGTGTGGATGGGAGAGGATTCACTAAC TGTCGTGAGGGTGATGATACCTTCTGTAGTCGTCCCAGTCAGGAAAAGCGCTCCAGGAAAACTAGCACGGTGAAAGAGCC CATCCATCAAAACATGAAGCGTCAGAAATCTCAAGGTGGTGGCGCGTTGGAGTAA |
| Microexon DNA seq | GCTCTGACTGAAG |
| Microexon Amino Acid seq | ALTEE |
| Microexon-tag DNA Seq | AATGTTGAACTGACTGATGTTCTCTCTAGCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAATCATGGATAAACTTGTAAACCAAAACATACTGTCAAGAACAGGA |
| Microexon-tag Amino Acid seq | NVELTDVLSSFPDISVALTEEIMDKLVNQNILSRTG |
| Transcript ID | XM_026551649.1 |
| Gene ID | Ps.48439 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026551649.1 MVVAQKLKEAEITEQDSLLLTRNLLRIAIFNISYIRGLFPENYFNDKSVPAIEMKIKKLMPIDAESRRLIDWMEKGVYDA LQKKYLKTLLFCISEAIDGPMIEEYAFSFSYSNSDNEEVMMNISRTGNKNKGATFKSNGNTDVTPNQMRSSACKMVRTLV QLMRTLDRMPEERTILMKLLYYEDVTPIDYEPPFFRGCSEQEANHPWLKNPLKMEIGNVNSKHFVLALKVKSILDPCQDE NNDMEDDEEISLGVDSMPTTDPSDSDSEMSHSANDDDGYIVAPVARSRENNSMTDHEDDTQDAEEDEHQLTRVRDWISSR HIDNVELTDVLSSFPDISVALTEEIMDKLVNQNILSRTGKDSYSISKLKKPNQAIVVKEEMDVQVNQVDEKIQRGNDEDY LYLKALYHVLPLDYVTISKLQSKLEGEANQATVRKLLDKMACDGYVEAKSKPRLGKRVIRSELTDKKLLEVKNVLEIKLS TMEISEPQNISTCGGLHSVGSDLTRTRERSVDTQQNGSSRIQEQLGNNTPIRRNEPAVSRESGIPGSDKRNGVDGRGFTN CREGDDTFCSRPSQEKRSRKTSTVKEPIHQNMKRQKSQGGGALE* |
| CDS seq | >XM_026551649.1 ATGGTTGTAGCACAGAAACTCAAGGAAGCAGAAATTACAGAACAGGATTCTCTATTACTGACGAGAAACCTGCTTCGTAT TGCAATATTCAACATCAGCTACATCAGAGGGCTTTTCCCTGAAAATTACTTCAATGATAAATCAGTTCCTGCTATAGAGA TGAAGATCAAGAAGCTCATGCCTATAGATGCTGAATCCAGAAGACTTATTGATTGGATGGAAAAAGGTGTTTATGATGCA TTACAGAAGAAATACCTTAAGACACTTCTGTTCTGCATATCTGAAGCTATTGATGGACCTATGATAGAAGAATATGCTTT TTCATTTAGCTATTCGAATTCTGACAATGAAGAGGTGATGATGAACATAAGTCGTACTGGAAATAAGAATAAAGGAGCAA CATTCAAGTCTAATGGCAATACAGACGTTACACCAAACCAAATGAGGAGTTCTGCTTGTAAAATGGTCCGAACTCTGGTT CAATTAATGCGAACACTGGACCGTATGCCAGAAGAGCGTACAATTTTGATGAAGCTTCTTTACTATGAGGATGTCACGCC TATAGACTATGAGCCTCCATTCTTCAGAGGCTGCTCAGAACAAGAAGCTAACCATCCATGGTTGAAGAACCCTCTCAAAA TGGAAATCGGAAATGTTAACAGCAAACATTTCGTACTAGCTCTCAAGGTCAAAAGCATCCTGGATCCATGTCAAGATGAA AACAATGACATGGAAGATGATGAGGAAATCAGCTTGGGTGTTGATTCAATGCCAACAACTGATCCTTCGGATTCAGATAG CGAGATGAGCCATTCAGCAAATGACGACGACGGGTACATTGTAGCTCCTGTAGCTCGATCACGTGAAAACAATTCCATGA CGGATCATGAAGATGATACACAGGATGCTGAAGAGGATGAACATCAGTTAACACGTGTAAGAGACTGGATTAGCTCTCGC CACATTGACAATGTTGAACTGACTGATGTTCTCTCTAGCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAATCATGGA TAAACTTGTAAACCAAAACATACTGTCAAGAACAGGAAAGGATTCCTACTCCATCAGCAAGCTGAAGAAACCCAATCAGG CAATTGTTGTGAAGGAAGAGATGGATGTACAAGTAAACCAAGTTGATGAGAAAATTCAGCGAGGGAATGATGAAGACTAC TTGTACTTGAAGGCTCTGTATCATGTCCTTCCACTGGATTATGTTACAATATCTAAACTTCAAAGTAAGCTGGAAGGAGA GGCAAATCAGGCAACTGTGCGTAAACTGCTCGATAAGATGGCTTGTGATGGATATGTGGAAGCCAAGAGTAAACCAAGAT TAGGTAAACGTGTCATTCGATCTGAGTTGACTGACAAGAAGCTACTTGAGGTCAAGAATGTTTTGGAGATTAAGTTATCG ACAATGGAGATAAGTGAACCTCAAAACATATCAACCTGCGGTGGTCTCCACTCTGTTGGTTCTGATCTTACTAGAACCCG AGAAAGATCAGTTGATACTCAGCAGAATGGATCGTCTAGAATTCAGGAGCAACTTGGAAACAACACACCCATTCGCAGAA ATGAGCCTGCAGTGTCAAGGGAGAGCGGTATACCAGGGAGCGATAAGCGAAATGGTGTGGATGGGAGAGGATTCACTAAC TGTCGTGAGGGTGATGATACCTTCTGTAGTCGTCCCAGTCAGGAAAAGCGCTCCAGGAAAACTAGCACGGTGAAAGAGCC CATCCATCAAAACATGAAGCGTCAGAAATCTCAAGGTGGTGGCGCGTTGGAGTAA |