| Microexon ID | Ps_NC_039361.1:25772093-25772105:- |
| Species | Papaver somniferum | Coordinates | NC_039361.1:25772093..25772105 |
| Microexon Cluster ID | MEP32 |
| Size | 13 |
| Phase | 0 |
| Pfam Domain Motif | MCM6_C |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,13,47 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | AMYRTTGAWSTKWCWGATGTYCTYTCTARYTTCCCKGACATMTCARTGGHWCTGRYTGAAGAWATYATGGAKARRCTWSTWAAMSAWRRTRTACTRTCAARRRCRGGA |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 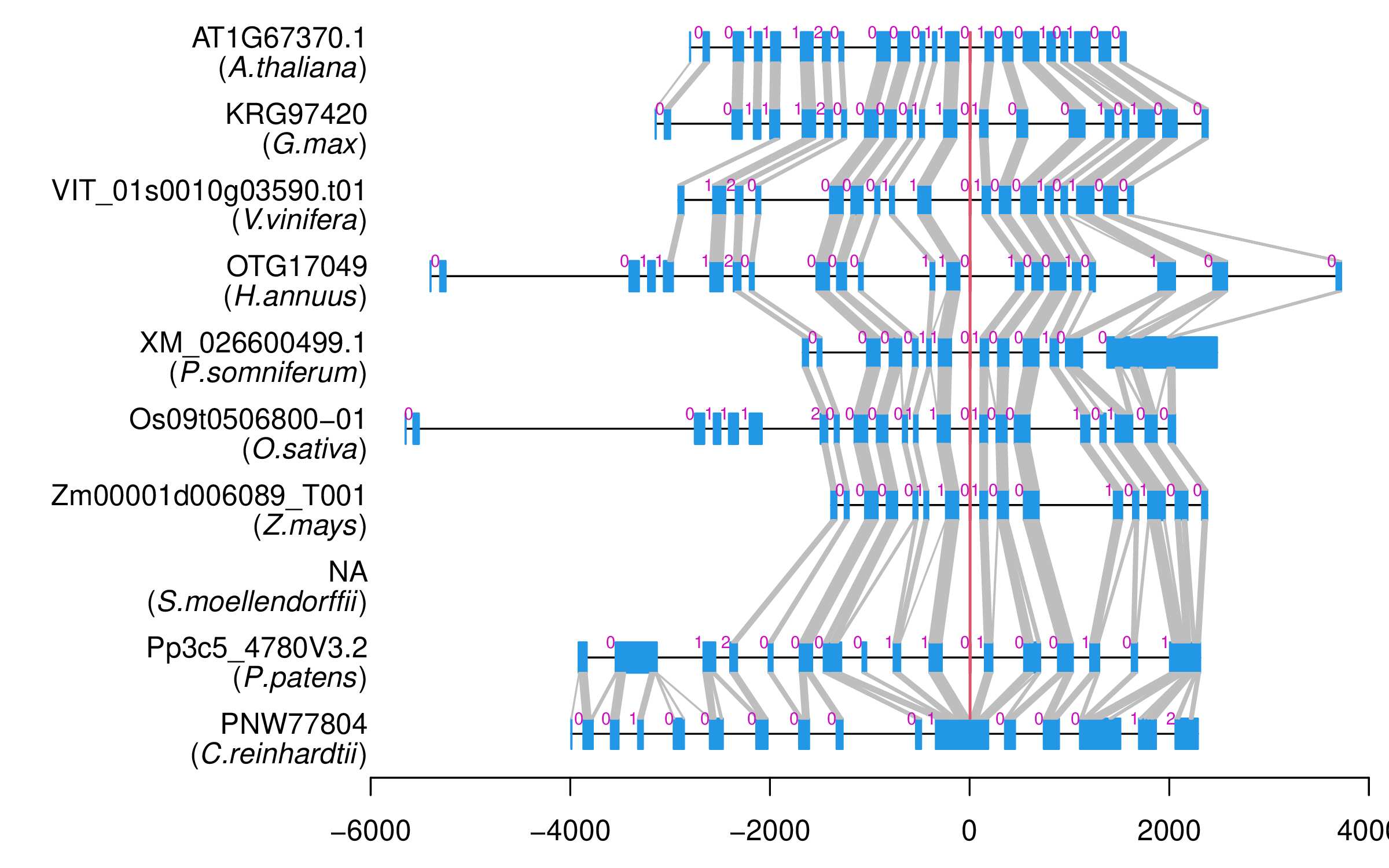 |
| Microexon DNA seq | GCTCTGACTGAAG |
| Microexon Amino Acid seq | ALTEE |
| Microexon-tag DNA Seq | AATGTTGAACTGACTGATGTTCTCTCTAGCTTCCCGGATATATCTGTGGCTCTGACTGAAGAAATCATGGATAAACTTGTAAACCAAAACATACTGTCAAGAACAGGA |
| Microexon-tag Amino Acid Seq | NVELTDVLSSFPDISVALTEEIMDKLVNQNILSRTG |
| Microexon-tag spanning region | 25771950-25772475 |
| Microexon-tag prediction score | 0.98 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026524408.1x |
| Reference Transcript ID | XM_026524408.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026524408.1 |
| Protein ID | XP_026380193.1 |
| Gene ID | LOC113274986 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026380193.1 MVVAQKLKEAEITEQDSLLLTRNLLRIAIFNISYIRGLFPENYFNDKSVPALEMKIKKLMPMDAESRRLIDWMEKGVYDA LQKKYLKTLLFCISEAIDGPMIEEYAFSFSYSNSDSEEVMMNISHTGNKKKGATFKSNGNTDITPNQMRSSACKMVRTLV QLMRTLDRMPEERTILMKLLYYEDVTPIDYEPPFFRGCSEQEANHPWLKNPLKMEIGNVNSKHFVLALKVKSILDPCQDE NSDMEDDEEISLGVDSTPTTDPSDSDSEMSHSANDDDRYIVAPLDKARSRENNCMTDHEDDTQDAEEDEHQLTRVRDWIS SRHIDNVELTDVLSSFPDISVALTEEIMDKLVNQNILSRTGKDSYSISKMKKPNQAIVVKEEMDVQVNQVDEKVQRGNDE DYLYLKSLYHVLPLDYVTISKLQSKLEGEANQATVRKLLDKMACDGYVEAKSKPRLGKRVIRSELTDKKLLEVKNVLEIK LSAMEISEPQNISTCGGLHSVGSDLTRTRERSVDTQQNGSSRIQEQLGNNTPIRRNEPAVSRESGIPGSDKRNGVDGRGF TNCPEGDDTFCSRPSQEKRSRKTSTVKEPIHQNMKRQKSQGGGALE* |
| CDS seq | >XM_026524408.1 ATGGTTGTAGCACAGAAACTCAAGGAAGCAGAAATTACAGAACAGGATTCTCTATTACTGACGAGAAACCTGCTTCGTAT TGCGATATTCAACATCAGCTACATCAGAGGGCTTTTCCCTGAAAATTACTTCAATGATAAATCAGTTCCTGCTTTAGAGA TGAAGATCAAGAAGCTCATGCCTATGGATGCTGAATCCAGAAGACTTATTGACTGGATGGAAAAAGGTGTTTATGATGCA TTACAGAAGAAATACCTTAAGACACTTCTGTTCTGCATATCTGAAGCTATTGATGGACCTATGATAGAAGAATATGCTTT TTCATTTAGCTATTCAAATTCTGACAGTGAAGAGGTGATGATGAACATAAGTCATACTGGAAATAAGAAAAAAGGAGCAA CATTCAAGTCTAATGGCAATACAGACATTACACCAAACCAAATGAGGAGTTCTGCTTGTAAAATGGTCCGAACTCTGGTT CAATTAATGCGAACACTCGACCGTATGCCAGAAGAGCGTACAATTTTGATGAAGCTTCTTTACTATGAGGATGTCACTCC TATTGACTATGAGCCTCCATTCTTCAGAGGCTGCTCAGAACAAGAAGCTAACCATCCATGGTTGAAGAACCCTCTCAAAA TGGAAATCGGAAATGTTAACAGCAAACATTTCGTATTAGCTCTCAAGGTCAAAAGCATCCTAGATCCATGTCAAGATGAA AACAGTGACATGGAAGATGATGAGGAAATCAGCTTGGGTGTTGATTCAACGCCAACAACTGATCCTTCAGATTCAGATAG CGAGATGAGCCATTCAGCAAATGACGACGACCGGTACATTGTAGCTCCTCTAGATAAAGCTCGATCACGTGAAAACAATT GCATGACGGATCATGAAGATGATACACAGGATGCAGAAGAGGATGAACATCAGTTAACACGTGTAAGAGACTGGATTAGC TCTCGCCACATTGACAATGTTGAACTGACTGATGTTCTCTCTAGCTTCCCGGATATATCTGTGGCTCTGACTGAAGAAAT CATGGATAAACTTGTAAACCAAAACATACTGTCAAGAACAGGAAAGGATTCTTACTCCATCAGCAAGATGAAGAAACCCA ATCAGGCAATTGTTGTGAAGGAAGAGATGGATGTACAAGTAAACCAAGTTGATGAGAAAGTTCAGCGAGGGAATGATGAA GACTACTTGTACTTGAAGTCTCTGTATCATGTCCTTCCACTGGATTATGTTACAATATCTAAACTTCAAAGTAAGCTGGA AGGAGAGGCAAATCAGGCAACTGTGCGTAAACTGCTCGATAAGATGGCTTGTGATGGATATGTGGAAGCCAAGAGCAAAC CAAGATTAGGTAAACGTGTCATTCGATCTGAATTGACTGACAAGAAGCTACTTGAGGTCAAGAATGTTTTGGAGATCAAG TTATCGGCAATGGAGATAAGTGAACCTCAAAACATATCAACCTGCGGTGGTCTCCACTCTGTTGGTTCGGATCTTACTAG AACTCGAGAAAGATCAGTTGATACTCAGCAGAATGGATCGTCTAGAATTCAGGAGCAACTTGGAAACAACACACCCATTC GCAGAAATGAGCCTGCAGTGTCAAGGGAGAGTGGTATACCAGGGAGCGATAAGCGAAATGGTGTGGATGGGAGAGGATTC ACTAACTGTCCTGAGGGTGATGATACCTTCTGTAGTCGTCCCAGTCAGGAAAAGCGCTCCAGGAAAACTAGCACGGTGAA AGAGCCCATCCATCAAAACATGAAGCGTCAGAAATCTCAAGGTGGTGGCGCATTGGAGTAA |
| Microexon DNA seq | GCTCTGACTGAAG |
| Microexon Amino Acid seq | ALTEE |
| Microexon-tag DNA Seq | AATGTTGAACTGACTGATGTTCTCTCTAGCTTCCCGGATATATCTGTGGCTCTGACTGAAGAAATCATGGATAAACTTGTAAACCAAAACATACTGTCAAGAACAGGA |
| Microexon-tag Amino Acid seq | NVELTDVLSSFPDISVALTEEIMDKLVNQNILSRTG |
| Transcript ID | Ps.23064.1 |
| Gene ID | Ps.23064 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >Ps.23064.1 MKIKKLMPMDAESRRLIDWMEKGVYDALQKKYLKTLLFCISEAIDGPMIEEYAFSFSYSNSDSEEVMMNISHTGNKKKGA TFKSNGNTDITPNQMRSSACKMVRTLVQLMRTLDRMPEERTILMKLLYYEDVTPIDYEPPFFRGCSEQEANHPWLKNPLK MEIGNVNSKHFVLALKVKSILDPCQDENSDMEDDEEISLGVDSTPTTDPSDSDSEMSHSANDDDRYIVAPLDKARSRENN CMTDHEDDTQDAEEDEHQLTRVRDWISSRHIDNVELTDVLSSFPDISVALTEEIMDKLVNQNILSRTGKDSYSISKMKAI VVKEEMDVQVNQVDEKVQRGNDEDYLYLKSLYHVLPLDYVTISKLQSKLEGEANQATVRKLLDKMACDGYVEAKSKPRLG KRVIRSELTDKKLLEVKNVLEIKLSAMEISEPQNISTCGGLHSVGSDLTRTRERSVDTQQNGSSRIQEQLGNNTPIRRNE PAVSRESGIPGSDKRNGVDGRGFTNCPEGDDTFCSRPSQEKRSRKTSTVKEPIHQNMKRQKSQGGGALE* |
| CDS seq | >Ps.23064.1 ATGAAGATCAAGAAGCTCATGCCTATGGATGCTGAATCCAGAAGACTTATTGACTGGATGGAAAAAGGTGTTTATGATGC ATTACAGAAGAAATACCTTAAGACACTTCTGTTCTGCATATCTGAAGCTATTGATGGACCTATGATAGAAGAATATGCTT TTTCATTTAGCTATTCAAATTCTGACAGTGAAGAGGTGATGATGAACATAAGTCATACTGGAAATAAGAAAAAAGGAGCA ACATTCAAGTCTAATGGCAATACAGACATTACACCAAACCAAATGAGGAGTTCTGCTTGTAAAATGGTCCGAACTCTGGT TCAATTAATGCGAACACTCGACCGTATGCCAGAAGAGCGTACAATTTTGATGAAGCTTCTTTACTATGAGGATGTCACTC CTATTGACTATGAGCCTCCATTCTTCAGAGGCTGCTCAGAACAAGAAGCTAACCATCCATGGTTGAAGAACCCTCTCAAA ATGGAAATCGGAAATGTTAACAGCAAACATTTCGTATTAGCTCTCAAGGTCAAAAGCATCCTAGATCCATGTCAAGATGA AAACAGTGACATGGAAGATGATGAGGAAATCAGCTTGGGTGTTGATTCAACGCCAACAACTGATCCTTCAGATTCAGATA GCGAGATGAGCCATTCAGCAAATGACGACGACCGGTACATTGTAGCTCCTCTAGATAAAGCTCGATCACGTGAAAACAAT TGCATGACGGATCATGAAGATGATACACAGGATGCAGAAGAGGATGAACATCAGTTAACACGTGTAAGAGACTGGATTAG CTCTCGCCACATTGACAATGTTGAACTGACTGATGTTCTCTCTAGCTTCCCGGATATATCTGTGGCTCTGACTGAAGAAA TCATGGATAAACTTGTAAACCAAAACATACTGTCAAGAACAGGAAAGGATTCTTACTCCATCAGCAAGATGAAGGCAATT GTTGTGAAGGAAGAGATGGATGTACAAGTAAACCAAGTTGATGAGAAAGTTCAGCGAGGGAATGATGAAGACTACTTGTA CTTGAAGTCTCTGTATCATGTCCTTCCACTGGATTATGTTACAATATCTAAACTTCAAAGTAAGCTGGAAGGAGAGGCAA ATCAGGCAACTGTGCGTAAACTGCTCGATAAGATGGCTTGTGATGGATATGTGGAAGCCAAGAGCAAACCAAGATTAGGT AAACGTGTCATTCGATCTGAATTGACTGACAAGAAGCTACTTGAGGTCAAGAATGTTTTGGAGATCAAGTTATCGGCAAT GGAGATAAGTGAACCTCAAAACATATCAACCTGCGGTGGTCTCCACTCTGTTGGTTCGGATCTTACTAGAACTCGAGAAA GATCAGTTGATACTCAGCAGAATGGATCGTCTAGAATTCAGGAGCAACTTGGAAACAACACACCCATTCGCAGAAATGAG CCTGCAGTGTCAAGGGAGAGTGGTATACCAGGGAGCGATAAGCGAAATGGTGTGGATGGGAGAGGATTCACTAACTGTCC TGAGGGTGATGATACCTTCTGTAGTCGTCCCAGTCAGGAAAAGCGCTCCAGGAAAACTAGCACGGTGAAAGAGCCCATCC ATCAAAACATGAAGCGTCAGAAATCTCAAGGTGGTGGCGCATTGGAGTAA |