| Microexon ID | Ps_NC_039361.1:23406438-23406450:- |
| Species | Papaver somniferum | Coordinates | NC_039361.1:23406438..23406450 |
| Microexon Cluster ID | MEP32 |
| Size | 13 |
| Phase | 0 |
| Pfam Domain Motif | MCM6_C |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,13,47 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | AMYRTTGAWSTKWCWGATGTYCTYTCTARYTTCCCKGACATMTCARTGGHWCTGRYTGAAGAWATYATGGAKARRCTWSTWAAMSAWRRTRTACTRTCAARRRCRGGA |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 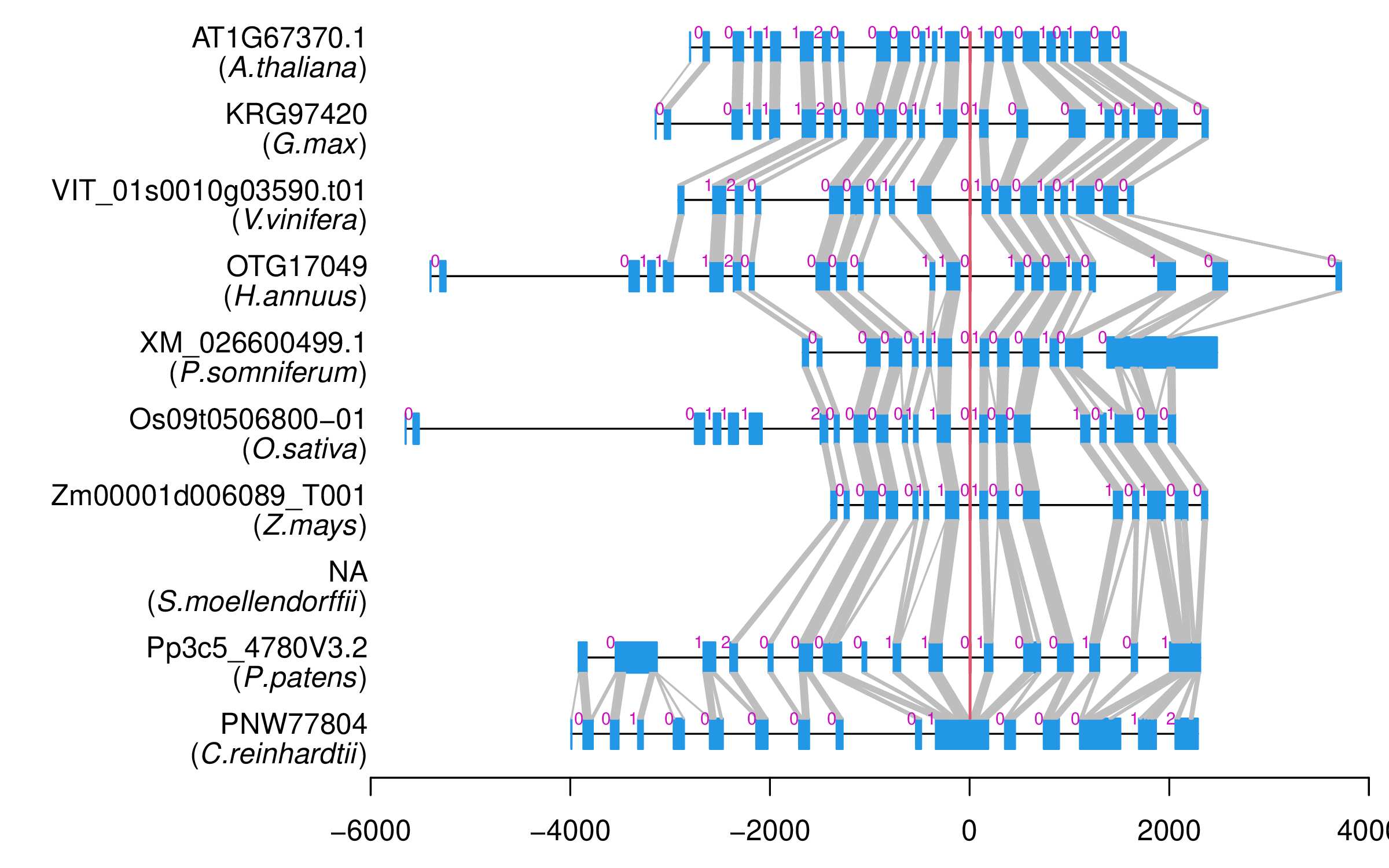 |
| Microexon DNA seq | GCTCTGACTGAAG |
| Microexon Amino Acid seq | ALTEE |
| Microexon-tag DNA Seq | AATGTTGAACTGACTGATGTTCTCTCTAGCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAATCATGGATAAACTTGTAAACCAAAATATACTGTCAAGAACTGGA |
| Microexon-tag Amino Acid Seq | NVELTDVLSSFPDISVALTEEIMDKLVNQNILSRTG |
| Microexon-tag spanning region | 23406295-23406605 |
| Microexon-tag prediction score | 0.9891 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026524361.1x |
| Reference Transcript ID | XM_026524361.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026524361.1 |
| Protein ID | XP_026380146.1 |
| Gene ID | LOC113274940 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026380146.1 MVVAQKLKEAEITEQDSLLLTRNLLRIAIFNISYIRGLFPENYFNDKLVPALEMKIKKLMPIDAESRRLIDWMEKGVYDA LQKKYLKTLLFCISEAIDGSMIEEYAFSFSYSTSDSEEVMMNISRTGNKKQGATFKSNGNTDITPNQMRSSACKMVRTLV QLMRTLDRMPEERTILMKLLYYEDVTPIDYEPPFFRGCSEQEANHPWLKNPLKMEIGNVNSKHFVLALKVKSILDPCQDE NNDMEDDEEISLGVGSTPTTDPSDSDSEMSHSANDDDGYIVAPVDKARSRENNGMTDHEDDTQDAEEDEHQLTRVRDWIS SRHIDNVELTDVLSSFPDISVALTEEIMDKLVNQNILSRTGKDSYSISKLKKPYQAIVVKEEMDVQVNQVDEEVQRGNDE DYLYLKALYHVLPLDYVTISKLQSKMEGDANQATVRKLLDRMACDGYVDAKSKPTLGKRVIRSELTDKKLLEVKNVLEIK LSAMEISEPQNISTCGGLHSVGSDITRTRERSVDTQQNGSSRIQEQLGNNTPIRRNEPAVSRESGIPGSGKRNGVDGRGF TNCREGDDTFCSRPSQEKRCRKTSTVKEPIHQNMKRQKSQGGGASE* |
| CDS seq | >XM_026524361.1 ATGGTTGTAGCACAGAAACTCAAGGAAGCAGAAATTACAGAACAAGATTCTCTATTACTGACGAGAAACCTGCTTCGTAT TGCAATATTCAACATCAGCTACATCAGAGGGCTTTTCCCTGAAAATTACTTCAATGACAAATTAGTTCCTGCTTTAGAGA TGAAGATCAAGAAGCTCATGCCTATAGATGCTGAATCCAGAAGACTTATTGACTGGATGGAAAAAGGTGTTTATGATGCA TTACAGAAGAAGTACCTTAAGACACTTCTGTTCTGCATATCTGAAGCTATCGATGGATCTATGATAGAAGAATATGCTTT TTCATTTAGCTATTCGACTTCTGACAGTGAAGAGGTGATGATGAACATAAGTCGTACTGGAAATAAGAAACAAGGAGCAA CATTCAAGTCTAATGGCAATACAGACATTACACCAAACCAGATGAGGAGTTCTGCTTGTAAAATGGTCCGAACTCTGGTT CAATTGATGCGAACGCTGGACCGTATGCCAGAAGAGCGTACAATCTTGATGAAGCTTCTTTATTATGAGGATGTGACTCC TATAGACTATGAGCCTCCATTCTTCAGAGGCTGCTCAGAACAAGAAGCTAACCATCCATGGTTGAAGAACCCTCTCAAAA TGGAAATCGGAAATGTTAATAGCAAACATTTCGTACTAGCTCTCAAGGTCAAAAGCATTCTGGATCCATGTCAAGATGAA AACAATGACATGGAAGATGATGAGGAAATCAGCTTGGGTGTTGGTTCAACACCAACAACTGATCCTTCAGATTCAGATAG CGAGATGAGCCATTCAGCAAATGATGACGATGGGTACATTGTAGCTCCTGTAGATAAAGCCCGATCACGTGAAAACAATG GCATGACGGATCACGAAGATGATACACAGGATGCGGAAGAGGACGAGCATCAGTTAACACGTGTAAGAGACTGGATTAGC TCTCGCCACATTGACAATGTTGAACTGACTGATGTTCTCTCTAGCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAAT CATGGATAAACTTGTAAACCAAAATATACTGTCAAGAACTGGAAAGGATTCTTACTCCATCAGCAAGCTGAAGAAACCCT ATCAGGCAATTGTCGTGAAGGAAGAGATGGATGTACAAGTGAACCAAGTTGATGAGGAAGTTCAGCGAGGGAATGATGAG GACTACTTGTACTTGAAGGCTCTGTATCATGTCCTTCCTCTAGATTATGTCACAATATCTAAACTTCAAAGTAAGATGGA AGGAGACGCAAATCAGGCAACTGTGCGTAAACTGCTCGATAGGATGGCTTGTGATGGATATGTGGATGCCAAGAGCAAAC CAACATTAGGTAAACGTGTCATTCGATCTGAACTGACTGACAAGAAGCTACTTGAGGTCAAGAATGTTTTGGAGATCAAG TTATCGGCAATGGAGATAAGTGAACCTCAAAACATATCAACCTGCGGTGGTCTCCACTCTGTTGGTTCTGATATTACTAG AACTCGAGAAAGATCAGTTGACACTCAGCAGAATGGGTCGTCTAGAATTCAGGAGCAACTTGGAAACAACACACCCATTC GCAGAAATGAGCCTGCCGTGTCAAGGGAGAGTGGTATACCAGGGAGCGGTAAGCGAAATGGTGTGGACGGGAGAGGATTC ACTAACTGTCGTGAGGGTGATGATACCTTCTGTAGTCGTCCCAGTCAGGAAAAGCGCTGCAGGAAAACTAGCACGGTGAA AGAGCCCATCCATCAAAACATGAAGCGTCAGAAATCTCAAGGTGGTGGCGCATCGGAGTAA |
| Microexon DNA seq | GCTCTGACTGAAG |
| Microexon Amino Acid seq | ALTEE |
| Microexon-tag DNA Seq | AATGTTGAACTGACTGATGTTCTCTCTAGCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAATCATGGATAAACTTGTAAACCAAAATATACTGTCAAGAACTGGA |
| Microexon-tag Amino Acid seq | NVELTDVLSSFPDISVALTEEIMDKLVNQNILSRTG |
| Transcript ID | XM_026524361.1 |
| Gene ID | Ps.22984 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026524361.1 MVVAQKLKEAEITEQDSLLLTRNLLRIAIFNISYIRGLFPENYFNDKLVPALEMKIKKLMPIDAESRRLIDWMEKGVYDA LQKKYLKTLLFCISEAIDGSMIEEYAFSFSYSTSDSEEVMMNISRTGNKKQGATFKSNGNTDITPNQMRSSACKMVRTLV QLMRTLDRMPEERTILMKLLYYEDVTPIDYEPPFFRGCSEQEANHPWLKNPLKMEIGNVNSKHFVLALKVKSILDPCQDE NNDMEDDEEISLGVGSTPTTDPSDSDSEMSHSANDDDGYIVAPVDKARSRENNGMTDHEDDTQDAEEDEHQLTRVRDWIS SRHIDNVELTDVLSSFPDISVALTEEIMDKLVNQNILSRTGKDSYSISKLKKPYQAIVVKEEMDVQVNQVDEEVQRGNDE DYLYLKALYHVLPLDYVTISKLQSKMEGDANQATVRKLLDRMACDGYVDAKSKPTLGKRVIRSELTDKKLLEVKNVLEIK LSAMEISEPQNISTCGGLHSVGSDITRTRERSVDTQQNGSSRIQEQLGNNTPIRRNEPAVSRESGIPGSGKRNGVDGRGF TNCREGDDTFCSRPSQEKRCRKTSTVKEPIHQNMKRQKSQGGGASE* |
| CDS seq | >XM_026524361.1 ATGGTTGTAGCACAGAAACTCAAGGAAGCAGAAATTACAGAACAAGATTCTCTATTACTGACGAGAAACCTGCTTCGTAT TGCAATATTCAACATCAGCTACATCAGAGGGCTTTTCCCTGAAAATTACTTCAATGACAAATTAGTTCCTGCTTTAGAGA TGAAGATCAAGAAGCTCATGCCTATAGATGCTGAATCCAGAAGACTTATTGACTGGATGGAAAAAGGTGTTTATGATGCA TTACAGAAGAAGTACCTTAAGACACTTCTGTTCTGCATATCTGAAGCTATCGATGGATCTATGATAGAAGAATATGCTTT TTCATTTAGCTATTCGACTTCTGACAGTGAAGAGGTGATGATGAACATAAGTCGTACTGGAAATAAGAAACAAGGAGCAA CATTCAAGTCTAATGGCAATACAGACATTACACCAAACCAGATGAGGAGTTCTGCTTGTAAAATGGTCCGAACTCTGGTT CAATTGATGCGAACGCTGGACCGTATGCCAGAAGAGCGTACAATCTTGATGAAGCTTCTTTATTATGAGGATGTGACTCC TATAGACTATGAGCCTCCATTCTTCAGAGGCTGCTCAGAACAAGAAGCTAACCATCCATGGTTGAAGAACCCTCTCAAAA TGGAAATCGGAAATGTTAATAGCAAACATTTCGTACTAGCTCTCAAGGTCAAAAGCATTCTGGATCCATGTCAAGATGAA AACAATGACATGGAAGATGATGAGGAAATCAGCTTGGGTGTTGGTTCAACACCAACAACTGATCCTTCAGATTCAGATAG CGAGATGAGCCATTCAGCAAATGATGACGATGGGTACATTGTAGCTCCTGTAGATAAAGCCCGATCACGTGAAAACAATG GCATGACGGATCACGAAGATGATACACAGGATGCGGAAGAGGACGAGCATCAGTTAACACGTGTAAGAGACTGGATTAGC TCTCGCCACATTGACAATGTTGAACTGACTGATGTTCTCTCTAGCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAAT CATGGATAAACTTGTAAACCAAAATATACTGTCAAGAACTGGAAAGGATTCTTACTCCATCAGCAAGCTGAAGAAACCCT ATCAGGCAATTGTCGTGAAGGAAGAGATGGATGTACAAGTGAACCAAGTTGATGAGGAAGTTCAGCGAGGGAATGATGAG GACTACTTGTACTTGAAGGCTCTGTATCATGTCCTTCCTCTAGATTATGTCACAATATCTAAACTTCAAAGTAAGATGGA AGGAGACGCAAATCAGGCAACTGTGCGTAAACTGCTCGATAGGATGGCTTGTGATGGATATGTGGATGCCAAGAGCAAAC CAACATTAGGTAAACGTGTCATTCGATCTGAACTGACTGACAAGAAGCTACTTGAGGTCAAGAATGTTTTGGAGATCAAG TTATCGGCAATGGAGATAAGTGAACCTCAAAACATATCAACCTGCGGTGGTCTCCACTCTGTTGGTTCTGATATTACTAG AACTCGAGAAAGATCAGTTGACACTCAGCAGAATGGGTCGTCTAGAATTCAGGAGCAACTTGGAAACAACACACCCATTC GCAGAAATGAGCCTGCCGTGTCAAGGGAGAGTGGTATACCAGGGAGCGGTAAGCGAAATGGTGTGGACGGGAGAGGATTC ACTAACTGTCGTGAGGGTGATGATACCTTCTGTAGTCGTCCCAGTCAGGAAAAGCGCTGCAGGAAAACTAGCACGGTGAA AGAGCCCATCCATCAAAACATGAAGCGTCAGAAATCTCAAGGTGGTGGCGCATCGGAGTAA |