| Microexon ID | Ps_NC_039360.1:120730963-120730975:- |
| Species | Papaver somniferum | Coordinates | NC_039360.1:120730963..120730975 |
| Microexon Cluster ID | MEP32 |
| Size | 13 |
| Phase | 0 |
| Pfam Domain Motif | MCM6_C |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,13,47 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | AMYRTTGAWSTKWCWGATGTYCTYTCTARYTTCCCKGACATMTCARTGGHWCTGRYTGAAGAWATYATGGAKARRCTWSTWAAMSAWRRTRTACTRTCAARRRCRGGA |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 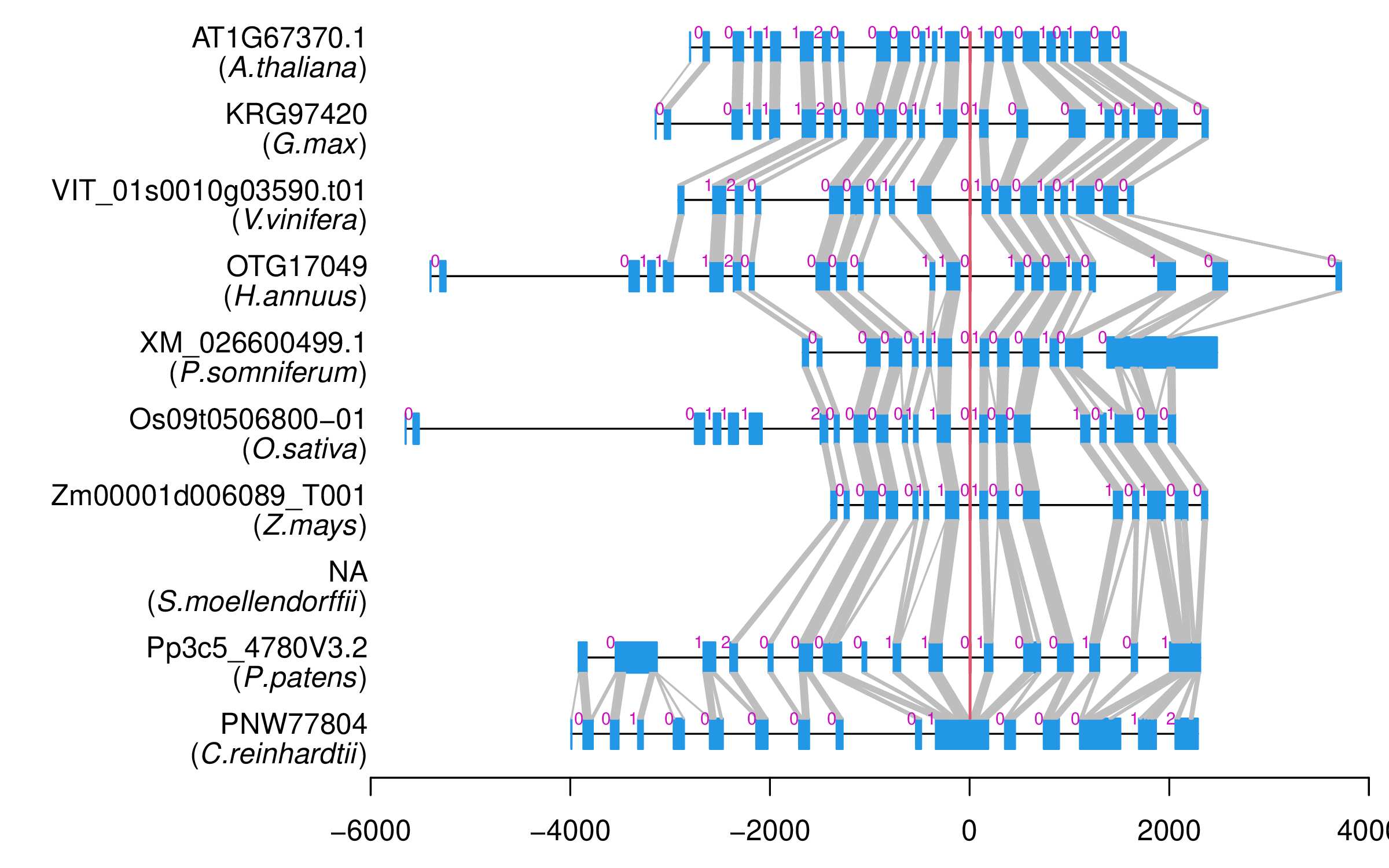 |
| Microexon DNA seq | GCTCTGACTGAAG |
| Microexon Amino Acid seq | ALTEE |
| Microexon-tag DNA Seq | AATGTTGAACTGACTGATGTTTTCTCTAGCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAAGCATGGATAAACTTGTATACCAAAATATACTGTCAAGAACAGGA |
| Microexon-tag Amino Acid Seq | NVELTDVFSSFPDISVALTEESMDKLVYQNILSRTG |
| Microexon-tag spanning region | 120730818-120731206 |
| Microexon-tag prediction score | 0.9722 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026600499.1x |
| Reference Transcript ID | XM_026600499.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026600499.1 |
| Protein ID | XP_026456284.1 |
| Gene ID | LOC113357179 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026456284.1 MVRTLVQLMRTLDRMPEERTILMKLLLYEDVTPIDYKSPFFIGCSEQEANNPWLKNPLKMEIGNVNSKHFVLALKVKSIL DPCQDENNDMKADEVIRLGVDSTPTTDPLDSDSEMSHSANDDDGYIVASVARSLENNGMADHEDDTRDAEEDEHQLKHVR DWISSHHIDNVELTDVFSSFPDISVALTEESMDKLVYQNILSRTGKDSYSIGKLKKSNQAIVLKEEMDVQVNQVDEKVQQ GNDEDYLYLKALYHVLPLDYVTVSKLQSKLEGEVNQATVHKMFDKMACDGYVEAKSKPRLGKHVIRSELTDKKLLEVKNV LEIKLSAIDTSEPQNVSTCGGLHSVGSDLTRTRERSAETHQMGSSRIQELLGNNTSIRRNEGFLIYVNFLCNKTLVLEVL SSESVHTVKAKIHFKEGIPPSQQCLFFRSKELTDGTLAEYCITKASTLHILLCLRGGGSRKKEQKKARKRTYGKQEEQEK AERITQEQAQKADKKDKKDKKKKQHEENKIMQEKNDIVLSIWRAHWDAKYESDERFLDEESLDVKREIQLQETEEITNNI MAEEIMVLSIWETRWDTAYDSDKKFLEEESLNEGKRQQEETEEINSKMMPEENKIGLSNCEDLWDVKYDTDDSDEKFMEE ASFDGIDKQLMSMDLNSMSALEVFDWIREWDNKYVDEVLEEESLDENSSGGISVRFRWTPSQEYVRIAGVGGGSRGAYGQ VIARHAKNNSSNDMPELLPLWKVLHSG* |
| CDS seq | >XM_026600499.1 ATGGTCCGAACTCTGGTTCAATTGATGCGAACACTGGACCGTATGCCAGAAGAGCGTACCATCTTGATGAAGCTTCTTTT GTATGAGGATGTCACTCCTATAGACTATAAGTCTCCATTCTTCATAGGCTGCTCAGAACAAGAAGCTAACAATCCATGGT TGAAGAACCCTCTCAAAATGGAAATCGGAAATGTTAACAGCAAACATTTCGTACTAGCTCTCAAGGTCAAAAGCATCCTG GATCCATGTCAAGATGAAAACAATGACATGAAAGCTGATGAGGTAATCAGATTGGGTGTTGATTCAACGCCAACAACTGA TCCTTTAGATTCAGATAGCGAGATGAGCCATTCAGCAAATGATGACGACGGGTACATTGTAGCTTCTGTAGCCCGATCAC TTGAAAACAATGGCATGGCGGATCATGAAGATGATACACGGGATGCAGAAGAGGACGAACATCAGCTAAAACATGTAAGA GACTGGATTAGCTCTCACCACATTGACAATGTTGAACTGACTGATGTTTTCTCTAGCTTCCCGGACATATCAGTGGCTCT GACTGAAGAAAGCATGGATAAACTTGTATACCAAAATATACTGTCAAGAACAGGAAAGGATTCTTACTCCATCGGCAAGC TGAAGAAATCCAATCAGGCAATTGTCTTGAAGGAAGAGATGGATGTACAAGTAAACCAAGTTGATGAGAAAGTTCAGCAA GGGAATGATGAAGACTACTTGTACTTGAAGGCTCTGTATCATGTCCTTCCACTGGATTATGTTACAGTATCTAAACTTCA AAGTAAGCTGGAAGGAGAGGTAAATCAGGCAACTGTGCATAAAATGTTCGATAAGATGGCTTGTGATGGGTATGTGGAAG CCAAGAGCAAACCAAGATTAGGTAAACATGTCATTCGATCTGAATTGACTGACAAGAAGCTACTTGAGGTCAAGAATGTT TTGGAGATCAAGTTATCGGCAATAGATACAAGTGAACCTCAAAACGTATCAACCTGCGGTGGTCTCCACTCTGTTGGTTC TGATCTTACTAGAACTCGTGAAAGATCAGCCGAAACTCATCAGATGGGATCATCTAGAATTCAGGAGCTGCTTGGAAACA ACACATCCATCCGCAGAAATGAGGGTTTTCTTATCTATGTTAATTTCCTCTGTAATAAGACCTTGGTCCTTGAGGTTCTG AGCTCAGAATCCGTTCATACCGTGAAAGCCAAGATTCACTTCAAGGAAGGGATCCCTCCATCACAACAGTGCTTGTTTTT TCGCAGTAAAGAATTGACAGATGGAACGCTCGCTGAATACTGTATAACCAAAGCCTCGACTCTTCATATTCTCCTTTGCC TTCGTGGAGGAGGTAGTCGAAAGAAAGAACAGAAAAAGGCACGAAAGAGAACATATGGAAAACAGGAGGAGCAAGAAAAG GCTGAGAGGATAACACAGGAGCAGGCCCAAAAAGCAGACAAAAAAGATAAAAAAGACAAAAAGAAAAAACAGCATGAGGA GAATAAGATAATGCAGGAGAAGAATGATATCGTTCTGTCTATCTGGAGAGCTCACTGGGATGCGAAATATGAATCTGACG AGAGGTTTCTGGATGAGGAATCTTTGGATGTTAAAAGGGAAATACAACTGCAGGAGACTGAAGAAATTACGAATAATATA ATGGCGGAGGAGATAATGGTTCTGTCTATCTGGGAAACTCGCTGGGATACCGCATATGATTCAGACAAGAAGTTTCTGGA GGAGGAGTCTCTGAATGAAGGAAAAAGACAGCAGGAGGAGACTGAAGAAATCAATAGTAAGATGATGCCGGAGGAGAATA AGATAGGTCTGTCAAACTGTGAAGATCTATGGGATGTTAAGTATGATACTGATGATTCTGACGAGAAGTTTATGGAGGAG GCATCTTTTGATGGGATAGATAAACAATTAATGTCGATGGATCTTAACTCAATGTCAGCGTTGGAAGTGTTTGATTGGAT ACGTGAATGGGATAACAAATATGTTGACGAAGTTCTTGAGGAAGAATCTCTGGATGAAAACAGCAGCGGAGGAATTAGTG TCAGATTTCGATGGACCCCTTCACAGGAGTATGTTAGAATTGCAGGTGTTGGAGGAGGCTCGCGAGGAGCTTATGGGCAG GTCATTGCACGTCATGCCAAAAATAACAGCAGCAACGATATGCCAGAATTGCTGCCACTATGGAAGGTATTGCATAGTGG TTAA |
| Microexon DNA seq | GCTCTGACTGAAG |
| Microexon Amino Acid seq | ALTEE |
| Microexon-tag DNA Seq | AATGTTGAACTGACTGATGTTTTCTCTAGCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAAGCATGGATAAACTTGTATACCAAAATATACTGTCAAGAACAGGA |
| Microexon-tag Amino Acid seq | NVELTDVFSSFPDISVALTEESMDKLVYQNILSRTG |
| Transcript ID | XM_026600503.1 |
| Gene ID | LOC113357179 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026600503.1 MFYQMSHSANDDDGYIVASVDDTRDAEEDEHQLKHVRDWISSHHIDNVELTDVFSSFPDISVALTEESMDKLVYQNILSR TGKDSYSIGKLKKSNQAIVLKEEMDVQVNQVDEKVQQGNDEDYLYLKALYHVLPLDYVTVSKLQSKLEGEVNQATVHKMF DKMACDGYVEAKSKPRLGKHVIRSELTDKKLLEVKNVLEIKLSAIDTSEPQNVSTCGGLHSVGSDLTRTRERSAETHQMG SSRIQELLGNNTSIRRNEGFLIYVNFLCNKTLVLEVLSSESVHTVKAKIHFKEGIPPSQQCLFFRSKELTDGTLAEYCIT KASTLHILLCLRGGGSRKKEQKKARKRTYGKQEEQEKAERITQEQAQKADKKDKKDKKKKQHEENKIMQEKNDIVLSIWR AHWDAKYESDERFLDEESLDVKREIQLQETEEITNNIMAEEIMVLSIWETRWDTAYDSDKKFLEEESLNEGKRQQEETEE INSKMMPEENKIGLSNCEDLWDVKYDTDDSDEKFMEEASFDGIDKQLMSMDLNSMSALEVFDWIREWDNKYVDEVLEEES LDENSSGGISVRFRWTPSQEYVRIAGVGGGSRGAYGQVIARHAKNNSSNDMPELLPLWKVLHSG* |
| CDS seq | >XM_026600503.1 ATGTTTTATCAGATGAGCCATTCAGCAAATGATGACGACGGGTACATTGTAGCTTCTGTAGATGATACACGGGATGCAGA AGAGGACGAACATCAGCTAAAACATGTAAGAGACTGGATTAGCTCTCACCACATTGACAATGTTGAACTGACTGATGTTT TCTCTAGCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAAGCATGGATAAACTTGTATACCAAAATATACTGTCAAGA ACAGGAAAGGATTCTTACTCCATCGGCAAGCTGAAGAAATCCAATCAGGCAATTGTCTTGAAGGAAGAGATGGATGTACA AGTAAACCAAGTTGATGAGAAAGTTCAGCAAGGGAATGATGAAGACTACTTGTACTTGAAGGCTCTGTATCATGTCCTTC CACTGGATTATGTTACAGTATCTAAACTTCAAAGTAAGCTGGAAGGAGAGGTAAATCAGGCAACTGTGCATAAAATGTTC GATAAGATGGCTTGTGATGGGTATGTGGAAGCCAAGAGCAAACCAAGATTAGGTAAACATGTCATTCGATCTGAATTGAC TGACAAGAAGCTACTTGAGGTCAAGAATGTTTTGGAGATCAAGTTATCGGCAATAGATACAAGTGAACCTCAAAACGTAT CAACCTGCGGTGGTCTCCACTCTGTTGGTTCTGATCTTACTAGAACTCGTGAAAGATCAGCCGAAACTCATCAGATGGGA TCATCTAGAATTCAGGAGCTGCTTGGAAACAACACATCCATCCGCAGAAATGAGGGTTTTCTTATCTATGTTAATTTCCT CTGTAATAAGACCTTGGTCCTTGAGGTTCTGAGCTCAGAATCCGTTCATACCGTGAAAGCCAAGATTCACTTCAAGGAAG GGATCCCTCCATCACAACAGTGCTTGTTTTTTCGCAGTAAAGAATTGACAGATGGAACGCTCGCTGAATACTGTATAACC AAAGCCTCGACTCTTCATATTCTCCTTTGCCTTCGTGGAGGAGGTAGTCGAAAGAAAGAACAGAAAAAGGCACGAAAGAG AACATATGGAAAACAGGAGGAGCAAGAAAAGGCTGAGAGGATAACACAGGAGCAGGCCCAAAAAGCAGACAAAAAAGATA AAAAAGACAAAAAGAAAAAACAGCATGAGGAGAATAAGATAATGCAGGAGAAGAATGATATCGTTCTGTCTATCTGGAGA GCTCACTGGGATGCGAAATATGAATCTGACGAGAGGTTTCTGGATGAGGAATCTTTGGATGTTAAAAGGGAAATACAACT GCAGGAGACTGAAGAAATTACGAATAATATAATGGCGGAGGAGATAATGGTTCTGTCTATCTGGGAAACTCGCTGGGATA CCGCATATGATTCAGACAAGAAGTTTCTGGAGGAGGAGTCTCTGAATGAAGGAAAAAGACAGCAGGAGGAGACTGAAGAA ATCAATAGTAAGATGATGCCGGAGGAGAATAAGATAGGTCTGTCAAACTGTGAAGATCTATGGGATGTTAAGTATGATAC TGATGATTCTGACGAGAAGTTTATGGAGGAGGCATCTTTTGATGGGATAGATAAACAATTAATGTCGATGGATCTTAACT CAATGTCAGCGTTGGAAGTGTTTGATTGGATACGTGAATGGGATAACAAATATGTTGACGAAGTTCTTGAGGAAGAATCT CTGGATGAAAACAGCAGCGGAGGAATTAGTGTCAGATTTCGATGGACCCCTTCACAGGAGTATGTTAGAATTGCAGGTGT TGGAGGAGGCTCGCGAGGAGCTTATGGGCAGGTCATTGCACGTCATGCCAAAAATAACAGCAGCAACGATATGCCAGAAT TGCTGCCACTATGGAAGGTATTGCATAGTGGTTAA |