| Microexon ID | Ps_NC_039359.1:89331639-89331651:- |
| Species | Papaver somniferum | Coordinates | NC_039359.1:89331639..89331651 |
| Microexon Cluster ID | MEP32 |
| Size | 13 |
| Phase | 0 |
| Pfam Domain Motif | MCM6_C |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 48,13,47 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | AMYRTTGAWSTKWCWGATGTYCTYTCTARYTTCCCKGACATMTCARTGGHWCTGRYTGAAGAWATYATGGAKARRCTWSTWAAMSAWRRTRTACTRTCAARRRCRGGA |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 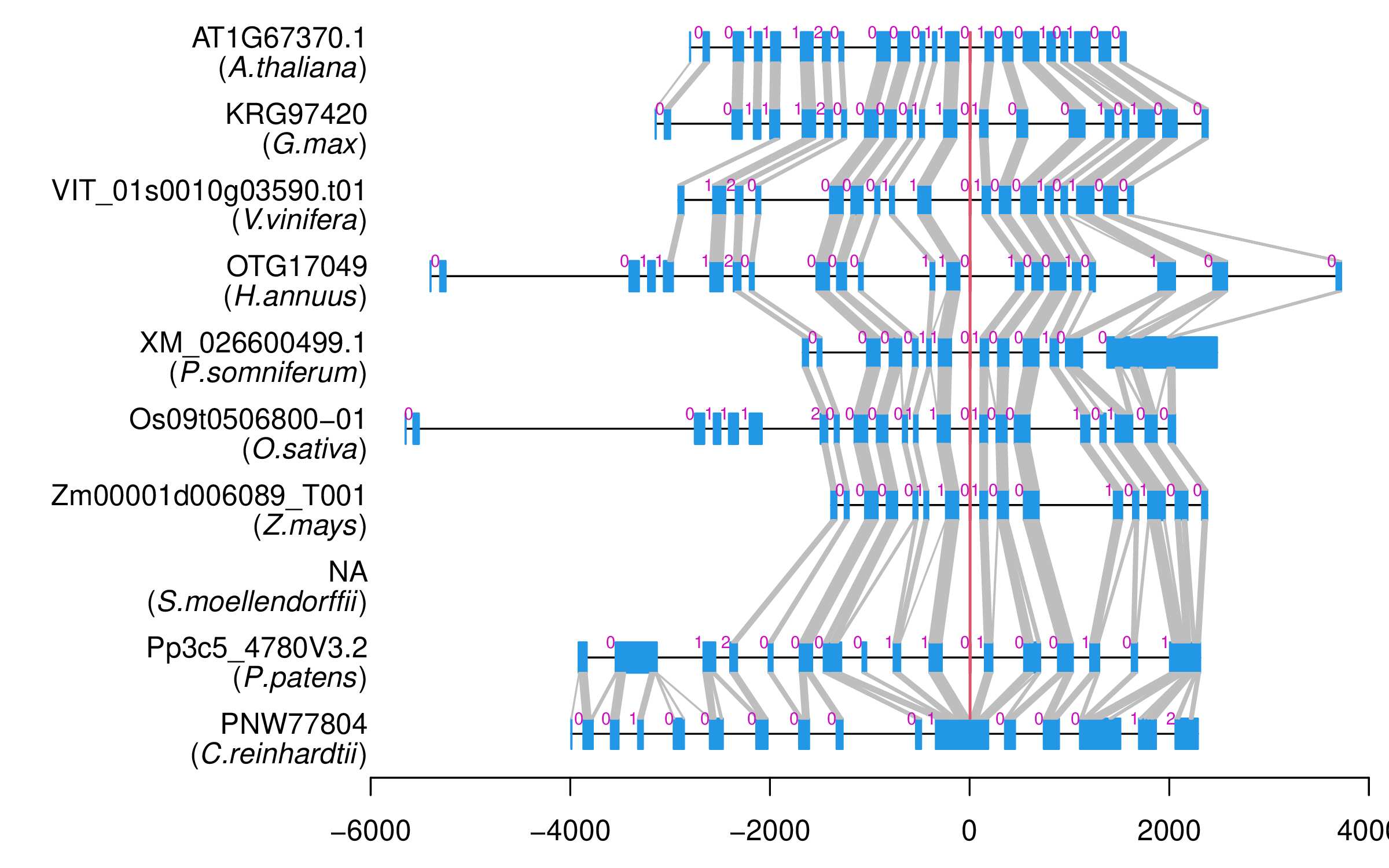 |
| Microexon DNA seq | GCTCTGACTGAAG |
| Microexon Amino Acid seq | ALTEE |
| Microexon-tag DNA Seq | AATGTTGAACTGACTGATGTTCTCTCTATCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAATCATGGATAAACTTGTAAACCAAAATATACTGTCAAGAACGGGA |
| Microexon-tag Amino Acid Seq | NVELTDVLSIFPDISVALTEEIMDKLVNQNILSRTG |
| Microexon-tag spanning region | 89331515-89332023 |
| Microexon-tag prediction score | 0.9853 |
| Overlapped with the annotated transcript (%) | NA |
| New Transcript ID | NA |
| Reference Transcript ID | NA |
| Gene ID | NA |
| Gene Name | NA |
Ps_NC_039359.1:89331639-89331651:- does not have available information here.
| Microexon DNA seq | GCTCTGACTGAAG |
| Microexon Amino Acid seq | ALTEE |
| Microexon-tag DNA Seq | AATGTTGAACTGACTGATGTTCTCTCTATCTTCCCGGACATATCAGTGGCTCTGACTGAAGAAATCATGGATAAACTTGTAAACCAAAATATACTGTCAAGAACGGGA |
| Microexon-tag Amino Acid seq | NVELTDVLSIFPDISVALTEEIMDKLVNQNILSRTG |
| Transcript ID | Ps.11281.1 |
| Gene ID | Ps.11281 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >Ps.11281.1 MEKGVYDALQKKYLKMLLFCISEAIDGPMVEEYAFSFSYSNSDSEEVMMNISRTGNKKQGATFKSNGNTDITPNQMRSSG CKMVRTLVQLMRTLDRKPEERTILMMLLYYEDVTPIDYEPPFFRGCSEQEANRPWLKNPLKMEIGNVNSKHFVLALKVKS ILDPCQDENNDMEDDEEISLGVDSTPTTDPSDSDSEMSHSANDDDRYIVAPVDKARSRGNNGMADHEDDTQDAEEDEHLL TRVRDWISSRHIDNVELTDVLSIFPDISVALTEEIMDKLVNQNILSRTGKDSYSISKLKAIVVKEKMDVQAN* |
| CDS seq | >Ps.11281.1 ATGGAAAAAGGAGTTTATGATGCATTACAGAAGAAATACCTTAAGATGCTTCTGTTCTGCATATCTGAAGCTATTGATGG ACCTATGGTAGAAGAATATGCTTTTTCATTTAGCTATTCGAATTCTGACAGTGAAGAGGTGATGATGAACATAAGTCGTA CTGGAAATAAGAAACAAGGAGCAACATTCAAGTCTAATGGCAATACAGACATTACACCAAACCAAATGAGGAGTTCTGGT TGTAAAATGGTCCGAACTCTGGTTCAATTGATGCGAACACTGGACCGTAAGCCAGAAGAGCGTACAATCTTGATGATGCT TCTTTATTACGAGGATGTCACTCCTATAGACTATGAGCCTCCATTCTTCAGAGGCTGCTCAGAACAAGAAGCTAACCGTC CATGGTTGAAGAACCCTCTCAAAATGGAAATCGGAAATGTTAACAGCAAGCATTTCGTACTAGCTCTCAAGGTCAAAAGC ATCCTGGATCCTTGTCAAGATGAGAACAATGACATGGAAGATGATGAGGAAATCAGCTTGGGTGTTGATTCAACGCCAAC AACTGATCCTTCAGATTCAGATAGTGAGATGAGCCATTCAGCAAATGATGATGATAGGTACATTGTAGCTCCCGTGGATA AAGCCCGATCACGTGGAAACAATGGCATGGCGGATCATGAAGATGATACACAGGATGCAGAAGAGGACGAACATCTGTTA ACACGTGTAAGAGACTGGATTAGCTCTCGCCACATTGACAATGTTGAACTGACTGATGTTCTCTCTATCTTCCCGGACAT ATCAGTGGCTCTGACTGAAGAAATCATGGATAAACTTGTAAACCAAAATATACTGTCAAGAACGGGAAAGGATTCTTACT CCATCAGCAAGCTGAAGGCAATTGTTGTGAAGGAAAAGATGGATGTACAAGCAAACTAA |