| Microexon ID | Gm_15:8411688-8411699:- |
| Species | Glycine max | Coordinates | 15:8411688..8411699 |
| Microexon Cluster ID | MEP30 |
| Size | 12 |
| Phase | 1 |
| Pfam Domain Motif | SPARK |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 49,12,47 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | RATGTYTAYRRYCTTTGTCATATAASCCTSAARGAYTTYTCYCTYCAAGTTGGAWMWCAAGARTCTGGWTGYCTWYTDCCAAGYTTGCCTTCAGATGCAAYATTTGAY |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 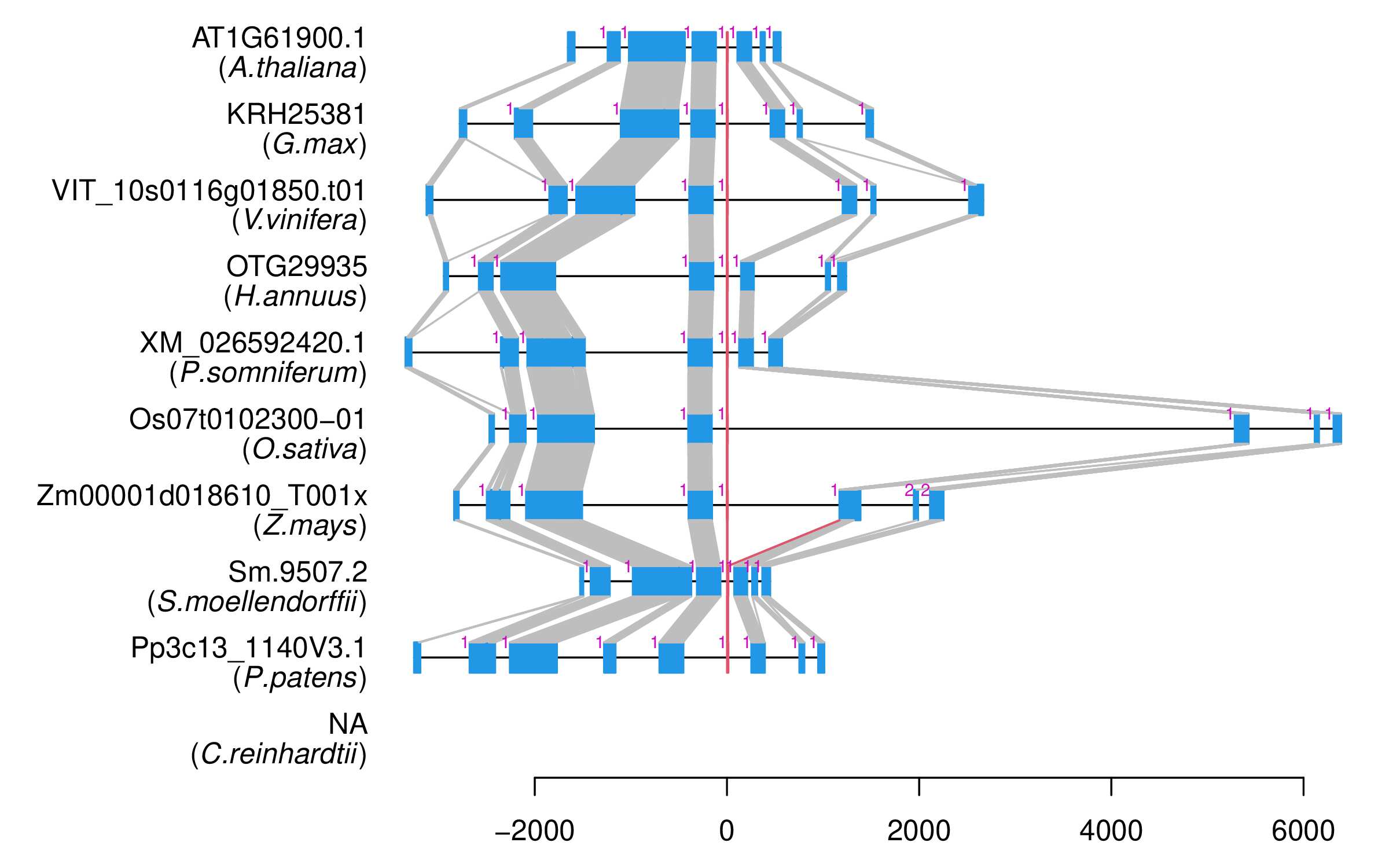 |
| Microexon DNA seq | TTGGAAATCAAG |
| Microexon Amino Acid seq | VGNQE |
| Microexon-tag DNA Seq | GATGTTTATGGTCTCTGTCACATAAGCCTTAAAGACTTTTCCCTCCAAGTTGGAAATCAAGAGGCTGGTTGTTTATTACCTAGTTTGCCTTCAGATGCTACATTTGAC |
| Microexon-tag Amino Acid Seq | DVYGLCHISLKDFSLQVGNQEAGCLLPSLPSDATFD |
| Microexon-tag spanning region | 8411363-8411884 |
| Microexon-tag prediction score | 0.9682 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | KRH11420x |
| Reference Transcript ID | KRH11420 |
| Gene ID | GLYMA_15G107200 |
| Gene Name | NA |
| Transcript ID | KRH11420 |
| Protein ID | KRH11420 |
| Gene ID | GLYMA_15G107200 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >KRH11420 MLLSLFCAMPHLFLFLFLFLLPLCALESLSSNHRQGPVRLDSRVGSMFIKPSPLGSPQPFLPLAPSPLAPFTNTTIPKLS GLCTLNFTTAESLISVTAIDCWEVFAPFLANVICCPQLEATLTILIGQSSKLTNVLALNGTVAKHCLADVEQILMGQGAT NNLKQNAILEAAKAIASKGSDILAIDAPHVQPEHSNRVNDCRNVVLRWLASKLEPSHAKKVLRGLSNCNVNKACPLVFPN TKQVAKGCVDEISNKTACCNAMESYVSHLQKQSFITNLQALDCAEALAMKLKRSNITADVYGLCHISLKDFSLQVGNQEA GCLLPSLPSDATFDSISGISFLCDLNDNIPAPWPSTSQLTSSSCNKSIYIPALPAAASSQSCLYSRDILFSVLVALLFLL MTTV* |
| CDS seq | >KRH11420 ATGCTGCTTTCCCTTTTCTGCGCCATGCCCCACCTCTTCCTCTTCCTCTTCCTCTTCCTCCTGCCTCTCTGTGCACTTGA ATCCCTTAGCAGTAATCATCGTCAGGGTCCTGTACGACTGGATAGCCGTGTAGGTTCTATGTTCATCAAACCCTCACCTC TTGGTTCTCCGCAACCCTTTCTTCCTCTCGCACCTTCACCTTTGGCTCCATTCACTAATACCACTATCCCAAAGTTATCA GGACTTTGCACTTTGAACTTTACTACTGCTGAAAGTTTGATAAGTGTGACAGCAATTGATTGCTGGGAAGTTTTTGCACC ATTTCTGGCTAATGTAATATGTTGTCCCCAATTGGAAGCCACTCTCACAATTCTTATTGGTCAATCCAGTAAACTTACCA ATGTACTTGCCTTAAACGGGACCGTTGCTAAACATTGCCTTGCAGATGTGGAACAAATTTTGATGGGCCAGGGTGCCACT AATAATCTGAAGCAGAATGCTATATTAGAAGCAGCTAAAGCAATTGCATCAAAAGGCTCTGATATTTTGGCCATAGATGC ACCACATGTTCAACCTGAGCACTCAAATCGGGTCAATGATTGTAGAAATGTTGTCCTCCGGTGGTTAGCTAGTAAGCTTG AACCTTCTCATGCCAAGAAAGTTCTTAGAGGACTGTCTAATTGCAACGTGAACAAAGCTTGTCCACTGGTTTTCCCCAAC ACAAAGCAAGTTGCCAAGGGTTGTGTGGATGAGATAAGTAACAAAACAGCATGCTGTAATGCTATGGAAAGCTACGTGTC TCACTTGCAAAAACAGAGCTTCATCACGAACTTGCAAGCTTTGGATTGTGCAGAGGCTTTGGCAATGAAATTGAAAAGAT CGAATATTACTGCAGATGTTTATGGTCTCTGTCACATAAGCCTTAAAGACTTTTCCCTCCAAGTTGGAAATCAAGAGGCT GGTTGTTTATTACCTAGTTTGCCTTCAGATGCTACATTTGACAGTATTTCTGGGATCAGCTTCCTTTGTGATCTAAATGA TAATATTCCAGCTCCTTGGCCTTCTACATCTCAACTGACTTCTTCATCGTGCAATAAATCTATCTACATCCCTGCTCTTC CTGCAGCAGCATCAAGTCAAAGTTGCCTTTACAGCCGTGACATTCTGTTCTCTGTGCTTGTTGCTTTGTTGTTTCTCTTG ATGACAACCGTGTAA |
| Microexon DNA seq | TTGGAAATCAAG |
| Microexon Amino Acid seq | VGNQE |
| Microexon-tag DNA Seq | GATGTTTATGGTCTCTGTCACATAAGCCTTAAAGACTTTTCCCTCCAAGTTGGAAATCAAGAGGCTGGTTGTTTATTACCTAGTTTGCCTTCAGATGCTACATTTGAC |
| Microexon-tag Amino Acid seq | DVYGLCHISLKDFSLQVGNQEAGCLLPSLPSDATFD |
| Transcript ID | KRH11420 |
| Gene ID | Gm.17625 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >KRH11420 MLLSLFCAMPHLFLFLFLFLLPLCALESLSSNHRQGPVRLDSRVGSMFIKPSPLGSPQPFLPLAPSPLAPFTNTTIPKLS GLCTLNFTTAESLISVTAIDCWEVFAPFLANVICCPQLEATLTILIGQSSKLTNVLALNGTVAKHCLADVEQILMGQGAT NNLKQNAILEAAKAIASKGSDILAIDAPHVQPEHSNRVNDCRNVVLRWLASKLEPSHAKKVLRGLSNCNVNKACPLVFPN TKQVAKGCVDEISNKTACCNAMESYVSHLQKQSFITNLQALDCAEALAMKLKRSNITADVYGLCHISLKDFSLQVGNQEA GCLLPSLPSDATFDSISGISFLCDLNDNIPAPWPSTSQLTSSSCNKSIYIPALPAAASSQSCLYSRDILFSVLVALLFLL MTTV* |
| CDS seq | >KRH11420 ATGCTGCTTTCCCTTTTCTGCGCCATGCCCCACCTCTTCCTCTTCCTCTTCCTCTTCCTCCTGCCTCTCTGTGCACTTGA ATCCCTTAGCAGTAATCATCGTCAGGGTCCTGTACGACTGGATAGCCGTGTAGGTTCTATGTTCATCAAACCCTCACCTC TTGGTTCTCCGCAACCCTTTCTTCCTCTCGCACCTTCACCTTTGGCTCCATTCACTAATACCACTATCCCAAAGTTATCA GGACTTTGCACTTTGAACTTTACTACTGCTGAAAGTTTGATAAGTGTGACAGCAATTGATTGCTGGGAAGTTTTTGCACC ATTTCTGGCTAATGTAATATGTTGTCCCCAATTGGAAGCCACTCTCACAATTCTTATTGGTCAATCCAGTAAACTTACCA ATGTACTTGCCTTAAACGGGACCGTTGCTAAACATTGCCTTGCAGATGTGGAACAAATTTTGATGGGCCAGGGTGCCACT AATAATCTGAAGCAGAATGCTATATTAGAAGCAGCTAAAGCAATTGCATCAAAAGGCTCTGATATTTTGGCCATAGATGC ACCACATGTTCAACCTGAGCACTCAAATCGGGTCAATGATTGTAGAAATGTTGTCCTCCGGTGGTTAGCTAGTAAGCTTG AACCTTCTCATGCCAAGAAAGTTCTTAGAGGACTGTCTAATTGCAACGTGAACAAAGCTTGTCCACTGGTTTTCCCCAAC ACAAAGCAAGTTGCCAAGGGTTGTGTGGATGAGATAAGTAACAAAACAGCATGCTGTAATGCTATGGAAAGCTACGTGTC TCACTTGCAAAAACAGAGCTTCATCACGAACTTGCAAGCTTTGGATTGTGCAGAGGCTTTGGCAATGAAATTGAAAAGAT CGAATATTACTGCAGATGTTTATGGTCTCTGTCACATAAGCCTTAAAGACTTTTCCCTCCAAGTTGGAAATCAAGAGGCT GGTTGTTTATTACCTAGTTTGCCTTCAGATGCTACATTTGACAGTATTTCTGGGATCAGCTTCCTTTGTGATCTAAATGA TAATATTCCAGCTCCTTGGCCTTCTACATCTCAACTGACTTCTTCATCGTGCAATAAATCTATCTACATCCCTGCTCTTC CTGCAGCAGCATCAAGTCAAAGTTGCCTTTACAGCCGTGACATTCTGTTCTCTGTGCTTGTTGCTTTGTTGTTTCTCTTG ATGACAACCGTGTAA |