| Microexon ID | At_1:23660722-23660733:- |
| Species | Arabidopsis thaliana | Coordinates | 1:23660722..23660733 |
| Microexon Cluster ID | MEP28 |
| Size | 12 |
| Phase | 0 |
| Pfam Domain Motif | Peptidase_M1 |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 24,19,5,12,48 |
| Microexon location in the Microexon-tag | 4 |
| Microexon-tag DNA Seq | GTTMGRCCWCAYTCTTAYATYAAGATGGACAACTTCTAYACAGTRACGGTKTATGARAAGGGWGCTGAAGTTGTCMGRATGTACAARACMTTRYTKGGRAGTYMAGGR |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 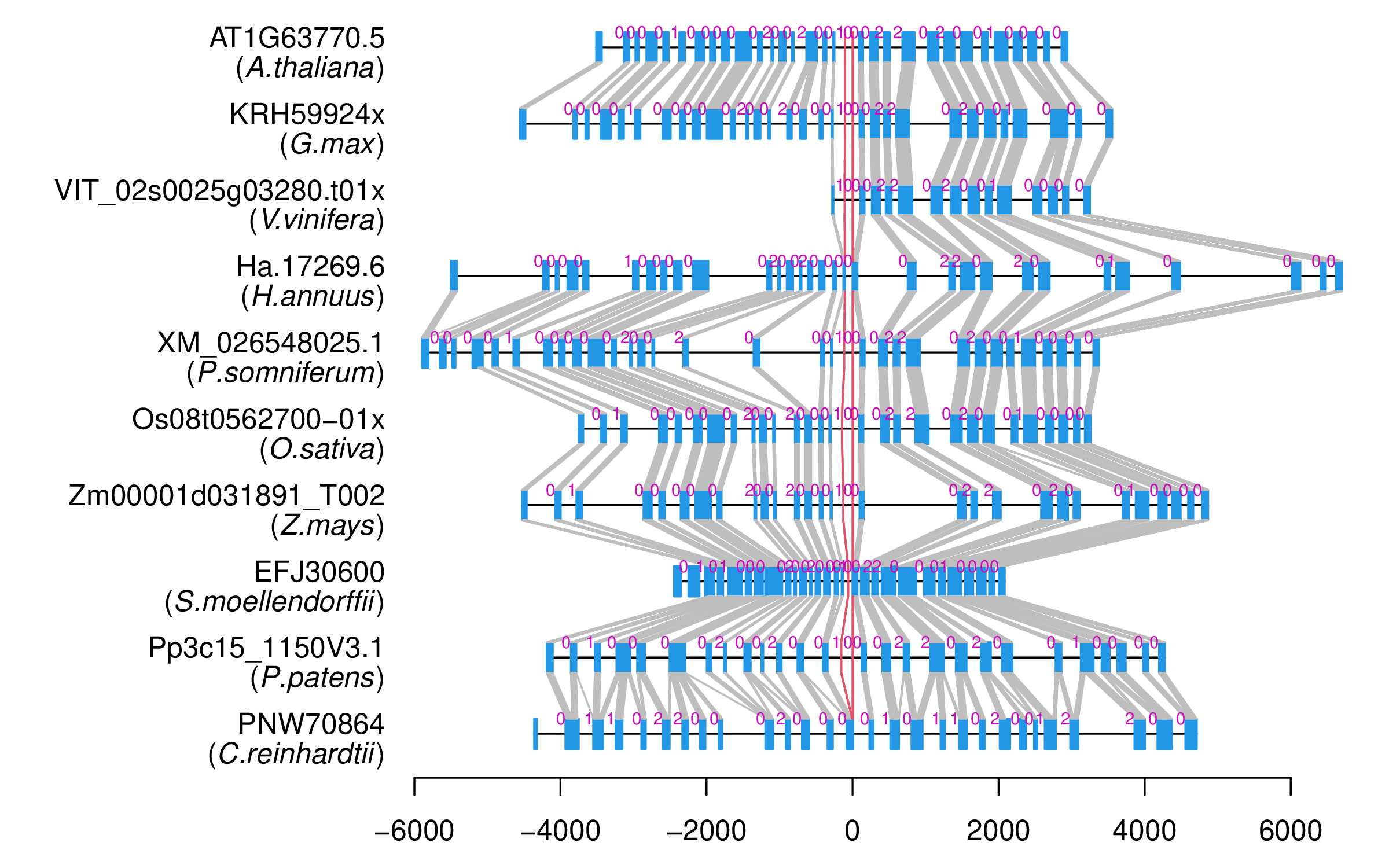 |
| Microexon DNA seq | GTTTATGAAAAG |
| Microexon Amino Acid seq | VYEK |
| Microexon-tag DNA Seq | GTTCGCCCACATTCATACATCAAGATGGATAACTTCTACACAGTGACGGTTTATGAAAAGGGAGCTGAGGTCGTCAGGATGTACAAAACTCTACTAGGAACTCAGGGG |
| Microexon-tag Amino Acid Seq | VRPHSYIKMDNFYTVTVYEKGAEVVRMYKTLLGTQG |
| Microexon-tag spanning region | 23660597-23661112 |
| Microexon-tag prediction score | 0.975 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | AT1G63770.5x |
| Reference Transcript ID | AT1G63770.5 |
| Gene ID | AT1G63770 |
| Gene Name | NA |
| Transcript ID | AT1G63770.5 |
| Protein ID | AT1G63770.5 |
| Gene ID | AT1G63770 |
| Gene Name | NA |
| Pfam domain motif | Peptidase_M1 |
| Motif E-value | 1.6e-50 |
| Motif start | 323 |
| Motif end | 534 |
| Protein seq | >AT1G63770.5 MARLIIPCRSSSLARVNLLGLLSRAPVPVRSSCLRSSANRLTQHRPFLTSEAICLRKNRFLPHSVDTHKQNSRRLICSVA TESVPDKAEDSKMDAPKEIFLKNYTKPDYYFETVDLSFSLGEEKTIVSSKIKVSPRVKGSSAALVLDGHDLKLLSVKVEG KLLKEGDYQLDSRHLTLPSLPAEESFVLEIDTEIYPHKNTSLEGLYKSSGNFCTQCEAEGFRKITFYQDRPDIMAKYTCR VEGDKTLYPVLLSNGNLISQGDIEGGRHYALWEDPFKKPCYLFALVAGQLVSRDDTFTTRSGRQVSLKIWTPAEDLPKTA HAMYSLKAAMKWDEDVFGLEYDLDLFNIVAVPDFNMGAMENKSLNIFNSKLVLASPETATDADYAAILGVIGHEYFHNWT GNRVTCRDWFQLSLKEGLTVFRDQEFSSDMGSRTVKRIADVSKLRIYQFPQDAGPMAHPVRPHSYIKMDNFYTVTVYEKG AEVVRMYKTLLGTQGFRKGIDLYFERHDEQAVTCEDFFAAMRDANNADFANFLQWYSQAGTPVVKVVSSYNADARTFSLK FSQEIPPTPGQPTKEPTFIPVVVGLLDSSGKDITLSSVHHDGTVQTISGSSTILRVTKKEEEFVFSDIPERPVPSLFRGF SAPVRVETDLSNDDLFFLLAHDSDEFNRWEAGQVLARKLMLNLVSDFQQNKPLALNPKFVQGLGSVLSDSSLDKEFIAKA ITLPGEGEIMDMMAVADPDAVHAVRKFVRKQLASELKEELLKIVENNRSTEAYVFDHSNMARRALKNTALAYLASLEDPA YMELALNEYKMATNLTDQFAALAALSQNPGKTRDDILADFYNKWQDDYLVVNKWFLLQSTSDIPGNVENVKKLLDHPAFD LRNPNKVYSLIGGFCGSPVNFHAKDGSGYKFLGDIVVQLDKLNPQVASRMVSAFSRWKRYDETRQGLAKAQLEMIMSANG LSENVFEIASKSLAA* |
| CDS seq | >AT1G63770.5 ATGGCTCGGTTGATAATTCCTTGTCGAAGTTCGTCTCTGGCGAGAGTCAATCTTCTGGGTTTGCTCTCTCGTGCTCCTGT TCCTGTTAGAAGCAGTTGTCTTCGTAGTTCGGCAAACAGACTTACTCAACACAGACCGTTTCTTACTTCCGAGGCCATTT GTTTGAGGAAGAATCGGTTTCTACCCCATTCTGTTGATACACATAAGCAAAACAGCAGGAGGCTCATTTGTTCTGTTGCC ACAGAATCAGTTCCGGATAAAGCTGAAGATTCCAAAATGGATGCACCTAAAGAAATATTTCTCAAGAACTACACAAAGCC TGATTACTACTTTGAAACTGTGGATCTGAGCTTCTCTCTAGGTGAAGAGAAAACAATTGTTAGCTCTAAAATCAAGGTTT CTCCTCGAGTTAAAGGATCTTCTGCTGCATTGGTCTTGGATGGACATGACTTGAAGCTACTTTCTGTCAAGGTTGAGGGG AAGCTTCTTAAGGAAGGGGATTACCAGTTGGACTCTCGCCATCTAACTCTTCCTTCGCTTCCAGCTGAGGAGTCCTTTGT TTTGGAGATTGATACTGAGATATACCCCCACAAGAATACTTCACTTGAGGGGCTTTACAAGTCTTCTGGGAATTTCTGCA CACAGTGTGAAGCAGAAGGTTTCCGCAAAATTACATTTTACCAGGATCGTCCTGATATAATGGCTAAGTACACGTGTCGT GTGGAAGGTGACAAGACACTTTATCCTGTGTTATTGTCCAATGGAAACCTCATTTCTCAAGGAGATATAGAGGGTGGTCG ACACTATGCCTTATGGGAGGATCCATTCAAGAAACCGTGCTATCTATTTGCTTTGGTGGCTGGACAGCTAGTGAGCAGAG ATGATACATTTACCACACGCTCTGGTAGGCAGGTTTCCCTGAAAATCTGGACTCCTGCAGAAGATCTACCAAAGACTGCC CATGCCATGTATTCCCTAAAAGCGGCCATGAAGTGGGATGAGGATGTGTTCGGGCTTGAGTATGACCTGGATCTCTTCAA CATTGTTGCTGTTCCAGATTTTAACATGGGAGCCATGGAAAACAAGAGTTTGAATATTTTTAATTCCAAGCTTGTCCTAG CATCTCCAGAAACAGCAACAGATGCAGATTACGCTGCAATTTTGGGTGTTATTGGTCATGAGTACTTTCACAATTGGACA GGGAACAGGGTGACATGCCGTGACTGGTTCCAACTCAGTCTAAAGGAAGGACTTACTGTCTTCCGTGACCAGGAATTTTC ATCTGACATGGGAAGCCGAACTGTAAAGCGAATTGCTGATGTTTCAAAGCTTCGGATCTATCAATTTCCGCAGGATGCTG GTCCTATGGCACATCCTGTTCGCCCACATTCATACATCAAGATGGATAACTTCTACACAGTGACGGTTTATGAAAAGGGA GCTGAGGTCGTCAGGATGTACAAAACTCTACTAGGAACTCAGGGGTTCCGAAAGGGAATTGATCTCTATTTTGAAAGACA TGATGAGCAAGCAGTGACTTGTGAAGACTTCTTTGCTGCTATGCGTGATGCAAATAATGCAGACTTTGCTAATTTCTTGC AATGGTACTCTCAAGCTGGAACGCCCGTTGTCAAAGTGGTATCCTCTTACAATGCTGACGCTCGTACTTTCTCTTTAAAA TTCAGTCAGGAGATACCTCCAACTCCAGGCCAGCCAACAAAAGAACCTACATTTATTCCAGTGGTTGTTGGTCTTTTGGA CTCAAGTGGGAAAGACATTACTCTTTCCTCTGTTCATCATGATGGTACAGTGCAGACCATTTCAGGCAGCAGCACAATAC TTCGAGTGACTAAGAAAGAAGAAGAGTTTGTGTTTTCTGATATACCAGAAAGACCTGTTCCATCCCTATTTAGGGGATTC AGTGCCCCAGTTCGTGTTGAAACTGATCTCTCTAATGATGACTTATTCTTCCTCCTAGCACATGATTCAGATGAATTCAA TAGGTGGGAGGCCGGTCAAGTTCTGGCAAGAAAGCTGATGCTGAACTTAGTTTCTGATTTCCAGCAAAATAAACCGTTGG CTCTAAACCCAAAATTTGTGCAAGGTCTCGGCAGTGTGCTTTCTGACTCAAGCTTGGACAAGGAATTTATAGCCAAAGCA ATAACACTACCTGGGGAGGGAGAGATAATGGACATGATGGCCGTGGCGGATCCTGATGCTGTTCATGCTGTTAGAAAGTT TGTACGAAAGCAGCTTGCATCTGAACTTAAGGAGGAGCTTCTAAAGATAGTCGAGAACAATAGGAGCACAGAAGCTTATG TCTTTGACCACTCAAACATGGCGAGGCGTGCTTTGAAGAATACAGCTCTAGCTTATCTTGCATCTCTCGAAGATCCAGCA TATATGGAACTTGCACTGAACGAATACAAGATGGCCACCAATTTGACCGACCAATTTGCTGCTTTGGCAGCTCTATCCCA GAACCCTGGTAAAACCCGTGACGACATTCTTGCCGACTTCTATAACAAGTGGCAGGACGATTACTTGGTTGTTAATAAAT GGTTCCTCCTTCAATCAACATCCGACATTCCTGGCAATGTAGAGAATGTCAAGAAGCTTTTGGATCACCCAGCTTTCGAT CTGCGCAACCCAAACAAGGTTTATTCGCTTATTGGAGGGTTCTGCGGTTCCCCAGTGAATTTCCATGCCAAGGATGGATC AGGTTACAAGTTCTTGGGTGACATTGTTGTCCAGTTAGACAAATTGAACCCTCAGGTTGCTTCTCGTATGGTGTCTGCCT TTTCGAGGTGGAAGCGGTACGATGAAACCCGTCAAGGTCTAGCCAAGGCACAATTGGAAATGATAATGTCTGCTAATGGG CTGTCTGAGAATGTCTTTGAGATTGCCTCCAAGAGTTTGGCTGCTTGA |
| Microexon DNA seq | GTTTATGAAAAG |
| Microexon Amino Acid seq | VYEK |
| Microexon-tag DNA Seq | GTTCGCCCACATTCATACATCAAGATGGATAACTTCTACACAGTGACGGTTTATGAAAAGGGAGCTGAGGTCGTCAGGATGTACAAAACTCTACTAGGAACTCAGGGG |
| Microexon-tag Amino Acid seq | VRPHSYIKMDNFYTVTVYEKGAEVVRMYKTLLGTQG |
| Transcript ID | At.5504.1 |
| Gene ID | At.5504 |
| Gene Name | NA |
| Pfam domain motif | Peptidase_M1 |
| Motif E-value | 1.3e-50 |
| Motif start | 231 |
| Motif end | 442 |
| Protein seq | >At.5504.1 MDAPKEIFLKNYTKPDYYFETVDLSFSLGEEKTIVSSKIKVSPRVKGSSAALVLDGHDLKLLSVKVEGKLLKEGDYQLDS RHLTLPSLPAEESFVLEIDTEIYPHKNTSLEGLYKSSGNFCTQCEAEGFRKITFYQDRPDIMAKYTCRVEGDKTLYPVLL SNGNLISQGDIEGGRHYALWEDPFKKPCYLFALVAGQLVSRDDTFTTRSGRQVSLKIWTPAEDLPKTAHAMYSLKAAMKW DEDVFGLEYDLDLFNIVAVPDFNMGAMENKSLNIFNSKLVLASPETATDADYAAILGVIGHEYFHNWTGNRVTCRDWFQL SLKEGLTVFRDQEFSSDMGSRTVKRIADVSKLRIYQFPQDAGPMAHPVRPHSYIKMDNFYTVTVYEKGAEVVRMYKTLLG TQGFRKGIDLYFERHDEQAVTCEDFFAAMRDANNADFANFLQWYSQAGTPVVKVVSSYNADARTFSLKFSQEIPPTPGQP TKEPTFIPVVVGLLDSSGKDITLSSVHHDGTVQTISGSSTILRVTKKEEEFVFSDIPERPVPSLFRGFSAPVRVETDLSN DDLFFLLAHDSDEFNRWEAGQVLARKLMLNLVSDFQQNKPLALNPKFVQGLGSVLSDSSLDKEFIAKAITLPGEGEIMDM MAVADPDAVHAVRKFVRKQLASELKEELLKIVENNRSTEAYVFDHSNMARRALKNTALAYLASLEDPAYMELALNEYKMA TNLTDQFAALAALSQNPGKTRDDILADFYNKWQDDYLVVNKWFLLQSTSDIPGNVENVKKLLDHPAFDLRNPNKVYSLIG GFCGSPVNFHAKDGSGYKFLGDIVVQLDKLNPQVASRMVSAFSRWKRYDETRQGLAKAQLEMIMSANGLSENVFEIASKS LAA* |
| CDS seq | >At.5504.1 ATGGATGCACCTAAAGAAATATTTCTCAAGAACTACACAAAGCCTGATTACTACTTTGAAACTGTGGATCTGAGCTTCTC TCTAGGTGAAGAGAAAACAATTGTTAGCTCTAAAATCAAGGTTTCTCCTCGAGTTAAAGGATCTTCTGCTGCATTGGTCT TGGATGGACATGACTTGAAGCTACTTTCTGTCAAGGTTGAGGGGAAGCTTCTTAAGGAAGGGGATTACCAGTTGGACTCT CGCCATCTAACTCTTCCTTCGCTTCCAGCTGAGGAGTCCTTTGTTTTGGAGATTGATACTGAGATATACCCCCACAAGAA TACTTCACTTGAGGGGCTTTACAAGTCTTCTGGGAATTTCTGCACACAGTGTGAAGCAGAAGGTTTCCGCAAAATTACAT TTTACCAGGATCGTCCTGATATAATGGCTAAGTACACGTGTCGTGTGGAAGGTGACAAGACACTTTATCCTGTGTTATTG TCCAATGGAAACCTCATTTCTCAAGGAGATATAGAGGGTGGTCGACACTATGCCTTATGGGAGGATCCATTCAAGAAACC GTGCTATCTATTTGCTTTGGTGGCTGGACAGCTAGTGAGCAGAGATGATACATTTACCACACGCTCTGGTAGGCAGGTTT CCCTGAAAATCTGGACTCCTGCAGAAGATCTACCAAAGACTGCCCATGCCATGTATTCCCTAAAAGCGGCCATGAAGTGG GATGAGGATGTGTTCGGGCTTGAGTATGACCTGGATCTCTTCAACATTGTTGCTGTTCCAGATTTTAACATGGGAGCCAT GGAAAACAAGAGTTTGAATATTTTTAATTCCAAGCTTGTCCTAGCATCTCCAGAAACAGCAACAGATGCAGATTACGCTG CAATTTTGGGTGTTATTGGTCATGAGTACTTTCACAATTGGACAGGGAACAGGGTGACATGCCGTGACTGGTTCCAACTC AGTCTAAAGGAAGGACTTACTGTCTTCCGTGACCAGGAATTTTCATCTGACATGGGAAGCCGAACTGTAAAGCGAATTGC TGATGTTTCAAAGCTTCGGATCTATCAATTTCCGCAGGATGCTGGTCCTATGGCACATCCTGTTCGCCCACATTCATACA TCAAGATGGATAACTTCTACACAGTGACGGTTTATGAAAAGGGAGCTGAGGTCGTCAGGATGTACAAAACTCTACTAGGA ACTCAGGGGTTCCGAAAGGGAATTGATCTCTATTTTGAAAGACATGATGAGCAAGCAGTGACTTGTGAAGACTTCTTTGC TGCTATGCGTGATGCAAATAATGCAGACTTTGCTAATTTCTTGCAATGGTACTCTCAAGCTGGAACGCCCGTTGTCAAAG TGGTATCCTCTTACAATGCTGACGCTCGTACTTTCTCTTTAAAATTCAGTCAGGAGATACCTCCAACTCCAGGCCAGCCA ACAAAAGAACCTACATTTATTCCAGTGGTTGTTGGTCTTTTGGACTCAAGTGGGAAAGACATTACTCTTTCCTCTGTTCA TCATGATGGTACAGTGCAGACCATTTCAGGCAGCAGCACAATACTTCGAGTGACTAAGAAAGAAGAAGAGTTTGTGTTTT CTGATATACCAGAAAGACCTGTTCCATCCCTATTTAGGGGATTCAGTGCCCCAGTTCGTGTTGAAACTGATCTCTCTAAT GATGACTTATTCTTCCTCCTAGCACATGATTCAGATGAATTCAATAGGTGGGAGGCCGGTCAAGTTCTGGCAAGAAAGCT GATGCTGAACTTAGTTTCTGATTTCCAGCAAAATAAACCGTTGGCTCTAAACCCAAAATTTGTGCAAGGTCTCGGCAGTG TGCTTTCTGACTCAAGCTTGGACAAGGAATTTATAGCCAAAGCAATAACACTACCTGGGGAGGGAGAGATAATGGACATG ATGGCCGTGGCGGATCCTGATGCTGTTCATGCTGTTAGAAAGTTTGTACGAAAGCAGCTTGCATCTGAACTTAAGGAGGA GCTTCTAAAGATAGTCGAGAACAATAGGAGCACAGAAGCTTATGTCTTTGACCACTCAAACATGGCGAGGCGTGCTTTGA AGAATACAGCTCTAGCTTATCTTGCATCTCTCGAAGATCCAGCATATATGGAACTTGCACTGAACGAATACAAGATGGCC ACCAATTTGACCGACCAATTTGCTGCTTTGGCAGCTCTATCCCAGAACCCTGGTAAAACCCGTGACGACATTCTTGCCGA CTTCTATAACAAGTGGCAGGACGATTACTTGGTTGTTAATAAATGGTTCCTCCTTCAATCAACATCCGACATTCCTGGCA ATGTAGAGAATGTCAAGAAGCTTTTGGATCACCCAGCTTTCGATCTGCGCAACCCAAACAAGGTTTATTCGCTTATTGGA GGGTTCTGCGGTTCCCCAGTGAATTTCCATGCCAAGGATGGATCAGGTTACAAGTTCTTGGGTGACATTGTTGTCCAGTT AGACAAATTGAACCCTCAGGTTGCTTCTCGTATGGTGTCTGCCTTTTCGAGGTGGAAGCGGTACGATGAAACCCGTCAAG GTCTAGCCAAGGCACAATTGGAAATGATAATGTCTGCTAATGGGCTGTCTGAGAATGTCTTTGAGATTGCCTCCAAGAGT TTGGCTGCTTGA |