| Microexon ID | Ps_NC_039364.1:194459474-194459484:+ |
| Species | Papaver somniferum | Coordinates | NC_039364.1:194459474..194459484 |
| Microexon Cluster ID | MEP27 |
| Size | 11 |
| Phase | 1 |
| Pfam Domain Motif | Gelsolin |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 49,11,48 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | MRRGADRYTGWMAGWGATCCYCAYYTGTTYDCWTKYWCWTTYWMTAAAGGRAADYTKRAGGTKRMRGARRTHTACAAYTTYWCYCARGATGAYYTGWTGACWGARGAT |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 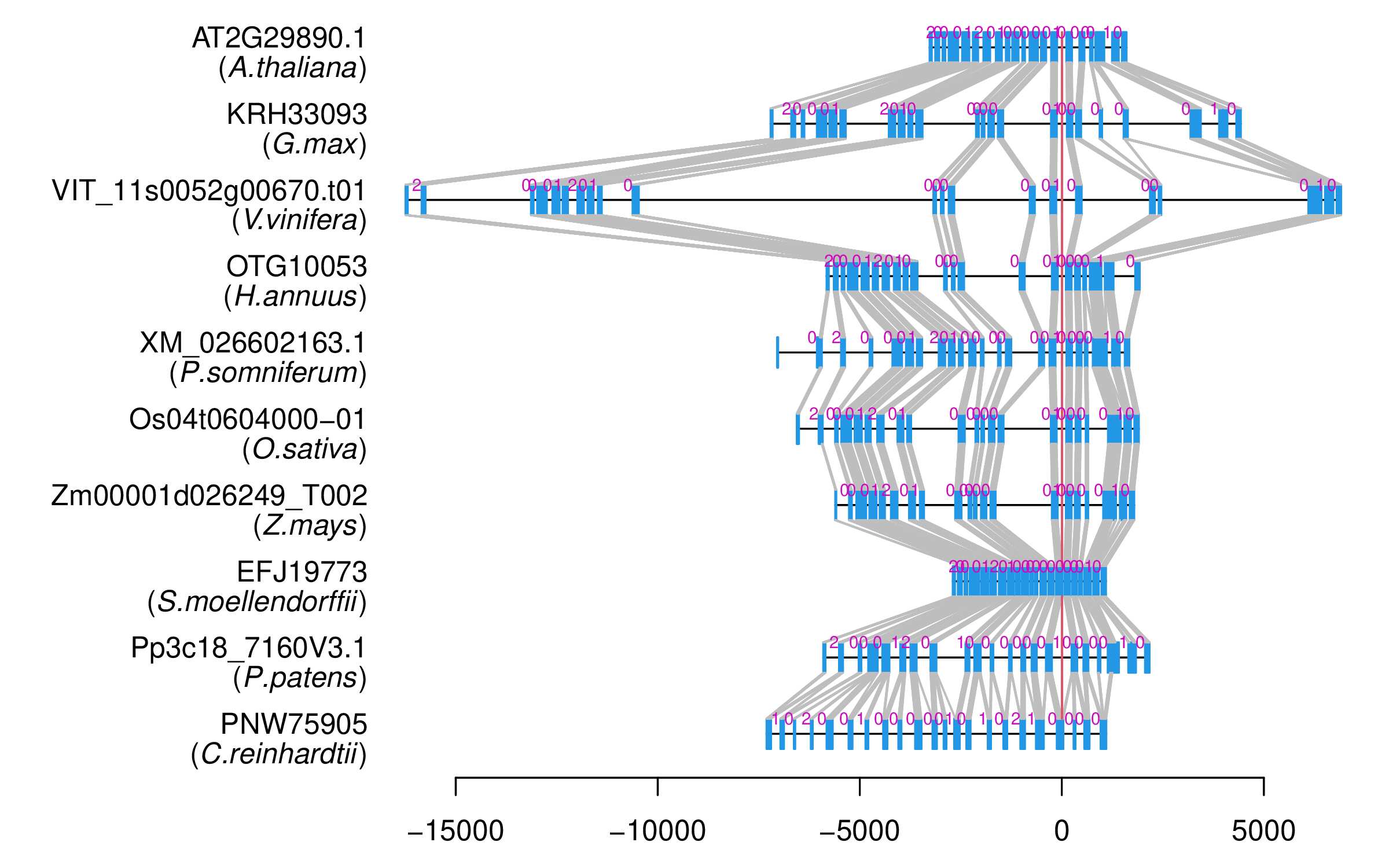 |
| Microexon DNA seq | GCAATCTTAAG |
| Microexon Amino Acid seq | GNLK |
| Microexon-tag DNA Seq | AGGGATGCAGAAAGTGATCCTCATCTATTTTCATGCTCTTTCTCAAAAGGCAATCTTAAGGTGTCAGAGATATACAACTTTTCCCAGGATGATCTGATGACTGAAGAT |
| Microexon-tag Amino Acid Seq | RDAESDPHLFSCSFSKGNLKVSEIYNFSQDDLMTED |
| Microexon-tag spanning region | 194459269-194459631 |
| Microexon-tag prediction score | 0.9687 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026548293.1x |
| Reference Transcript ID | XM_026548293.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026548293.1 |
| Protein ID | XP_026404078.1 |
| Gene ID | LOC113299291 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026404078.1 MKEFVFPREVTSGSLAEARKAGNNSFDQKNNSMAVSMRDLDPAFQGAGQKAGMEIWRIENFHPVPVPTSSHGKFFTGDSY IILKTTALKSGAFRHDIHYWQGKDTSQDEAGTAAMKTVELDAALGGRAVQYREVQGHETAQFLSYFKPCIIPQAGGASSG FKHVQPEEHETRLYVSKGKHVVHVKEVAFARSTLNHDDIFILDTKSKIFQFNGSNSSIQERAKALEVVQHIKDTYHDGKC EVAAIEDGRLMSDAETGEFWGFFGGFAPLPRKTVSEDDKTVEASSPKLLRITKGQTEPVDADPLTRELLDTNHCYILDCG IEVFVWTGRNTSLDDRKTGSTAVEELVRGPDRPKAHVIRVIEGFETVVFRSKFDSWPQTNDVTVSEDGRGKVAALLKRQG FNVKGLLKAAPAKEEPQPYIDCTGNLQVWRINGQEKTLIPSAEQSKFYSGDCYIFQYSYPGEDKEEILIGTWFGKQSVEE ERTAAISLASKMVEALKSQAAQARIFEGNEPIQFFSIFQSFVVFKGGVSSGYKNYIAENGVADETYSEDGVALFRVQGSG PENMQAIQVAPVASSLNSCYCYILHSGSTVFTWSGNLTTADDHELVERQLDIVKPNLQSKPQKEGTETDQFWELLGGKLE FPGQKITRDAESDPHLFSCSFSKGNLKVSEIYNFSQDDLMTEDIFILDCHSDVFVWIGQQVESKSKTQALTIAEKFIEQD VLLEKLSRDAPIFIVMEGFEPSFFTRFFTWDSAKSAMHGNSFQRKYSIMKNGVAPTPDKPKRRPPASYGGRSSVPDKSQR SRSMSFSPDRVRVRGRSPAFNALAATFESPNARNLSTPPPMVRKIYPKSVTPDSAKLDAAKLASRSAAIAALTASFEQPA PPSPASAPSRIPKPKPSPETPKSEPTSNSMSSRIEALTIQEDVKEDEAEDEEGLPIYPYERLKVFSTDPVTDIDVTKRET YLSSEEFREKFGMAKDAFYKLPKWKQNKLKMALQLF* |
| CDS seq | >XM_026548293.1 ATGAAGGAATTTGTTTTTCCTCGGGAGGTTACCTCTGGTTCCCTCGCCGAGGCAAGGAAGGCAGGAAATAATTCATTTGA TCAAAAGAACAACAGTATGGCTGTTTCTATGAGGGATTTAGACCCAGCTTTCCAGGGAGCTGGGCAAAAAGCTGGAATGG AGATCTGGCGCATTGAGAACTTCCACCCCGTTCCTGTTCCCACATCGTCCCATGGGAAGTTCTTCACAGGAGATTCATAC ATTATTCTGAAGACAACTGCCTTGAAAAGTGGTGCATTTCGGCATGATATCCATTATTGGCAAGGGAAAGATACGAGTCA GGACGAAGCTGGTACTGCAGCCATGAAGACAGTTGAACTAGATGCTGCCCTAGGAGGACGTGCTGTCCAGTATCGGGAGG TGCAGGGCCATGAAACCGCTCAATTTCTATCATATTTTAAACCATGTATCATCCCCCAAGCAGGTGGTGCTTCATCTGGG TTCAAGCACGTTCAGCCCGAGGAACATGAAACCCGCCTATATGTTAGCAAAGGAAAGCATGTTGTCCACGTTAAAGAGGT TGCTTTTGCAAGATCAACACTCAATCACGATGACATTTTTATTTTAGACACCAAGTCTAAAATCTTTCAATTTAATGGTT CTAACTCATCCATTCAAGAGAGGGCTAAAGCTTTAGAAGTTGTCCAGCACATTAAAGATACTTATCACGATGGGAAATGT GAGGTAGCTGCTATTGAGGACGGGAGGTTGATGTCTGATGCTGAAACTGGAGAATTCTGGGGATTTTTTGGTGGCTTTGC TCCACTTCCAAGAAAAACTGTCTCTGAAGATGATAAAACTGTGGAAGCTTCTTCACCTAAGCTTCTCCGCATCACCAAAG GGCAGACAGAACCTGTTGATGCTGATCCTTTGACAAGAGAGTTGTTAGACACAAATCATTGCTACATTTTAGATTGTGGT ATAGAAGTATTTGTGTGGACGGGAAGGAATACCTCTCTGGATGATCGAAAAACTGGCAGTACAGCTGTTGAAGAGTTGGT TCGTGGCCCCGACCGACCAAAAGCTCACGTTATCCGTGTTATTGAAGGATTTGAAACAGTTGTTTTTCGATCGAAGTTTG ATTCATGGCCTCAAACAAATGATGTAACTGTATCTGAGGATGGTAGAGGCAAAGTTGCTGCACTCTTAAAGCGCCAAGGA TTTAATGTTAAGGGCCTTCTAAAGGCTGCTCCTGCAAAAGAAGAACCTCAGCCATATATTGATTGCACTGGAAATCTTCA GGTTTGGCGTATAAATGGCCAGGAAAAGACTCTCATACCATCTGCCGAACAGTCCAAGTTTTATAGTGGAGATTGTTATA TCTTTCAATACTCATATCCAGGCGAAGATAAAGAGGAGATCCTCATTGGTACTTGGTTCGGGAAGCAGAGTGTTGAGGAG GAGAGAACTGCAGCAATATCACTGGCAAGCAAGATGGTTGAAGCTTTGAAGTCTCAGGCAGCACAGGCTCGTATCTTCGA AGGAAACGAACCCATTCAGTTTTTTTCGATCTTTCAGAGCTTTGTCGTGTTCAAGGGTGGGGTTAGTTCTGGGTATAAGA ATTACATTGCGGAGAACGGAGTAGCTGATGAGACATATTCAGAAGATGGGGTTGCACTATTTCGCGTTCAAGGTTCTGGA CCTGAGAACATGCAGGCTATTCAAGTTGCACCGGTGGCTTCATCATTAAACTCTTGTTACTGTTACATATTACATAGCGG TTCCACAGTCTTTACATGGTCCGGGAACCTTACTACGGCAGATGACCATGAGCTTGTAGAGAGACAGCTAGATATAGTAA AGCCAAATCTTCAGTCAAAACCACAGAAAGAGGGCACAGAAACTGATCAATTCTGGGAGTTGCTTGGAGGCAAACTTGAA TTCCCTGGACAGAAAATTACAAGGGATGCAGAAAGTGATCCTCATCTATTTTCATGCTCTTTCTCAAAAGGCAATCTTAA GGTGTCAGAGATATACAACTTTTCCCAGGATGATCTGATGACTGAAGATATATTCATCCTAGATTGCCATTCAGACGTAT TTGTTTGGATCGGGCAACAGGTTGAATCTAAGAGTAAAACTCAAGCTTTGACCATTGCAGAGAAATTTATCGAGCAAGAT GTTCTCCTTGAAAAGTTATCTCGTGATGCTCCAATATTTATTGTAATGGAAGGGTTTGAACCATCTTTCTTCACACGTTT CTTCACCTGGGACTCCGCCAAATCGGCTATGCATGGAAACTCATTTCAGAGGAAGTATTCGATCATGAAAAATGGAGTTG CTCCAACCCCAGATAAGCCCAAGAGGAGACCTCCAGCATCATATGGTGGAAGATCAAGTGTTCCAGACAAATCACAGCGA TCCAGAAGCATGTCTTTTAGTCCAGACAGAGTCCGTGTTAGAGGCAGGTCTCCAGCTTTTAATGCACTTGCTGCTACATT TGAGAGCCCTAATGCCAGAAATCTCTCTACTCCGCCTCCAATGGTTAGAAAGATCTATCCAAAGTCCGTTACCCCTGATT CGGCAAAGCTGGATGCAGCAAAGTTGGCTTCAAGATCAGCGGCCATAGCAGCTCTCACAGCTTCATTTGAGCAACCAGCA CCACCATCACCAGCAAGTGCTCCATCCAGAATTCCTAAGCCTAAACCGAGCCCTGAGACTCCAAAATCAGAACCAACCTC CAATTCAATGAGTAGTAGAATAGAAGCCCTAACTATTCAGGAAGATGTGAAAGAGGATGAAGCTGAGGACGAGGAAGGAC TTCCTATATACCCATATGAACGTCTGAAAGTGTTTTCAACAGATCCTGTTACAGATATTGATGTAACCAAGCGAGAGACA TATCTCTCTTCAGAAGAGTTCAGGGAGAAATTCGGCATGGCAAAGGATGCTTTCTATAAGTTACCGAAATGGAAGCAGAA CAAGCTTAAAATGGCACTTCAATTGTTTTGA |
| Microexon DNA seq | GCAATCTTAAG |
| Microexon Amino Acid seq | GNLK |
| Microexon-tag DNA Seq | AGGGATGCAGAAAGTGATCCTCATCTATTTTCATGCTCTTTCTCAAAAGGCAATCTTAAGGTGTCAGAGATATACAACTTTTCCCAGGATGATCTGATGACTGAAGAT |
| Microexon-tag Amino Acid seq | RDAESDPHLFSCSFSKGNLKVSEIYNFSQDDLMTED |
| Transcript ID | XM_026548294.1 |
| Gene ID | Ps.45292 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026548294.1 MAVSMRDLDPAFQGAGQKAGMEIWRIENFHPVPVPTSSHGKFFTGDSYIILKTTALKSGAFRHDIHYWQGKDTSQDEAGT AAMKTVELDAALGGRAVQYREVQGHETAQFLSYFKPCIIPQAGGASSGFKHVQPEEHETRLYVSKGKHVVHVKEVAFARS TLNHDDIFILDTKSKIFQFNGSNSSIQERAKALEVVQHIKDTYHDGKCEVAAIEDGRLMSDAETGEFWGFFGGFAPLPRK TVSEDDKTVEASSPKLLRITKGQTEPVDADPLTRELLDTNHCYILDCGIEVFVWTGRNTSLDDRKTGSTAVEELVRGPDR PKAHVIRVIEGFETVVFRSKFDSWPQTNDVTVSEDGRGKVAALLKRQGFNVKGLLKAAPAKEEPQPYIDCTGNLQVWRIN GQEKTLIPSAEQSKFYSGDCYIFQYSYPGEDKEEILIGTWFGKQSVEEERTAAISLASKMVEALKSQAAQARIFEGNEPI QFFSIFQSFVVFKGGVSSGYKNYIAENGVADETYSEDGVALFRVQGSGPENMQAIQVAPVASSLNSCYCYILHSGSTVFT WSGNLTTADDHELVERQLDIVKPNLQSKPQKEGTETDQFWELLGGKLEFPGQKITRDAESDPHLFSCSFSKGNLKVSEIY NFSQDDLMTEDIFILDCHSDVFVWIGQQVESKSKTQALTIAEKFIEQDVLLEKLSRDAPIFIVMEGFEPSFFTRFFTWDS AKSAMHGNSFQRKYSIMKNGVAPTPDKPKRRPPASYGGRSSVPDKSQRSRSMSFSPDRVRVRGRSPAFNALAATFESPNA RNLSTPPPMVRKIYPKSVTPDSAKLDAAKLASRSAAIAALTASFEQPAPPSPASAPSRIPKPKPSPETPKSEPTSNSMSS RIEALTIQEDVKEDEAEDEEGLPIYPYERLKVFSTDPVTDIDVTKRETYLSSEEFREKFGMAKDAFYKLPKWKQNKLKMA LQLF* |
| CDS seq | >XM_026548294.1 ATGGCTGTTTCTATGAGGGATTTAGACCCAGCTTTCCAGGGAGCTGGGCAAAAAGCTGGAATGGAGATCTGGCGCATTGA GAACTTCCACCCCGTTCCTGTTCCCACATCGTCCCATGGGAAGTTCTTCACAGGAGATTCATACATTATTCTGAAGACAA CTGCCTTGAAAAGTGGTGCATTTCGGCATGATATCCATTATTGGCAAGGGAAAGATACGAGTCAGGACGAAGCTGGTACT GCAGCCATGAAGACAGTTGAACTAGATGCTGCCCTAGGAGGACGTGCTGTCCAGTATCGGGAGGTGCAGGGCCATGAAAC CGCTCAATTTCTATCATATTTTAAACCATGTATCATCCCCCAAGCAGGTGGTGCTTCATCTGGGTTCAAGCACGTTCAGC CCGAGGAACATGAAACCCGCCTATATGTTAGCAAAGGAAAGCATGTTGTCCACGTTAAAGAGGTTGCTTTTGCAAGATCA ACACTCAATCACGATGACATTTTTATTTTAGACACCAAGTCTAAAATCTTTCAATTTAATGGTTCTAACTCATCCATTCA AGAGAGGGCTAAAGCTTTAGAAGTTGTCCAGCACATTAAAGATACTTATCACGATGGGAAATGTGAGGTAGCTGCTATTG AGGACGGGAGGTTGATGTCTGATGCTGAAACTGGAGAATTCTGGGGATTTTTTGGTGGCTTTGCTCCACTTCCAAGAAAA ACTGTCTCTGAAGATGATAAAACTGTGGAAGCTTCTTCACCTAAGCTTCTCCGCATCACCAAAGGGCAGACAGAACCTGT TGATGCTGATCCTTTGACAAGAGAGTTGTTAGACACAAATCATTGCTACATTTTAGATTGTGGTATAGAAGTATTTGTGT GGACGGGAAGGAATACCTCTCTGGATGATCGAAAAACTGGCAGTACAGCTGTTGAAGAGTTGGTTCGTGGCCCCGACCGA CCAAAAGCTCACGTTATCCGTGTTATTGAAGGATTTGAAACAGTTGTTTTTCGATCGAAGTTTGATTCATGGCCTCAAAC AAATGATGTAACTGTATCTGAGGATGGTAGAGGCAAAGTTGCTGCACTCTTAAAGCGCCAAGGATTTAATGTTAAGGGCC TTCTAAAGGCTGCTCCTGCAAAAGAAGAACCTCAGCCATATATTGATTGCACTGGAAATCTTCAGGTTTGGCGTATAAAT GGCCAGGAAAAGACTCTCATACCATCTGCCGAACAGTCCAAGTTTTATAGTGGAGATTGTTATATCTTTCAATACTCATA TCCAGGCGAAGATAAAGAGGAGATCCTCATTGGTACTTGGTTCGGGAAGCAGAGTGTTGAGGAGGAGAGAACTGCAGCAA TATCACTGGCAAGCAAGATGGTTGAAGCTTTGAAGTCTCAGGCAGCACAGGCTCGTATCTTCGAAGGAAACGAACCCATT CAGTTTTTTTCGATCTTTCAGAGCTTTGTCGTGTTCAAGGGTGGGGTTAGTTCTGGGTATAAGAATTACATTGCGGAGAA CGGAGTAGCTGATGAGACATATTCAGAAGATGGGGTTGCACTATTTCGCGTTCAAGGTTCTGGACCTGAGAACATGCAGG CTATTCAAGTTGCACCGGTGGCTTCATCATTAAACTCTTGTTACTGTTACATATTACATAGCGGTTCCACAGTCTTTACA TGGTCCGGGAACCTTACTACGGCAGATGACCATGAGCTTGTAGAGAGACAGCTAGATATAGTAAAGCCAAATCTTCAGTC AAAACCACAGAAAGAGGGCACAGAAACTGATCAATTCTGGGAGTTGCTTGGAGGCAAACTTGAATTCCCTGGACAGAAAA TTACAAGGGATGCAGAAAGTGATCCTCATCTATTTTCATGCTCTTTCTCAAAAGGCAATCTTAAGGTGTCAGAGATATAC AACTTTTCCCAGGATGATCTGATGACTGAAGATATATTCATCCTAGATTGCCATTCAGACGTATTTGTTTGGATCGGGCA ACAGGTTGAATCTAAGAGTAAAACTCAAGCTTTGACCATTGCAGAGAAATTTATCGAGCAAGATGTTCTCCTTGAAAAGT TATCTCGTGATGCTCCAATATTTATTGTAATGGAAGGGTTTGAACCATCTTTCTTCACACGTTTCTTCACCTGGGACTCC GCCAAATCGGCTATGCATGGAAACTCATTTCAGAGGAAGTATTCGATCATGAAAAATGGAGTTGCTCCAACCCCAGATAA GCCCAAGAGGAGACCTCCAGCATCATATGGTGGAAGATCAAGTGTTCCAGACAAATCACAGCGATCCAGAAGCATGTCTT TTAGTCCAGACAGAGTCCGTGTTAGAGGCAGGTCTCCAGCTTTTAATGCACTTGCTGCTACATTTGAGAGCCCTAATGCC AGAAATCTCTCTACTCCGCCTCCAATGGTTAGAAAGATCTATCCAAAGTCCGTTACCCCTGATTCGGCAAAGCTGGATGC AGCAAAGTTGGCTTCAAGATCAGCGGCCATAGCAGCTCTCACAGCTTCATTTGAGCAACCAGCACCACCATCACCAGCAA GTGCTCCATCCAGAATTCCTAAGCCTAAACCGAGCCCTGAGACTCCAAAATCAGAACCAACCTCCAATTCAATGAGTAGT AGAATAGAAGCCCTAACTATTCAGGAAGATGTGAAAGAGGATGAAGCTGAGGACGAGGAAGGACTTCCTATATACCCATA TGAACGTCTGAAAGTGTTTTCAACAGATCCTGTTACAGATATTGATGTAACCAAGCGAGAGACATATCTCTCTTCAGAAG AGTTCAGGGAGAAATTCGGCATGGCAAAGGATGCTTTCTATAAGTTACCGAAATGGAAGCAGAACAAGCTTAAAATGGCA CTTCAATTGTTTTGA |