| Microexon ID | Ps_NC_039360.1:211712046-211712056:+ |
| Species | Papaver somniferum | Coordinates | NC_039360.1:211712046..211712056 |
| Microexon Cluster ID | MEP27 |
| Size | 11 |
| Phase | 1 |
| Pfam Domain Motif | Gelsolin |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 49,11,48 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | MRRGADRYTGWMAGWGATCCYCAYYTGTTYDCWTKYWCWTTYWMTAAAGGRAADYTKRAGGTKRMRGARRTHTACAAYTTYWCYCARGATGAYYTGWTGACWGARGAT |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 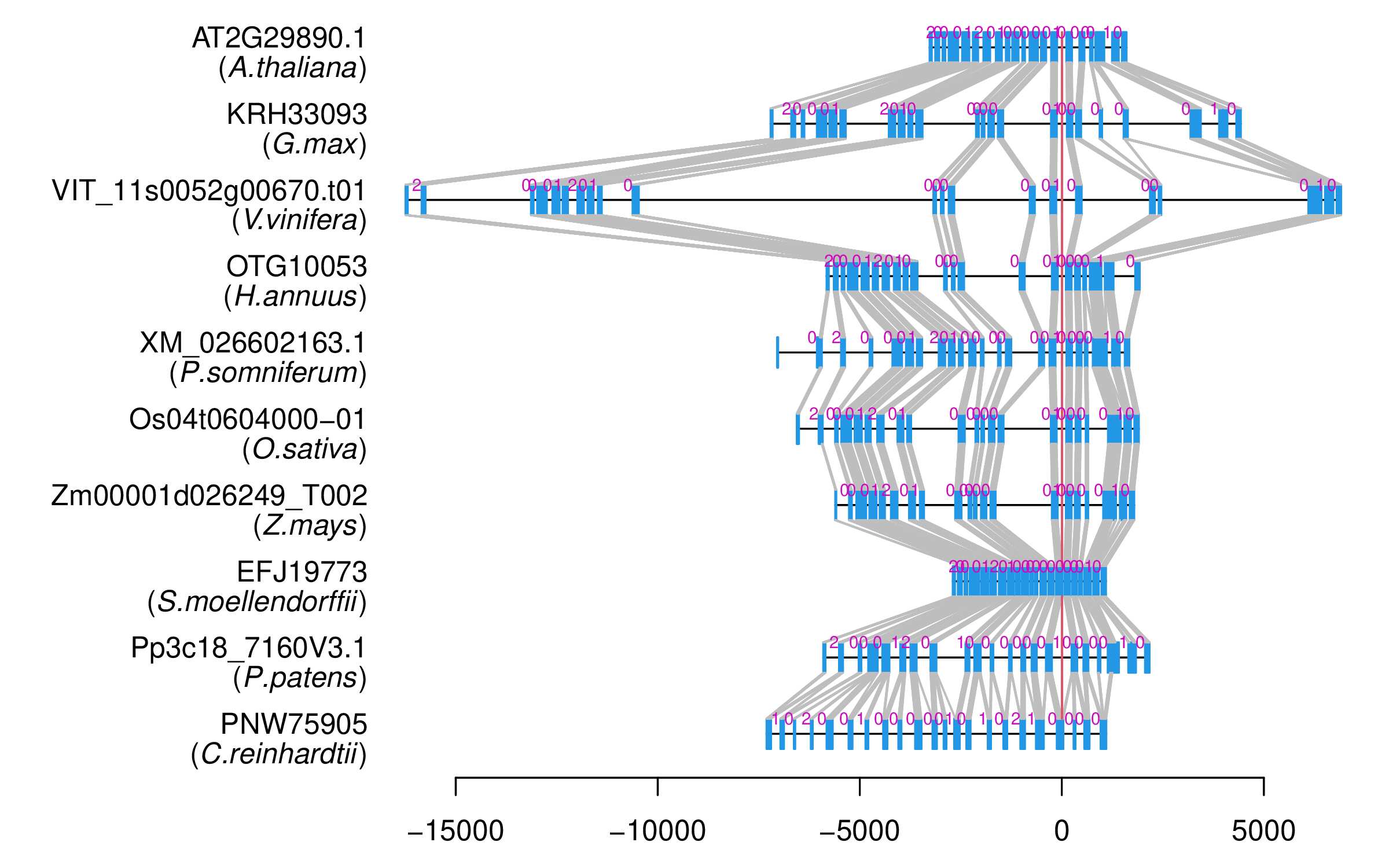 |
| Microexon DNA seq | GCAATCTTAAG |
| Microexon Amino Acid seq | GNLK |
| Microexon-tag DNA Seq | AGGGATGCAGAAAGTGATCCTCATCTATTTTCATGCTCTTTCTCAAAAGGCAATCTTAAGGTGTCAGAGATATACAACTTTTCCCAGGATGATCTGATGACTGAAGAT |
| Microexon-tag Amino Acid Seq | RDAESDPHLFSCSFSKGNLKVSEIYNFSQDDLMTED |
| Microexon-tag spanning region | 211711842-211712207 |
| Microexon-tag prediction score | 0.9687 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026602163.1x |
| Reference Transcript ID | XM_026602163.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026602163.1 |
| Protein ID | XP_026457948.1 |
| Gene ID | LOC113358565 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026457948.1 MKEFVFPRKVTSGSLAEARKAGNNSFDQKNNSMAVSMRDLDPAFQGAGQKAGTEIWRIENFRPVPVPTSSHGKFFTGDSY IILKTTALKSGAFRHDIHYWQGKDTSQDEAGTAAMKTVELDAALGGRAVQYREVQGHETAQFLSYFKPCIIPQAGGASSG FKHVQPEEHETRLYVCKGKHVVHVKEVAFARSTLNHDDIFILDTKSKIFQFNGSNSSIQERAKALEVVQHIKDTYHDGKC EVAAIEDGRLMSDAETGEFWGFFGGFAPLPRKTVSEDDKTVEASTPKLLRITKGQTEPVDADPLTRELLDTNHCYILDCG IEVFVWTGRNTSLDDRKTGSTAVEELVRGPDRPKAHVIRVIEGFETVVFRSKFDSWPQTNDVTVSEDGRGKVAALLKRQG FNVKGLLKAAPAKEEPQPYIDCTGNLQVWRINGQEKTLIPSAEQSKFYSGDCYIFQYSYPGEDKEEILIGTWFGKQSVEE ERTAAISLASKMVEALKSQAAQARIFEGNEPIQFFSIFQSFVVFKGGVSSGYKNYISENGVADETYSEDGVALFRVQGSG PENMQAIQVAPVASSLNSCYCYILHSGSTVFTWSGNLTTADDHELVERQLDIVKPNLQSKPQKEGTETDQFWELLGGKLE FPGQKITRDAESDPHLFSCSFSKGNLKVSEIYNFSQDDLMTEDIFILDCHSDIFVWIGQQVESKSKTQALTIAEKFIEQD VLLEKLSRDVPIFIVMEGFEPSFFTRFFTWDSAKSAMHGNSFQRKYSIMKNGVAPTPDKPKRRPPASYGGRSSVPDKSQR SRSMSFSPDRVRVRGRSPAFNALAATFESPNARNLSTPPPMVRKIYPKSVTPDSAKLDAAKLASRSAAIAALTASFEQPA PPSPASAPSRIPKPKPSPETPKSEPTSNSMSSRIEALTIQEDVKEDEAEDEEGLPIYPYERLKVFSTDPVTDIDVTKRET YLSSEEFREKFGMAKDAFYKLPKWKQNKLKMALQLF* |
| CDS seq | >XM_026602163.1 ATGAAGGAATTTGTTTTTCCTCGGAAGGTTACCTCTGGTTCCCTCGCCGAGGCAAGGAAGGCAGGAAATAATTCATTTGA TCAAAAGAACAACAGTATGGCTGTTTCTATGAGGGATTTAGATCCAGCTTTCCAGGGAGCTGGGCAAAAAGCTGGAACGG AGATCTGGCGCATTGAGAACTTCCGCCCCGTTCCTGTTCCCACATCGTCCCATGGGAAGTTCTTCACAGGAGATTCATAC ATTATTCTGAAGACAACTGCCTTGAAAAGTGGTGCATTTCGGCATGATATCCATTATTGGCAAGGGAAAGATACGAGTCA GGACGAAGCTGGTACTGCAGCCATGAAGACAGTTGAACTAGATGCTGCCCTTGGAGGACGTGCTGTCCAGTATCGGGAGG TGCAGGGCCATGAAACCGCTCAATTTCTATCATATTTTAAACCATGTATCATCCCCCAAGCAGGTGGTGCTTCATCTGGG TTCAAGCACGTTCAGCCCGAGGAACATGAAACCCGCCTATATGTTTGCAAAGGAAAGCATGTTGTCCACGTTAAAGAGGT TGCTTTTGCAAGATCAACACTCAATCACGATGACATTTTTATTTTAGACACCAAGTCTAAAATCTTTCAATTTAATGGTT CTAACTCATCCATTCAAGAGAGGGCTAAAGCCTTAGAAGTTGTCCAGCACATTAAAGATACTTATCACGATGGGAAATGT GAGGTAGCTGCTATTGAGGACGGGAGGTTGATGTCTGATGCTGAAACTGGAGAATTCTGGGGATTTTTTGGTGGCTTTGC TCCACTTCCAAGAAAAACTGTCTCTGAAGACGATAAAACTGTGGAAGCTTCTACACCTAAGCTTCTCCGCATCACCAAAG GGCAGACAGAACCTGTTGATGCTGATCCTTTGACAAGAGAGTTGTTAGACACAAATCATTGCTACATTTTAGATTGTGGT ATAGAAGTATTTGTGTGGACGGGAAGGAATACTTCTCTCGATGATCGAAAAACTGGCAGTACAGCTGTTGAAGAGTTGGT TCGTGGCCCCGACCGACCAAAAGCTCATGTTATCCGTGTTATTGAAGGGTTTGAAACAGTTGTATTTCGATCGAAGTTTG ATTCATGGCCTCAAACAAATGATGTAACTGTATCTGAGGATGGTAGAGGCAAAGTTGCTGCACTCTTAAAGCGCCAAGGA TTTAATGTTAAGGGCCTTCTAAAGGCTGCTCCTGCAAAAGAAGAACCTCAGCCATATATTGATTGCACTGGAAATCTTCA GGTTTGGCGTATAAATGGCCAGGAAAAGACTCTCATACCATCTGCCGAACAGTCCAAGTTTTATAGTGGAGATTGCTATA TCTTTCAATACTCATATCCAGGCGAAGATAAAGAGGAGATCCTCATTGGTACTTGGTTCGGGAAGCAGAGTGTTGAGGAG GAGAGAACTGCAGCAATATCACTGGCAAGCAAGATGGTTGAAGCTTTGAAGTCTCAGGCAGCACAGGCTCGTATCTTCGA AGGAAACGAACCCATCCAGTTTTTTTCGATCTTTCAGAGCTTTGTCGTGTTCAAGGGTGGGGTTAGTTCTGGGTATAAGA ATTACATTTCGGAGAACGGAGTAGCTGATGAGACATATTCAGAAGATGGGGTTGCATTATTTCGCGTTCAAGGTTCTGGA CCTGAGAACATGCAGGCTATTCAAGTTGCACCGGTGGCTTCATCATTAAATTCTTGTTACTGTTACATATTACATAGCGG TTCCACAGTCTTTACATGGTCCGGGAACCTTACTACGGCAGATGACCATGAGCTTGTAGAGAGACAGCTAGATATAGTAA AGCCAAATCTTCAGTCCAAACCACAGAAAGAGGGCACAGAAACTGATCAATTCTGGGAGTTGCTTGGAGGCAAACTTGAA TTCCCTGGACAGAAAATTACAAGGGATGCAGAAAGTGATCCTCATCTATTTTCATGCTCTTTCTCAAAAGGCAATCTTAA GGTGTCAGAGATATACAACTTTTCCCAGGATGATCTGATGACTGAAGATATATTCATCCTAGATTGCCATTCAGACATAT TTGTTTGGATCGGGCAACAGGTTGAATCTAAGAGTAAAACTCAAGCTTTGACCATTGCAGAGAAATTTATCGAGCAAGAT GTTCTCCTTGAAAAGTTATCTCGTGATGTTCCAATATTTATTGTAATGGAAGGGTTTGAACCATCTTTCTTCACACGTTT CTTCACCTGGGACTCTGCCAAATCGGCCATGCATGGAAACTCATTTCAGAGGAAGTATTCGATCATGAAAAATGGAGTTG CTCCAACCCCAGATAAGCCCAAGAGGAGACCTCCAGCATCATATGGTGGAAGATCAAGTGTTCCAGACAAATCACAGCGA TCCAGAAGCATGTCTTTTAGTCCAGACAGAGTCCGTGTTAGAGGCAGGTCTCCAGCTTTTAATGCACTTGCTGCTACATT TGAGAGCCCTAATGCCAGAAATCTCTCTACTCCGCCTCCAATGGTTAGAAAGATCTATCCAAAGTCCGTTACCCCTGATT CGGCAAAACTGGATGCAGCAAAGTTGGCTTCAAGATCAGCGGCCATAGCAGCTCTCACAGCTTCATTTGAGCAACCAGCA CCACCATCACCAGCAAGTGCTCCATCCAGAATTCCTAAGCCTAAACCGAGCCCTGAGACGCCAAAATCAGAACCAACCTC CAATTCAATGAGTAGTAGAATAGAAGCCCTAACTATTCAGGAAGATGTGAAAGAGGATGAAGCTGAGGACGAGGAAGGAC TTCCTATATACCCATATGAACGTCTGAAAGTGTTTTCAACCGATCCTGTTACAGATATTGATGTAACCAAGCGAGAGACA TATCTCTCTTCAGAAGAGTTCAGGGAGAAATTCGGGATGGCAAAGGATGCTTTCTATAAGTTACCGAAATGGAAGCAGAA CAAGCTTAAAATGGCACTTCAATTGTTTTGA |
| Microexon DNA seq | GCAATCTTAAG |
| Microexon Amino Acid seq | GNLK |
| Microexon-tag DNA Seq | AGGGATGCAGAAAGTGATCCTCATCTATTTTCATGCTCTTTCTCAAAAGGCAATCTTAAGGTGTCAGAGATATACAACTTTTCCCAGGATGATCTGATGACTGAAGAT |
| Microexon-tag Amino Acid seq | RDAESDPHLFSCSFSKGNLKVSEIYNFSQDDLMTED |
| Transcript ID | XM_026602164.1 |
| Gene ID | Ps.21540 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026602164.1 MAVSMRDLDPAFQGAGQKAGTEIWRIENFRPVPVPTSSHGKFFTGDSYIILKTTALKSGAFRHDIHYWQGKDTSQDEAGT AAMKTVELDAALGGRAVQYREVQGHETAQFLSYFKPCIIPQAGGASSGFKHVQPEEHETRLYVCKGKHVVHVKEVAFARS TLNHDDIFILDTKSKIFQFNGSNSSIQERAKALEVVQHIKDTYHDGKCEVAAIEDGRLMSDAETGEFWGFFGGFAPLPRK TVSEDDKTVEASTPKLLRITKGQTEPVDADPLTRELLDTNHCYILDCGIEVFVWTGRNTSLDDRKTGSTAVEELVRGPDR PKAHVIRVIEGFETVVFRSKFDSWPQTNDVTVSEDGRGKVAALLKRQGFNVKGLLKAAPAKEEPQPYIDCTGNLQVWRIN GQEKTLIPSAEQSKFYSGDCYIFQYSYPGEDKEEILIGTWFGKQSVEEERTAAISLASKMVEALKSQAAQARIFEGNEPI QFFSIFQSFVVFKGGVSSGYKNYISENGVADETYSEDGVALFRVQGSGPENMQAIQVAPVASSLNSCYCYILHSGSTVFT WSGNLTTADDHELVERQLDIVKPNLQSKPQKEGTETDQFWELLGGKLEFPGQKITRDAESDPHLFSCSFSKGNLKVSEIY NFSQDDLMTEDIFILDCHSDIFVWIGQQVESKSKTQALTIAEKFIEQDVLLEKLSRDVPIFIVMEGFEPSFFTRFFTWDS AKSAMHGNSFQRKYSIMKNGVAPTPDKPKRRPPASYGGRSSVPDKSQRSRSMSFSPDRVRVRGRSPAFNALAATFESPNA RNLSTPPPMVRKIYPKSVTPDSAKLDAAKLASRSAAIAALTASFEQPAPPSPASAPSRIPKPKPSPETPKSEPTSNSMSS RIEALTIQEDVKEDEAEDEEGLPIYPYERLKVFSTDPVTDIDVTKRETYLSSEEFREKFGMAKDAFYKLPKWKQNKLKMA LQLF* |
| CDS seq | >XM_026602164.1 ATGGCTGTTTCTATGAGGGATTTAGATCCAGCTTTCCAGGGAGCTGGGCAAAAAGCTGGAACGGAGATCTGGCGCATTGA GAACTTCCGCCCCGTTCCTGTTCCCACATCGTCCCATGGGAAGTTCTTCACAGGAGATTCATACATTATTCTGAAGACAA CTGCCTTGAAAAGTGGTGCATTTCGGCATGATATCCATTATTGGCAAGGGAAAGATACGAGTCAGGACGAAGCTGGTACT GCAGCCATGAAGACAGTTGAACTAGATGCTGCCCTTGGAGGACGTGCTGTCCAGTATCGGGAGGTGCAGGGCCATGAAAC CGCTCAATTTCTATCATATTTTAAACCATGTATCATCCCCCAAGCAGGTGGTGCTTCATCTGGGTTCAAGCACGTTCAGC CCGAGGAACATGAAACCCGCCTATATGTTTGCAAAGGAAAGCATGTTGTCCACGTTAAAGAGGTTGCTTTTGCAAGATCA ACACTCAATCACGATGACATTTTTATTTTAGACACCAAGTCTAAAATCTTTCAATTTAATGGTTCTAACTCATCCATTCA AGAGAGGGCTAAAGCCTTAGAAGTTGTCCAGCACATTAAAGATACTTATCACGATGGGAAATGTGAGGTAGCTGCTATTG AGGACGGGAGGTTGATGTCTGATGCTGAAACTGGAGAATTCTGGGGATTTTTTGGTGGCTTTGCTCCACTTCCAAGAAAA ACTGTCTCTGAAGACGATAAAACTGTGGAAGCTTCTACACCTAAGCTTCTCCGCATCACCAAAGGGCAGACAGAACCTGT TGATGCTGATCCTTTGACAAGAGAGTTGTTAGACACAAATCATTGCTACATTTTAGATTGTGGTATAGAAGTATTTGTGT GGACGGGAAGGAATACTTCTCTCGATGATCGAAAAACTGGCAGTACAGCTGTTGAAGAGTTGGTTCGTGGCCCCGACCGA CCAAAAGCTCATGTTATCCGTGTTATTGAAGGGTTTGAAACAGTTGTATTTCGATCGAAGTTTGATTCATGGCCTCAAAC AAATGATGTAACTGTATCTGAGGATGGTAGAGGCAAAGTTGCTGCACTCTTAAAGCGCCAAGGATTTAATGTTAAGGGCC TTCTAAAGGCTGCTCCTGCAAAAGAAGAACCTCAGCCATATATTGATTGCACTGGAAATCTTCAGGTTTGGCGTATAAAT GGCCAGGAAAAGACTCTCATACCATCTGCCGAACAGTCCAAGTTTTATAGTGGAGATTGCTATATCTTTCAATACTCATA TCCAGGCGAAGATAAAGAGGAGATCCTCATTGGTACTTGGTTCGGGAAGCAGAGTGTTGAGGAGGAGAGAACTGCAGCAA TATCACTGGCAAGCAAGATGGTTGAAGCTTTGAAGTCTCAGGCAGCACAGGCTCGTATCTTCGAAGGAAACGAACCCATC CAGTTTTTTTCGATCTTTCAGAGCTTTGTCGTGTTCAAGGGTGGGGTTAGTTCTGGGTATAAGAATTACATTTCGGAGAA CGGAGTAGCTGATGAGACATATTCAGAAGATGGGGTTGCATTATTTCGCGTTCAAGGTTCTGGACCTGAGAACATGCAGG CTATTCAAGTTGCACCGGTGGCTTCATCATTAAATTCTTGTTACTGTTACATATTACATAGCGGTTCCACAGTCTTTACA TGGTCCGGGAACCTTACTACGGCAGATGACCATGAGCTTGTAGAGAGACAGCTAGATATAGTAAAGCCAAATCTTCAGTC CAAACCACAGAAAGAGGGCACAGAAACTGATCAATTCTGGGAGTTGCTTGGAGGCAAACTTGAATTCCCTGGACAGAAAA TTACAAGGGATGCAGAAAGTGATCCTCATCTATTTTCATGCTCTTTCTCAAAAGGCAATCTTAAGGTGTCAGAGATATAC AACTTTTCCCAGGATGATCTGATGACTGAAGATATATTCATCCTAGATTGCCATTCAGACATATTTGTTTGGATCGGGCA ACAGGTTGAATCTAAGAGTAAAACTCAAGCTTTGACCATTGCAGAGAAATTTATCGAGCAAGATGTTCTCCTTGAAAAGT TATCTCGTGATGTTCCAATATTTATTGTAATGGAAGGGTTTGAACCATCTTTCTTCACACGTTTCTTCACCTGGGACTCT GCCAAATCGGCCATGCATGGAAACTCATTTCAGAGGAAGTATTCGATCATGAAAAATGGAGTTGCTCCAACCCCAGATAA GCCCAAGAGGAGACCTCCAGCATCATATGGTGGAAGATCAAGTGTTCCAGACAAATCACAGCGATCCAGAAGCATGTCTT TTAGTCCAGACAGAGTCCGTGTTAGAGGCAGGTCTCCAGCTTTTAATGCACTTGCTGCTACATTTGAGAGCCCTAATGCC AGAAATCTCTCTACTCCGCCTCCAATGGTTAGAAAGATCTATCCAAAGTCCGTTACCCCTGATTCGGCAAAACTGGATGC AGCAAAGTTGGCTTCAAGATCAGCGGCCATAGCAGCTCTCACAGCTTCATTTGAGCAACCAGCACCACCATCACCAGCAA GTGCTCCATCCAGAATTCCTAAGCCTAAACCGAGCCCTGAGACGCCAAAATCAGAACCAACCTCCAATTCAATGAGTAGT AGAATAGAAGCCCTAACTATTCAGGAAGATGTGAAAGAGGATGAAGCTGAGGACGAGGAAGGACTTCCTATATACCCATA TGAACGTCTGAAAGTGTTTTCAACCGATCCTGTTACAGATATTGATGTAACCAAGCGAGAGACATATCTCTCTTCAGAAG AGTTCAGGGAGAAATTCGGGATGGCAAAGGATGCTTTCTATAAGTTACCGAAATGGAAGCAGAACAAGCTTAAAATGGCA CTTCAATTGTTTTGA |