| Microexon ID | Pp_19:10494754-10494764:- |
| Species | Physcomitrium patens | Coordinates | 19:10494754..10494764 |
| Microexon Cluster ID | MEP27 |
| Size | 11 |
| Phase | 1 |
| Pfam Domain Motif | Gelsolin |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 49,11,48 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | MRRGADRYTGWMAGWGATCCYCAYYTGTTYDCWTKYWCWTTYWMTAAAGGRAADYTKRAGGTKRMRGARRTHTACAAYTTYWCYCARGATGAYYTGWTGACWGARGAT |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 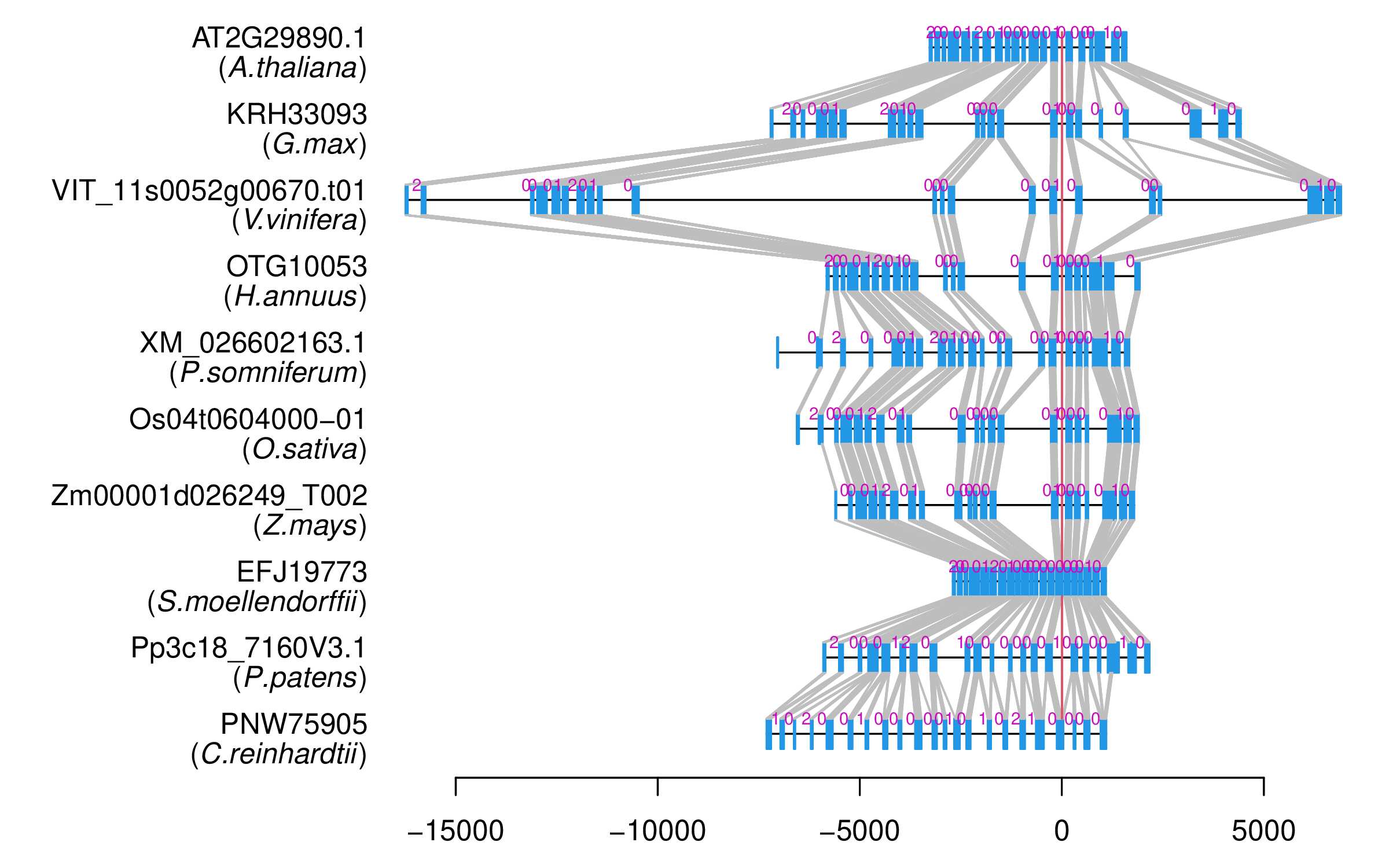 |
| Microexon DNA seq | AAAATTTGAAG |
| Microexon Amino Acid seq | ENLK |
| Microexon-tag DNA Seq | AAAGAGGGTCCGAAGGATCCAAGGCTGTTCGCTTGCAGTCTTTCACGAGAAAATTTGAAGGTGACTGAAGTGCACAATTTCACACAAGATGATCTTCTGAGTGACGAT |
| Microexon-tag Amino Acid Seq | KEGPKDPRLFACSLSRENLKVTEVHNFTQDDLLSDD |
| Microexon-tag spanning region | 10494491-10495110 |
| Microexon-tag prediction score | 0.8812 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | Pp3c19_16000V3.1x |
| Reference Transcript ID | Pp3c19_16000V3.1 |
| Gene ID | Pp3c19_16000 |
| Gene Name | NA |
| Transcript ID | Pp3c19_16000V3.1 |
| Protein ID | Pp3c19_16000V3.1 |
| Gene ID | Pp3c19_16000 |
| Gene Name | NA |
| Pfam domain motif | Gelsolin |
| Motif E-value | 5.3e-10 |
| Motif start | 620 |
| Motif end | 694 |
| Protein seq | >Pp3c19_16000V3.1 MAVSMKNVDVAFQGVGQKPGIDIWRIENFKPVPLLKEFHGKFYSGDSYIVLKTTALKTGGFHYDIHFWLGKDTSQDEAGT AAIKTVELDAALGGRAVQYRETQEHETELFLSYFKPCIVPMEGGIASGFKKVEVGKVEPRLFIVKGRRTVRVTQVPFARS SLNHDDVFVLDTESTIFQFNGENSSIQERGKALEVVQYIKDTDHDGKCEIVIIDDGTLGTEADTGQFWVLFGGFAPLSKK PVVADDASGLPKPKLLCIIERSLKEVEMSKDVLDSSKCYVLDCGNEIYTWAGRNTSLDARKAAISIVEDLITNLNRPKHI QITRIIEGFETLEFRSYFVKWPLNGQHTVSEEGRGKVAALLKQQGVNTKGILKGSPVKEELPPLPSLNGKLEVWRLVGGV KKEIDAGDVGRFYDHSCYIVLYTYQGEERKEEYLLCNWIGRHTSVEDKASGLRVMNEMSAALKGRAVQAYIAQGKEPIQF LALFKCMCILKEHVCPGHKDHSILLVRARCVGPQIVLAVQLEPVSASLNSSDCFLLQTNSKLYAWTGNLSTVENQKAVLR AAEVLKPGVVARPVKEGLEPPLFWSSLGSKRKYASHPKPKEGPKDPRLFACSLSRENLKVTEVHNFTQDDLLSDDIMILD CHNVIYEWVGQHASTEEKELNLDIAKKYIERAARLDGILQDVPIFMITEGNEPMFFTTFFSWDSSKVHGDSYTKRVAGIQ GRPVPQEKVQRRLTPSASAGTKSESTQRAAAMAALSSQLTSEGKLSKVAQTLVNQNPSSAPASPRFHRPSTANSQRAAAM AALSFMLGTKKAPGSAVSVDADWVAGSSPFAKVEATGDTESVTSSKTSEDGGDGGEEIAEFYSYDRLKSSSTNPPKINIK RKEAYLSPEDFEKLFGMSRTQFYEMPKWKQDQRKRNLLLF* |
| CDS seq | >Pp3c19_16000V3.1 ATGGCTGTGTCTATGAAGAATGTGGACGTCGCATTCCAAGGAGTTGGCCAGAAACCAGGAATTGACATATGGCGCATTGA GAATTTCAAACCAGTGCCCTTGCTCAAGGAATTTCATGGAAAATTTTATTCAGGAGATTCTTACATTGTGCTCAAGACGA CCGCACTTAAAACTGGAGGGTTCCACTACGATATTCACTTTTGGCTGGGAAAGGACACGAGCCAGGATGAGGCTGGTACA GCAGCAATTAAGACCGTTGAGCTGGATGCTGCGTTAGGTGGTCGCGCCGTTCAGTATAGAGAAACTCAGGAGCACGAAAC AGAACTCTTTCTATCTTATTTCAAACCATGTATTGTTCCTATGGAAGGCGGTATTGCTTCTGGATTCAAGAAAGTGGAAG TTGGGAAGGTTGAGCCTCGTTTATTCATTGTAAAAGGAAGACGCACTGTCAGAGTTACACAGGTGCCATTTGCTCGTTCC TCACTGAACCATGACGATGTTTTTGTTCTGGACACGGAATCAACAATATTCCAATTCAATGGAGAAAATTCCAGTATTCA AGAGAGGGGGAAAGCTCTTGAAGTGGTCCAGTATATCAAGGATACAGATCATGATGGAAAATGCGAAATTGTAATTATAG ACGATGGTACGCTCGGCACTGAGGCAGACACTGGGCAATTCTGGGTTCTGTTTGGAGGCTTTGCTCCTCTTTCAAAGAAA CCTGTTGTTGCAGATGATGCCTCTGGGTTACCCAAGCCTAAGTTGCTCTGTATCATAGAAAGGAGCTTGAAGGAAGTGGA AATGTCTAAGGATGTACTTGACAGCAGCAAGTGTTACGTGCTCGATTGCGGTAATGAGATCTACACTTGGGCAGGTCGCA ACACATCACTTGATGCTAGAAAGGCTGCAATTTCAATTGTAGAGGATTTAATCACTAACCTGAATAGGCCGAAGCACATC CAGATCACCCGGATCATTGAAGGATTCGAAACGCTCGAGTTTCGTTCGTACTTTGTTAAGTGGCCATTAAATGGACAACA CACCGTCTCTGAAGAAGGAAGAGGCAAAGTTGCAGCATTGTTGAAGCAGCAAGGTGTTAACACAAAAGGTATTCTCAAGG GTTCACCTGTGAAAGAAGAGCTCCCACCACTTCCAAGTTTGAATGGCAAGCTTGAGGTATGGAGGTTGGTCGGTGGTGTA AAAAAAGAAATTGATGCTGGAGATGTTGGAAGGTTCTATGACCACAGCTGCTATATTGTGCTTTACACTTATCAAGGAGA AGAGCGTAAAGAGGAATACCTTCTATGCAACTGGATTGGTCGGCACACCTCTGTGGAGGACAAGGCTTCGGGACTGAGGG TTATGAATGAAATGAGTGCAGCACTGAAAGGACGTGCAGTTCAGGCATACATTGCTCAAGGCAAGGAACCCATTCAGTTT TTGGCGCTGTTTAAATGCATGTGCATATTGAAGGAACATGTTTGTCCAGGTCACAAGGATCATTCAATATTGTTGGTGCG GGCGCGGTGTGTTGGTCCACAAATTGTCCTAGCTGTCCAGCTGGAGCCTGTGTCAGCTTCACTAAACTCCTCCGATTGCT TTCTACTTCAAACCAACTCGAAGTTGTATGCCTGGACAGGCAACCTGAGTACTGTTGAGAATCAGAAGGCTGTTTTGCGA GCAGCTGAAGTTCTGAAGCCTGGTGTTGTAGCAAGGCCTGTGAAAGAAGGATTAGAGCCTCCACTCTTTTGGAGTTCTCT GGGGAGTAAACGAAAATATGCAAGCCACCCCAAACCAAAAGAGGGTCCGAAGGATCCAAGGCTGTTCGCTTGCAGTCTTT CACGAGAAAATTTGAAGGTGACTGAAGTGCACAATTTCACACAAGATGATCTTCTGAGTGACGATATCATGATCCTGGAC TGTCACAATGTCATCTACGAGTGGGTTGGCCAGCATGCAAGCACAGAGGAGAAAGAGCTAAATTTAGATATTGCCAAGAA ATACATCGAACGTGCAGCAAGGTTGGATGGGATACTACAGGATGTTCCCATCTTCATGATCACGGAAGGCAATGAGCCAA TGTTTTTCACCACCTTCTTCTCATGGGATTCCAGCAAGGTCCATGGAGATTCCTACACAAAAAGAGTTGCAGGGATTCAA GGACGACCAGTTCCTCAAGAGAAAGTCCAAAGACGTCTTACTCCAAGTGCTTCAGCTGGTACCAAAAGTGAATCCACACA GAGGGCAGCAGCCATGGCAGCTCTCTCTTCACAGTTGACTTCAGAAGGGAAACTGTCGAAGGTTGCCCAAACACTAGTCA ATCAGAACCCATCCTCTGCTCCAGCGAGTCCAAGGTTTCATCGTCCATCAACTGCGAATTCTCAAAGAGCTGCTGCAATG GCGGCCCTATCCTTCATGCTTGGCACAAAAAAAGCTCCAGGCTCTGCAGTGTCAGTCGATGCTGATTGGGTTGCTGGGAG CTCACCATTCGCGAAAGTGGAAGCAACGGGAGATACAGAATCTGTAACAAGCTCAAAGACTTCTGAGGATGGAGGAGATG GAGGAGAGGAGATCGCTGAATTTTACAGCTATGATCGTTTGAAATCATCATCCACAAATCCTCCAAAAATAAATATAAAA AGAAAAGAGGCTTATTTATCCCCTGAAGATTTTGAGAAGCTCTTTGGAATGTCGAGAACCCAGTTTTACGAGATGCCCAA GTGGAAACAGGATCAACGCAAGCGCAATCTCCTACTCTTTTAG |
| Microexon DNA seq | AAAATTTGAAG |
| Microexon Amino Acid seq | ENLK |
| Microexon-tag DNA Seq | AAAGAGGGTCCGAAGGATCCAAGGCTGTTCGCTTGCAGTCTTTCACGAGAAAATTTGAAGGTGACTGAAGTGCACAATTTCACACAAGATGATCTTCTGAGTGACGAT |
| Microexon-tag Amino Acid seq | KEGPKDPRLFACSLSRENLKVTEVHNFTQDDLLSDD |
| Transcript ID | Pp.10539.1 |
| Gene ID | Pp.10539 |
| Gene Name | NA |
| Pfam domain motif | Gelsolin |
| Motif E-value | 5.3e-10 |
| Motif start | 620 |
| Motif end | 694 |
| Protein seq | >Pp.10539.1 MAVSMKNVDVAFQGVGQKPGIDIWRIENFKPVPLLKEFHGKFYSGDSYIVLKTTALKTGGFHYDIHFWLGKDTSQDEAGT AAIKTVELDAALGGRAVQYRETQEHETELFLSYFKPCIVPMEGGIASGFKKVEVGKVEPRLFIVKGRRTVRVTQVPFARS SLNHDDVFVLDTESTIFQFNGENSSIQERGKALEVVQYIKDTDHDGKCEIVIIDDGTLGTEADTGQFWVLFGGFAPLSKK PVVADDASGLPKPKLLCIIERSLKEVEMSKDVLDSSKCYVLDCGNEIYTWAGRNTSLDARKAAISIVEDLITNLNRPKHI QITRIIEGFETLEFRSYFVKWPLNGQHTVSEEGRGKVAALLKQQGVNTKGILKGSPVKEELPPLPSLNGKLEVWRLVGGV KKEIDAGDVGRFYDHSCYIVLYTYQGEERKEEYLLCNWIGRHTSVEDKASGLRVMNEMSAALKGRAVQAYIAQGKEPIQF LALFKCMCILKEHVCPGHKDHSILLVRARCVGPQIVLAVQLEPVSASLNSSDCFLLQTNSKLYAWTGNLSTVENQKAVLR AAEVLKPGVVARPVKEGLEPPLFWSSLGSKRKYASHPKPKEGPKDPRLFACSLSRENLKVTEVHNFTQDDLLSDDIMILD CHNVIYEWVGQHASTEEKELNLDIAKKYIERAARLDGILQDVPIFMITEGNEPMFFTTFFSWDSSKVNVHGDSYTKRVAG IQGRPVPQEKVQRRLTPSASAGTKSESTQRAAAMAALSSQLTSEGKLSKVAQTLVNQNPSSAPASPRFHRPSTANSQRAA AMAALSFMLGTKKAPGSAVSVDADWVAGSSPFAKVEATGDTESVTSSKTSEDGGDGGEEIAEFYSYDRLKSSSTNPPKIN IKRKEAYLSPEDFEKLFGMSRTQFYEMPKWKQDQRKRNLLLF* |
| CDS seq | >Pp.10539.1 ATGGCTGTGTCTATGAAGAATGTGGACGTCGCATTCCAAGGAGTTGGCCAGAAACCAGGAATTGACATATGGCGCATTGA GAATTTCAAACCAGTGCCCTTGCTCAAGGAATTTCATGGAAAATTTTATTCAGGAGATTCTTACATTGTGCTCAAGACGA CCGCACTTAAAACTGGAGGGTTCCACTACGATATTCACTTTTGGCTGGGAAAGGACACGAGCCAGGATGAGGCTGGTACA GCAGCAATTAAGACCGTTGAGCTGGATGCTGCGTTAGGTGGTCGCGCCGTTCAGTATAGAGAAACTCAGGAGCACGAAAC AGAACTCTTTCTATCTTATTTCAAACCATGTATTGTTCCTATGGAAGGCGGTATTGCTTCTGGATTCAAGAAAGTGGAAG TTGGGAAGGTTGAGCCTCGTTTATTCATTGTAAAAGGAAGACGCACTGTCAGAGTTACACAGGTGCCATTTGCTCGTTCC TCACTGAACCATGACGATGTTTTTGTTCTGGACACGGAATCAACAATATTCCAATTCAATGGAGAAAATTCCAGTATTCA AGAGAGGGGGAAAGCTCTTGAAGTGGTCCAGTATATCAAGGATACAGATCATGATGGAAAATGCGAAATTGTAATTATAG ACGATGGTACGCTCGGCACTGAGGCAGACACTGGGCAATTCTGGGTTCTGTTTGGAGGCTTTGCTCCTCTTTCAAAGAAA CCTGTTGTTGCAGATGATGCCTCTGGGTTACCCAAGCCTAAGTTGCTCTGTATCATAGAAAGGAGCTTGAAGGAAGTGGA AATGTCTAAGGATGTACTTGACAGCAGCAAGTGTTACGTGCTCGATTGCGGTAATGAGATCTACACTTGGGCAGGTCGCA ACACATCACTTGATGCTAGAAAGGCTGCAATTTCAATTGTAGAGGATTTAATCACTAACCTGAATAGGCCGAAGCACATC CAGATCACCCGGATCATTGAAGGATTCGAAACGCTCGAGTTTCGTTCGTACTTTGTTAAGTGGCCATTAAATGGACAACA CACCGTCTCTGAAGAAGGAAGAGGCAAAGTTGCAGCATTGTTGAAGCAGCAAGGTGTTAACACAAAAGGTATTCTCAAGG GTTCACCTGTGAAAGAAGAGCTCCCACCACTTCCAAGTTTGAATGGCAAGCTTGAGGTATGGAGGTTGGTCGGTGGTGTA AAAAAAGAAATTGATGCTGGAGATGTTGGAAGGTTCTATGACCACAGCTGCTATATTGTGCTTTACACTTATCAAGGAGA AGAGCGTAAAGAGGAATACCTTCTATGCAACTGGATTGGTCGGCACACCTCTGTGGAGGACAAGGCTTCGGGACTGAGGG TTATGAATGAAATGAGTGCAGCACTGAAAGGACGTGCAGTTCAGGCATACATTGCTCAAGGCAAGGAACCCATTCAGTTT TTGGCGCTGTTTAAATGCATGTGCATATTGAAGGAACATGTTTGTCCAGGTCACAAGGATCATTCAATATTGTTGGTGCG GGCGCGGTGTGTTGGTCCACAAATTGTCCTAGCTGTCCAGCTGGAGCCTGTGTCAGCTTCACTAAACTCCTCCGATTGCT TTCTACTTCAAACCAACTCGAAGTTGTATGCCTGGACAGGCAACCTGAGTACTGTTGAGAATCAGAAGGCTGTTTTGCGA GCAGCTGAAGTTCTGAAGCCTGGTGTTGTAGCAAGGCCTGTGAAAGAAGGATTAGAGCCTCCACTCTTTTGGAGTTCTCT GGGGAGTAAACGAAAATATGCAAGCCACCCCAAACCAAAAGAGGGTCCGAAGGATCCAAGGCTGTTCGCTTGCAGTCTTT CACGAGAAAATTTGAAGGTGACTGAAGTGCACAATTTCACACAAGATGATCTTCTGAGTGACGATATCATGATCCTGGAC TGTCACAATGTCATCTACGAGTGGGTTGGCCAGCATGCAAGCACAGAGGAGAAAGAGCTAAATTTAGATATTGCCAAGAA ATACATCGAACGTGCAGCAAGGTTGGATGGGATACTACAGGATGTTCCCATCTTCATGATCACGGAAGGCAATGAGCCAA TGTTTTTCACCACCTTCTTCTCATGGGATTCCAGCAAGGTCAATGTCCATGGAGATTCCTACACAAAAAGAGTTGCAGGG ATTCAAGGACGACCAGTTCCTCAAGAGAAAGTCCAAAGACGTCTTACTCCAAGTGCTTCAGCTGGTACCAAAAGTGAATC CACACAGAGGGCAGCAGCCATGGCAGCTCTCTCTTCACAGTTGACTTCAGAAGGGAAACTGTCGAAGGTTGCCCAAACAC TAGTCAATCAGAACCCATCCTCTGCTCCAGCGAGTCCAAGGTTTCATCGTCCATCAACTGCGAATTCTCAAAGAGCTGCT GCAATGGCGGCCCTATCCTTCATGCTTGGCACAAAAAAAGCTCCAGGCTCTGCAGTGTCAGTCGATGCTGATTGGGTTGC TGGGAGCTCACCATTCGCGAAAGTGGAAGCAACGGGAGATACAGAATCTGTAACAAGCTCAAAGACTTCTGAGGATGGAG GAGATGGAGGAGAGGAGATCGCTGAATTTTACAGCTATGATCGTTTGAAATCATCATCCACAAATCCTCCAAAAATAAAT ATAAAAAGAAAAGAGGCTTATTTATCCCCTGAAGATTTTGAGAAGCTCTTTGGAATGTCGAGAACCCAGTTTTACGAGAT GCCCAAGTGGAAACAGGATCAACGCAAGCGCAATCTCCTACTCTTTTAG |