| Microexon ID | Ha_10:30371224-30371234:+ |
| Species | Helianthus annuus | Coordinates | 10:30371224..30371234 |
| Microexon Cluster ID | MEP27 |
| Size | 11 |
| Phase | 1 |
| Pfam Domain Motif | Gelsolin |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 49,11,48 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | MRRGADRYTGWMAGWGATCCYCAYYTGTTYDCWTKYWCWTTYWMTAAAGGRAADYTKRAGGTKRMRGARRTHTACAAYTTYWCYCARGATGAYYTGWTGACWGARGAT |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 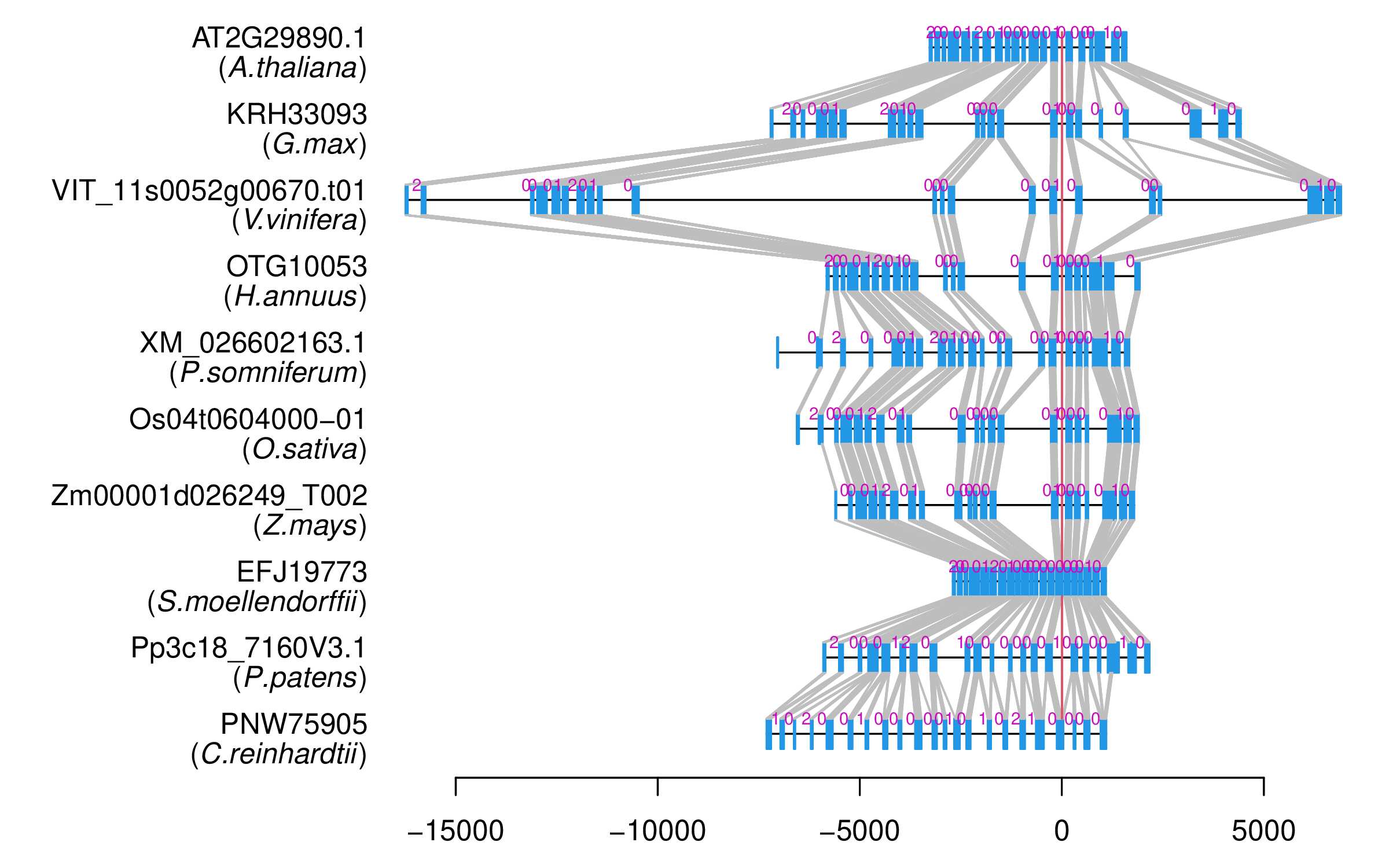 |
| Microexon DNA seq | GAAAATTTGAG |
| Microexon Amino Acid seq | GKFE |
| Microexon-tag DNA Seq | CCGGAAACCAGCAGAGATCCTCACTTGTTCGCATTCTCATTCAACAGAGGAAAATTTGAGATCGAGGAAATCTACAACTTTTCACAAGATGATCTGTTGACCGAGGAT |
| Microexon-tag Amino Acid Seq | PETSRDPHLFAFSFNRGKFEIEEIYNFSQDDLLTED |
| Microexon-tag spanning region | 30371078-30371373 |
| Microexon-tag prediction score | 0.9715 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | OTG10053x |
| Reference Transcript ID | OTG10053 |
| Gene ID | HannXRQ_Chr10g0283331 |
| Gene Name | VLN3 |
| Transcript ID | OTG10053 |
| Protein ID | OTG10053 |
| Gene ID | HannXRQ_Chr10g0283331 |
| Gene Name | VLN3 |
| Pfam domain motif | Gelsolin |
| Motif E-value | 2.9e-06 |
| Motif start | 636 |
| Motif end | 713 |
| Protein seq | >OTG10053 MAGSAKALEPAFQGVGQRVGTEIWRIENFQPVPLPKSNYGKFYSGDSYIVLQTTSGKGGAYFYDIHFWLGKDTSQDEAGT AAIKTVELDAILGGRAVQYREPQGYESDKFLSYFKPCIIPLEGGVASGFKETEEEEFQIRLYTCKGKRAVKLKQVPFSRS TLNHDDVFILDTKDKIFQFNGANSNIQERAKALEVIQFLKDKYHEGTCDVAIVDDGKLQAEGDSGEFWVIFGGFAPIGKK VASEDDTIPEKTPPKLYCIADGQVKDVDGELSKSLLENNKCYLLDCGSEVFVWVGRVTQVDERKAAMQAAEEFITSQNRP KATRVTRLIQGYETHSFKSNFESWPSGSAPSAPEEGRGKVAALLKQQGVGLKGLAKSSTVTEEVPPLLEENGKIEVWRIN GSAKTPVPKEDIGKFYSGDCYIVLYTYHSNEKKEDYYLCCWIGKDSIEEDQNMAARLATTMFNSLKGRPVQGRVYQGKEP PQFVAIFQPMVVLKGGLSSGYKNYVADKGLNDETYSSDGVALIQISGTSVHNNKAVQVEPVATSLNSYDCFLLQSGSSLF TWHGNQSTVEQHNIAAKIAEFLKPGANIKFAKEGTENSTFWFALGGKQGYTSKKTAPETSRDPHLFAFSFNRGKFEIEEI YNFSQDDLLTEDMLILDTHAEVFVWVGQSVDSKEKQSAFEIGQKYVELAASLDGLSPCVPLYRVSEGNEPNFFTTFFSWD PAKANVQGNSFQKKVLLLFGFGGGGNSGESQDKSNGNQGGPTQRASALAALNSAFKSSPTTKSSASPKVPSRGSQRAAAV AALSSVLTAEKKGSSDASPARPVRSTDASPARSIRSPPSETVSPAVAKSEEPSDSNEGSEVTTETSDPVQEANGDGSAPK PEENECESVNSQSTFSYEQLRAKSENPVKGIDFKRREAYLSAEEFEAVLGMTKEAFYKIPKWKQDMMKKKVDLF* |
| CDS seq | >OTG10053 ATGGCTGGCTCTGCTAAAGCTCTGGAACCAGCATTTCAAGGAGTCGGTCAGAGAGTAGGAACCGAGATATGGAGAATCGA AAACTTTCAGCCAGTACCATTGCCCAAATCTAATTATGGGAAATTCTATTCTGGTGATTCGTACATCGTATTGCAGACTA CTTCCGGTAAGGGCGGTGCATACTTTTACGACATACATTTTTGGCTGGGAAAAGATACTAGCCAGGATGAAGCTGGAACA GCAGCGATAAAAACAGTCGAACTTGATGCGATTCTCGGTGGGCGTGCAGTTCAATATAGGGAACCGCAGGGTTATGAGTC TGATAAGTTTTTGTCTTATTTCAAACCTTGTATTATACCCCTTGAGGGCGGTGTTGCTTCTGGGTTTAAGGAAACCGAAG AAGAAGAATTTCAAATACGATTATACACGTGCAAAGGAAAACGAGCTGTCAAGTTGAAGCAGGTCCCTTTTTCTCGATCC ACATTGAATCACGATGATGTCTTTATCTTGGATACTAAAGATAAGATCTTTCAATTCAATGGGGCAAACTCAAATATCCA AGAACGGGCTAAAGCGTTGGAAGTTATTCAGTTTTTAAAGGATAAATATCACGAGGGTACATGTGATGTCGCAATTGTTG ATGATGGGAAACTGCAAGCGGAGGGTGATTCCGGTGAATTTTGGGTGATCTTTGGTGGCTTTGCTCCTATTGGCAAAAAG GTTGCAAGCGAAGATGATACGATTCCCGAAAAGACTCCACCGAAACTTTATTGCATTGCGGACGGTCAGGTTAAGGATGT AGATGGCGAACTTTCGAAATCTTTACTGGAAAACAACAAATGCTATCTATTGGACTGCGGTTCCGAGGTGTTTGTTTGGG TCGGTCGAGTAACACAAGTGGATGAAAGAAAAGCTGCCATGCAGGCTGCTGAGGAGTTCATTACGAGCCAAAATCGGCCC AAGGCAACGCGTGTAACTCGGCTTATTCAAGGTTACGAAACACATTCATTTAAGTCAAACTTCGAGTCATGGCCATCGGG TTCAGCACCTTCTGCTCCTGAGGAAGGTAGAGGAAAAGTAGCAGCTCTATTGAAGCAACAAGGTGTTGGTCTCAAAGGGC TTGCAAAAAGTTCTACGGTTACTGAGGAAGTCCCACCTTTGCTTGAAGAAAATGGAAAAATCGAGGTGTGGCGGATTAAT GGAAGTGCTAAAACACCTGTACCAAAGGAGGATATCGGTAAATTTTACAGTGGAGATTGCTACATTGTTCTTTATACCTA CCATTCCAATGAAAAGAAAGAAGATTACTACCTGTGCTGTTGGATCGGTAAAGATAGCATCGAGGAGGACCAAAACATGG CTGCTCGGCTAGCTACAACAATGTTCAACTCACTAAAAGGAAGACCGGTTCAGGGTCGTGTATATCAAGGGAAAGAACCG CCACAGTTTGTTGCAATTTTCCAGCCAATGGTGGTGTTGAAGGGTGGATTGAGCTCTGGTTACAAGAACTACGTTGCAGA CAAGGGATTGAACGATGAAACCTATAGTTCAGATGGTGTAGCCCTCATTCAGATATCGGGTACTTCCGTGCATAATAATA AAGCCGTCCAAGTAGAACCGGTGGCAACTTCATTGAATTCTTATGACTGCTTTCTTCTTCAATCTGGTTCATCATTATTC ACCTGGCACGGAAACCAGAGTACGGTTGAGCAGCACAACATAGCTGCTAAAATTGCTGAATTTTTGAAGCCCGGTGCCAA CATCAAGTTCGCCAAAGAAGGAACCGAGAACTCAACTTTCTGGTTTGCACTCGGAGGGAAACAAGGTTACACCAGCAAAA AAACCGCACCGGAAACCAGCAGAGATCCTCACTTGTTCGCATTCTCATTCAACAGAGGAAAATTTGAGATCGAGGAAATC TACAACTTTTCACAAGATGATCTGTTGACCGAGGATATGTTAATATTAGATACACACGCTGAGGTGTTTGTTTGGGTCGG TCAGTCTGTAGACTCGAAGGAAAAGCAAAGTGCCTTTGAAATTGGACAGAAATACGTAGAGTTGGCTGCATCTCTAGATG GGCTATCCCCATGTGTGCCTTTATACCGAGTTTCGGAAGGAAACGAACCTAACTTCTTCACAACATTCTTCTCTTGGGAT CCTGCAAAAGCCAATGTTCAAGGGAACTCATTCCAAAAGAAGGTTTTGCTACTATTCGGGTTCGGTGGAGGCGGCAATTC CGGAGAGAGTCAGGATAAGTCAAACGGAAACCAGGGTGGGCCCACTCAAAGAGCCTCAGCGTTGGCGGCCTTGAACTCCG CTTTCAAATCATCACCGACCACTAAATCTTCAGCTTCTCCGAAAGTACCGAGTCGAGGTTCACAGAGAGCAGCTGCAGTT GCCGCTTTATCTTCGGTTCTCACTGCTGAGAAAAAGGGATCATCCGATGCTTCTCCAGCTCGGCCCGTTAGAAGCACTGA TGCTTCTCCAGCTCGGTCCATTAGAAGCCCACCGTCTGAAACTGTCTCACCTGCTGTAGCCAAAAGTGAAGAACCTTCTG ATAGTAATGAAGGTTCGGAAGTTACCACCGAGACATCTGACCCGGTTCAAGAGGCCAATGGAGACGGTTCAGCGCCGAAG CCAGAAGAAAATGAATGTGAGAGTGTAAACAGTCAAAGCACTTTCAGTTATGAACAACTCAGGGCTAAATCCGAGAATCC AGTTAAAGGAATCGACTTTAAAAGAAGAGAGGCTTATCTATCTGCTGAAGAATTCGAGGCGGTACTCGGGATGACAAAAG AGGCGTTCTACAAAATACCGAAATGGAAGCAAGACATGATGAAGAAGAAAGTTGATCTGTTCTAG |
| Microexon DNA seq | GAAAATTTGAG |
| Microexon Amino Acid seq | GKFE |
| Microexon-tag DNA Seq | CCGGAAACCAGCAGAGATCCTCACTTGTTCGCATTCTCATTCAACAGAGGAAAATTTGAGATCGAGGAAATCTACAACTTTTCACAAGATGATCTGTTGACCGAGGAT |
| Microexon-tag Amino Acid seq | PETSRDPHLFAFSFNRGKFEIEEIYNFSQDDLLTED |
| Transcript ID | Ha.3760.1 |
| Gene ID | Ha.3760 |
| Gene Name | VLN3 |
| Pfam domain motif | Gelsolin |
| Motif E-value | 2.9e-06 |
| Motif start | 636 |
| Motif end | 713 |
| Protein seq | >Ha.3760.1 MAGSAKALEPAFQGVGQRVGTEIWRIENFQPVPLPKSNYGKFYSGDSYIVLQTTSGKGGAYFYDIHFWLGKDTSQDEAGT AAIKTVELDAILGGRAVQYREPQGYESDKFLSYFKPCIIPLEGGVASGFKETEEEEFQIRLYTCKGKRAVKLKQVPFSRS TLNHDDVFILDTKDKIFQFNGANSNIQERAKALEVIQFLKDKYHEGTCDVAIVDDGKLQAEGDSGEFWVIFGGFAPIGKK VASEDDTIPEKTPPKLYCIADGQVKDVDGELSKSLLENNKCYLLDCGSEVFVWVGRVTQVDERKAAMQAAEEFITSQNRP KATRVTRLIQGYETHSFKSNFESWPSGSAPSAPEEGRGKVAALLKQQGVGLKGLAKSSTVTEEVPPLLEENGKIEVWRIN GSAKTPVPKEDIGKFYSGDCYIVLYTYHSNEKKEDYYLCCWIGKDSIEEDQNMAARLATTMFNSLKGRPVQGRVYQGKEP PQFVAIFQPMVVLKGGLSSGYKNYVADKGLNDETYSSDGVALIQISGTSVHNNKAVQVEPVATSLNSYDCFLLQSGSSLF TWHGNQSTVEQHNIAAKIAEFLKPGANIKFAKEGTENSTFWFALGGKQGYTSKKTAPETSRDPHLFAFSFNRGKFEIEEI YNFSQDDLLTEDMLILDTHAEVFVWVGQSVDSKEKQSAFEIGQKYVELAASLDGLSPCVPLYRVSEGNEPNFFTTFFSWD PAKANVQGNSFQKKVLLLFGFGGGGNSGESQDKSNGNQGGPTQRASALAALNSAFKSSPTTKSSASPKVPSRGSQRAAAV AALSSVLTAEKKGSSDASPARPVRSTDASPARSIRSPPSETVSPAVAKSEEPSDSNEGSEVTTETSDPVQEANGDGSAPK PEENECESVNSQSTFSYEQLRAKSENPVKGIDFKRREAYLSAEEFEAVLGMTKEAFYKIPKWKQDMMKKKVDLF* |
| CDS seq | >Ha.3760.1 ATGGCTGGCTCTGCTAAAGCTCTGGAACCAGCATTTCAAGGAGTCGGTCAGAGAGTAGGAACCGAGATATGGAGAATCGA AAACTTTCAGCCAGTACCATTGCCCAAATCTAATTATGGGAAATTCTATTCTGGTGATTCGTACATCGTATTGCAGACTA CTTCCGGTAAGGGCGGTGCATACTTTTACGACATACATTTTTGGCTGGGAAAAGATACTAGCCAGGATGAAGCTGGAACA GCAGCGATAAAAACAGTCGAACTTGATGCGATTCTCGGTGGGCGTGCAGTTCAATATAGGGAACCGCAGGGTTATGAGTC TGATAAGTTTTTGTCTTATTTCAAACCTTGTATTATACCCCTTGAGGGCGGTGTTGCTTCTGGGTTTAAGGAAACCGAAG AAGAAGAATTTCAAATACGATTATACACGTGCAAAGGAAAACGAGCTGTCAAGTTGAAGCAGGTCCCTTTTTCTCGATCC ACATTGAATCACGATGATGTCTTTATCTTGGATACTAAAGATAAGATCTTTCAATTCAATGGGGCAAACTCAAATATCCA AGAACGGGCTAAAGCGTTGGAAGTTATTCAGTTTTTAAAGGATAAATATCACGAGGGTACATGTGATGTCGCAATTGTTG ATGATGGGAAACTGCAAGCGGAGGGTGATTCCGGTGAATTTTGGGTGATCTTTGGTGGCTTTGCTCCTATTGGCAAAAAG GTTGCAAGCGAAGATGATACGATTCCCGAAAAGACTCCACCGAAACTTTATTGCATTGCGGACGGTCAGGTTAAGGATGT AGATGGCGAACTTTCGAAATCTTTACTGGAAAACAACAAATGCTATCTATTGGACTGCGGTTCCGAGGTGTTTGTTTGGG TCGGTCGAGTAACACAAGTGGATGAAAGAAAAGCTGCCATGCAGGCTGCTGAGGAGTTCATTACGAGCCAAAATCGGCCC AAGGCAACGCGTGTAACTCGGCTTATTCAAGGTTACGAAACACATTCATTTAAGTCAAACTTCGAGTCATGGCCATCGGG TTCAGCACCTTCTGCTCCTGAGGAAGGTAGAGGAAAAGTAGCAGCTCTATTGAAGCAACAAGGTGTTGGTCTCAAAGGGC TTGCAAAAAGTTCTACGGTTACTGAGGAAGTCCCACCTTTGCTTGAAGAAAATGGAAAAATCGAGGTGTGGCGGATTAAT GGAAGTGCTAAAACACCTGTACCAAAGGAGGATATCGGTAAATTTTACAGTGGAGATTGCTACATTGTTCTTTATACCTA CCATTCCAATGAAAAGAAAGAAGATTACTACCTGTGCTGTTGGATCGGTAAAGATAGCATCGAGGAGGACCAAAACATGG CTGCTCGGCTAGCTACAACAATGTTCAACTCACTAAAAGGAAGACCGGTTCAGGGTCGTGTATATCAAGGGAAAGAACCG CCACAGTTTGTTGCAATTTTCCAGCCAATGGTGGTGTTGAAGGGTGGATTGAGCTCTGGTTACAAGAACTACGTTGCAGA CAAGGGATTGAACGATGAAACCTATAGTTCAGATGGTGTAGCCCTCATTCAGATATCGGGTACTTCCGTGCATAATAATA AAGCCGTCCAAGTAGAACCGGTGGCAACTTCATTGAATTCTTATGACTGCTTTCTTCTTCAATCTGGTTCATCATTATTC ACCTGGCACGGAAACCAGAGTACGGTTGAGCAGCACAACATAGCTGCTAAAATTGCTGAATTTTTGAAGCCCGGTGCCAA CATCAAGTTCGCCAAAGAAGGAACCGAGAACTCAACTTTCTGGTTTGCACTCGGAGGGAAACAAGGTTACACCAGCAAAA AAACCGCACCGGAAACCAGCAGAGATCCTCACTTGTTCGCATTCTCATTCAACAGAGGAAAATTTGAGATCGAGGAAATC TACAACTTTTCACAAGATGATCTGTTGACCGAGGATATGTTAATATTAGATACACACGCTGAGGTGTTTGTTTGGGTCGG TCAGTCTGTAGACTCGAAGGAAAAGCAAAGTGCCTTTGAAATTGGACAGAAATACGTAGAGTTGGCTGCATCTCTAGATG GGCTATCCCCATGTGTGCCTTTATACCGAGTTTCGGAAGGAAACGAACCTAACTTCTTCACAACATTCTTCTCTTGGGAT CCTGCAAAAGCCAATGTTCAAGGGAACTCATTCCAAAAGAAGGTTTTGCTACTATTCGGGTTCGGTGGAGGCGGCAATTC CGGAGAGAGTCAGGATAAGTCAAACGGAAACCAGGGTGGGCCCACTCAAAGAGCCTCAGCGTTGGCGGCCTTGAACTCCG CTTTCAAATCATCACCGACCACTAAATCTTCAGCTTCTCCGAAAGTACCGAGTCGAGGTTCACAGAGAGCAGCTGCAGTT GCCGCTTTATCTTCGGTTCTCACTGCTGAGAAAAAGGGATCATCCGATGCTTCTCCAGCTCGGCCCGTTAGAAGCACTGA TGCTTCTCCAGCTCGGTCCATTAGAAGCCCACCGTCTGAAACTGTCTCACCTGCTGTAGCCAAAAGTGAAGAACCTTCTG ATAGTAATGAAGGTTCGGAAGTTACCACCGAGACATCTGACCCGGTTCAAGAGGCCAATGGAGACGGTTCAGCGCCGAAG CCAGAAGAAAATGAATGTGAGAGTGTAAACAGTCAAAGCACTTTCAGTTATGAACAACTCAGGGCTAAATCCGAGAATCC AGTTAAAGGAATCGACTTTAAAAGAAGAGAGGCTTATCTATCTGCTGAAGAATTCGAGGCGGTACTCGGGATGACAAAAG AGGCGTTCTACAAAATACCGAAATGGAAGCAAGACATGATGAAGAAGAAAGTTGATCTGTTCTAG |