| Microexon ID | Gm_3:35251129-35251139:- |
| Species | Glycine max | Coordinates | 3:35251129..35251139 |
| Microexon Cluster ID | MEP27 |
| Size | 11 |
| Phase | 1 |
| Pfam Domain Motif | Gelsolin |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 49,11,48 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | MRRGADRYTGWMAGWGATCCYCAYYTGTTYDCWTKYWCWTTYWMTAAAGGRAADYTKRAGGTKRMRGARRTHTACAAYTTYWCYCARGATGAYYTGWTGACWGARGAT |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 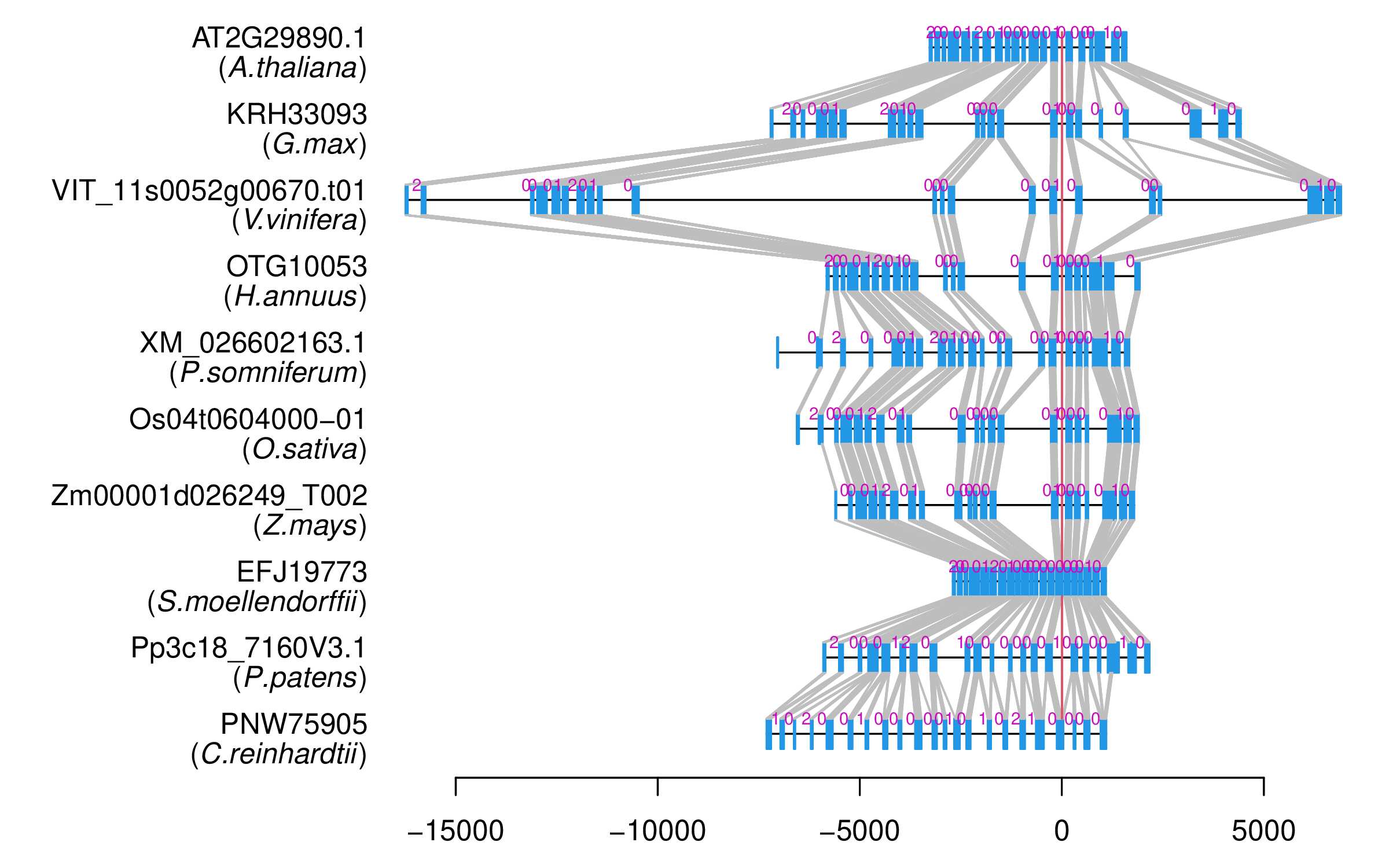 |
| Microexon DNA seq | GAAAGTTACAG |
| Microexon Amino Acid seq | GKLQ |
| Microexon-tag DNA Seq | AATGACATTGTCAGAGACCCCCATTTGTTCACTTTCTCTTTTAATAGAGGAAAGTTACAGGTAGAGGAGGTTTACAACTTTTCCCAAGATGATTTGTTAACAGAGGAT |
| Microexon-tag Amino Acid Seq | NDIVRDPHLFTFSFNRGKLQVEEVYNFSQDDLLTED |
| Microexon-tag spanning region | 35250976-35251317 |
| Microexon-tag prediction score | 0.9604 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | KRH66923x |
| Reference Transcript ID | KRH66923 |
| Gene ID | GLYMA_03G136500 |
| Gene Name | NA |
| Transcript ID | KRH66923 |
| Protein ID | KRH66923 |
| Gene ID | GLYMA_03G136500 |
| Gene Name | NA |
| Pfam domain motif | Gelsolin |
| Motif E-value | 2.1e-07 |
| Motif start | 638 |
| Motif end | 713 |
| Protein seq | >KRH66923 MSSATKVLDPAFQGVGQKVGTEIWRIEDFQPVPLPRPDYGKFYMGDSYIILQTTQGKGSAYLYDIHFWIGKDTSQDEAGT AAIKTVELDASLGGRAVQHREIQGHESDKFLSYFKPCIIPLEGGVASGFKKPEEEEFETRLYVCRGKRVVRIKQVPFARS SLNHDDVFILDTQNKIYQFNGANSNIQERAKALEVIQLLKEKYHEGKCDVAIVDDGKLDTESDSGEFWVLFGGFAPIGKK IISEDDIVPETIPAQLYSIADGEAKPVEGELSKSLLENYKCYLLDCGAEVFVWVGRVTQVEERKAACQAAEEFLTSQKRP KSTRITRIIQGYETHSFKSNFDSWPSGSATTGADEGRGKVAALLKQQGMGVKGVTKTTSVVEEIPPLLEGGGKMEVWQIN GSAKTPLPKEDIGKFYSGDCYIVLYTYHSSERKEDYYLCCWFGKDSTEEDQRMAIRLANTMFNSLKGRPVQGRIFDGKEP PQFIVLFHPMVVLKGGLSSGYKKLIADKGLPDETYTAESVAFIRISGTSTHNNKVVQVDAVAALLNSTECFVLQSGSAVF TWHGNQCSLEQQQLAAKVAEFLRPGVALKLAKEGTETSTFWFALGGKQSYNNKKVTNDIVRDPHLFTFSFNRGKLQVEEV YNFSQDDLLTEDILILDTHAEVFVWIGQCVDPKEKQNAFEIAQKYIDKAASLEGLSPHVPLYKVTEGNEPCFFTTYFSWD HTKAMVPGNSFQKKVTLLFGIGHPVEEKSNGSSQGGGPRQRAEALAALNNAFNSSPEATSSADKSNGLSRGGPRQRAEAL AALNSAFNSSSGTKVYTPRPSGRGQGSQRAAAVAALSSVLTAEKKKTSPETSPVASTSPVVENSNFDTKSESAPSEKEIV EEVTEVKETEVVALETGTNGDSEQPKQENVEDGGNDSENNNQNFFSYEQLKTKSGSVVSGIDLKRREAYLSDKEFQAVFG MAKDAFSKLPRWKQDMLKRKVDLF* |
| CDS seq | >KRH66923 ATGTCTAGTGCTACAAAAGTGTTGGATCCAGCATTCCAGGGAGTTGGTCAAAAAGTAGGGACTGAAATATGGAGGATTGA GGATTTTCAGCCAGTTCCATTGCCCAGACCTGATTATGGGAAATTCTACATGGGAGATTCTTACATCATCTTGCAGACAA CACAAGGCAAAGGAAGTGCTTATTTGTATGATATTCACTTCTGGATTGGAAAGGATACAAGTCAGGATGAGGCTGGAACA GCAGCCATTAAAACTGTTGAACTCGATGCGTCTCTTGGAGGACGTGCAGTGCAACACAGGGAAATTCAAGGGCATGAATC CGACAAGTTTTTGTCATACTTTAAGCCATGTATAATACCATTAGAGGGAGGTGTTGCATCGGGATTTAAAAAACCTGAAG AAGAGGAGTTTGAAACACGTTTGTATGTATGCAGAGGAAAAAGAGTTGTCAGAATAAAACAGGTTCCTTTTGCACGGTCT TCACTGAATCATGATGATGTATTCATCCTAGACACTCAGAATAAGATTTATCAATTCAATGGTGCAAACTCCAATATCCA GGAAAGAGCCAAGGCTCTGGAAGTTATTCAGTTGTTGAAGGAAAAGTATCATGAGGGAAAATGCGACGTTGCAATTGTTG ATGATGGAAAGCTGGATACTGAGTCAGACTCAGGTGAATTTTGGGTTCTCTTTGGTGGTTTTGCTCCCATTGGGAAGAAG ATAATTAGTGAGGATGATATTGTTCCAGAGACCATTCCTGCTCAACTCTATAGTATTGCTGATGGTGAGGCCAAGCCTGT GGAAGGTGAACTTTCAAAATCACTGCTGGAGAACTACAAATGCTATCTATTGGACTGTGGAGCTGAGGTATTTGTCTGGG TTGGCCGGGTAACACAAGTTGAAGAACGAAAAGCAGCATGTCAAGCAGCTGAGGAGTTTCTCACAAGTCAAAAAAGGCCG AAATCTACAAGGATTACCAGAATTATTCAAGGTTATGAGACACATTCGTTTAAGTCCAACTTTGATTCTTGGCCATCAGG ATCTGCTACTACTGGTGCTGATGAAGGAAGAGGAAAAGTTGCAGCTTTGCTTAAGCAACAAGGTATGGGTGTGAAAGGGG TGACAAAAACTACCTCAGTTGTTGAGGAAATTCCACCTCTACTTGAAGGAGGTGGAAAGATGGAGGTATGGCAAATCAAT GGAAGTGCTAAGACTCCATTACCTAAGGAGGATATCGGTAAATTTTATAGTGGAGATTGTTACATAGTACTGTACACTTA TCACTCTAGTGAGAGGAAGGAGGACTACTACTTGTGTTGTTGGTTTGGAAAAGACAGCACTGAGGAGGACCAAAGAATGG CTATTCGATTGGCTAACACAATGTTCAACTCATTAAAGGGTAGACCTGTTCAGGGTCGCATATTTGATGGTAAAGAGCCA CCACAGTTTATTGTTCTTTTCCATCCAATGGTGGTCCTCAAGGGAGGCTTGAGCTCTGGTTACAAAAAATTGATAGCAGA TAAAGGTTTGCCAGATGAGACATACACAGCAGAGAGTGTTGCATTTATTCGAATTTCTGGAACATCCACTCATAATAATA AAGTGGTGCAAGTAGATGCAGTGGCAGCATTGCTGAATTCTACCGAGTGTTTTGTCCTGCAATCTGGCTCAGCTGTTTTT ACATGGCATGGGAATCAATGTTCCCTTGAGCAGCAGCAGCTTGCTGCAAAAGTTGCTGAATTTTTAAGGCCAGGAGTTGC TTTAAAGCTTGCTAAAGAAGGAACAGAAACCTCAACTTTCTGGTTTGCACTTGGAGGGAAACAAAGTTACAACAACAAAA AAGTCACTAATGACATTGTCAGAGACCCCCATTTGTTCACTTTCTCTTTTAATAGAGGAAAGTTACAGGTAGAGGAGGTT TACAACTTTTCCCAAGATGATTTGTTAACAGAGGATATCCTGATCCTTGACACACACGCAGAAGTGTTTGTATGGATTGG TCAGTGTGTGGACCCAAAAGAAAAGCAAAATGCTTTTGAAATTGCCCAGAAATACATAGATAAGGCTGCATCTCTGGAGG GACTATCTCCTCATGTACCACTATACAAAGTAACAGAAGGGAATGAACCTTGCTTTTTCACAACATACTTTTCTTGGGAT CATACAAAAGCTATGGTTCCAGGAAACTCATTCCAGAAAAAGGTGACATTACTCTTTGGAATTGGCCATCCTGTAGAGGA AAAGTCTAATGGGTCAAGTCAAGGAGGGGGACCAAGACAAAGAGCAGAAGCTTTGGCTGCCTTAAATAATGCATTCAATT CATCTCCTGAGGCAACATCCAGTGCGGATAAGTCGAATGGGCTAAGTCGAGGAGGACCAAGACAAAGGGCTGAAGCCTTA GCAGCCTTAAACTCTGCATTTAATTCATCATCTGGAACCAAAGTTTATACTCCTAGGCCATCTGGAAGAGGTCAAGGATC ACAAAGAGCCGCCGCAGTAGCTGCTCTCTCTTCAGTTCTTACTGCTGAAAAGAAGAAAACTTCACCTGAAACTTCTCCTG TGGCTAGCACTAGTCCTGTAGTGGAGAATAGCAACTTTGATACTAAAAGTGAAAGTGCCCCTTCTGAAAAGGAAATTGTT GAAGAAGTTACAGAAGTCAAGGAGACAGAAGTTGTTGCCCTTGAAACTGGTACCAATGGGGATTCAGAACAACCAAAACA AGAAAATGTGGAGGATGGAGGAAATGACAGTGAAAATAATAATCAAAATTTCTTCAGTTATGAGCAGTTAAAGACCAAAT CTGGTAGTGTTGTGTCTGGAATTGATCTTAAACGGAGAGAGGCCTATCTGTCAGACAAAGAGTTCCAAGCTGTATTTGGA ATGGCCAAAGATGCATTCTCCAAGTTGCCAAGATGGAAGCAAGACATGCTGAAAAGAAAAGTGGATTTGTTCTAG |
| Microexon DNA seq | GAAAGTTACAG |
| Microexon Amino Acid seq | GKLQ |
| Microexon-tag DNA Seq | AATGACATTGTCAGAGACCCCCATTTGTTCACTTTCTCTTTTAATAGAGGAAAGTTACAGGTAGAGGAGGTTTACAACTTTTCCCAAGATGATTTGTTAACAGAGGAT |
| Microexon-tag Amino Acid seq | NDIVRDPHLFTFSFNRGKLQVEEVYNFSQDDLLTED |
| Transcript ID | Gm.36039.1 |
| Gene ID | Gm.36039 |
| Gene Name | NA |
| Pfam domain motif | Gelsolin |
| Motif E-value | 2.1e-07 |
| Motif start | 638 |
| Motif end | 713 |
| Protein seq | >Gm.36039.1 MSSATKVLDPAFQGVGQKVGTEIWRIEDFQPVPLPRPDYGKFYMGDSYIILQTTQGKGSAYLYDIHFWIGKDTSQDEAGT AAIKTVELDASLGGRAVQHREIQGHESDKFLSYFKPCIIPLEGGVASGFKKPEEEEFETRLYVCRGKRVVRIKQVPFARS SLNHDDVFILDTQNKIYQFNGANSNIQERAKALEVIQLLKEKYHEGKCDVAIVDDGKLDTESDSGEFWVLFGGFAPIGKK IISEDDIVPETIPAQLYSIADGEAKPVEGELSKSLLENYKCYLLDCGAEVFVWVGRVTQVEERKAACQAAEEFLTSQKRP KSTRITRIIQGYETHSFKSNFDSWPSGSATTGADEGRGKVAALLKQQGMGVKGVTKTTSVVEEIPPLLEGGGKMEVWQIN GSAKTPLPKEDIGKFYSGDCYIVLYTYHSSERKEDYYLCCWFGKDSTEEDQRMAIRLANTMFNSLKGRPVQGRIFDGKEP PQFIVLFHPMVVLKGGLSSGYKKLIADKGLPDETYTAESVAFIRISGTSTHNNKVVQVDAVAALLNSTECFVLQSGSAVF TWHGNQCSLEQQQLAAKVAEFLRPGVALKLAKEGTETSTFWFALGGKQSYNNKKVTNDIVRDPHLFTFSFNRGKLQVEEV YNFSQDDLLTEDILILDTHAEVFVWIGQCVDPKEKQNAFEIAQKYIDKAASLEGLSPHVPLYKVTEGNEPCFFTTYFSWD HTKAMVPGNSFQKKVTLLFGIGHPVEEKSNGSSQGGGPRQRAEALAALNNAFNSSPEATSSADKSNGLSRGGPRQRAEAL AALNSAFNSSSGTKVYTPRPSGRGQGSQRAAAVAALSSVLTAEKKKTSPETSPVASTSPVVENSNFDTKSESAPSEKEIV EEVTEVKETEVVALETGTNGDSEQPKQENVEDGGNDSENNNQNFFSYEQLKTKSGSVVSGIDLKRREAYLSDKEFQAVFG MAKDAFSKLPRWKQDMLKRKVDLF* |
| CDS seq | >Gm.36039.1 ATGTCTAGTGCTACAAAAGTGTTGGATCCAGCATTCCAGGGAGTTGGTCAAAAAGTAGGGACTGAAATATGGAGGATTGA GGATTTTCAGCCAGTTCCATTGCCCAGACCTGATTATGGGAAATTCTACATGGGAGATTCTTACATCATCTTGCAGACAA CACAAGGCAAAGGAAGTGCTTATTTGTATGATATTCACTTCTGGATTGGAAAGGATACAAGTCAGGATGAGGCTGGAACA GCAGCCATTAAAACTGTTGAACTCGATGCGTCTCTTGGAGGACGTGCAGTGCAACACAGGGAAATTCAAGGGCATGAATC CGACAAGTTTTTGTCATACTTTAAGCCATGTATAATACCATTAGAGGGAGGTGTTGCATCGGGATTTAAAAAACCTGAAG AAGAGGAGTTTGAAACACGTTTGTATGTATGCAGAGGAAAAAGAGTTGTCAGAATAAAACAGGTTCCTTTTGCACGGTCT TCACTGAATCATGATGATGTATTCATCCTAGACACTCAGAATAAGATTTATCAATTCAATGGTGCAAACTCCAATATCCA GGAAAGAGCCAAGGCTCTGGAAGTTATTCAGTTGTTGAAGGAAAAGTATCATGAGGGAAAATGCGACGTTGCAATTGTTG ATGATGGAAAGCTGGATACTGAGTCAGACTCAGGTGAATTTTGGGTTCTCTTTGGTGGTTTTGCTCCCATTGGGAAGAAG ATAATTAGTGAGGATGATATTGTTCCAGAGACCATTCCTGCTCAACTCTATAGTATTGCTGATGGTGAGGCCAAGCCTGT GGAAGGTGAACTTTCAAAATCACTGCTGGAGAACTACAAATGCTATCTATTGGACTGTGGAGCTGAGGTATTTGTCTGGG TTGGCCGGGTAACACAAGTTGAAGAACGAAAAGCAGCATGTCAAGCAGCTGAGGAGTTTCTCACAAGTCAAAAAAGGCCG AAATCTACAAGGATTACCAGAATTATTCAAGGTTATGAGACACATTCGTTTAAGTCCAACTTTGATTCTTGGCCATCAGG ATCTGCTACTACTGGTGCTGATGAAGGAAGAGGAAAAGTTGCAGCTTTGCTTAAGCAACAAGGTATGGGTGTGAAAGGGG TGACAAAAACTACCTCAGTTGTTGAGGAAATTCCACCTCTACTTGAAGGAGGTGGAAAGATGGAGGTATGGCAAATCAAT GGAAGTGCTAAGACTCCATTACCTAAGGAGGATATCGGTAAATTTTATAGTGGAGATTGTTACATAGTACTGTACACTTA TCACTCTAGTGAGAGGAAGGAGGACTACTACTTGTGTTGTTGGTTTGGAAAAGACAGCACTGAGGAGGACCAAAGAATGG CTATTCGATTGGCTAACACAATGTTCAACTCATTAAAGGGTAGACCTGTTCAGGGTCGCATATTTGATGGTAAAGAGCCA CCACAGTTTATTGTTCTTTTCCATCCAATGGTGGTCCTCAAGGGAGGCTTGAGCTCTGGTTACAAAAAATTGATAGCAGA TAAAGGTTTGCCAGATGAGACATACACAGCAGAGAGTGTTGCATTTATTCGAATTTCTGGAACATCCACTCATAATAATA AAGTGGTGCAAGTAGATGCAGTGGCAGCATTGCTGAATTCTACCGAGTGTTTTGTCCTGCAATCTGGCTCAGCTGTTTTT ACATGGCATGGGAATCAATGTTCCCTTGAGCAGCAGCAGCTTGCTGCAAAAGTTGCTGAATTTTTAAGGCCAGGAGTTGC TTTAAAGCTTGCTAAAGAAGGAACAGAAACCTCAACTTTCTGGTTTGCACTTGGAGGGAAACAAAGTTACAACAACAAAA AAGTCACTAATGACATTGTCAGAGACCCCCATTTGTTCACTTTCTCTTTTAATAGAGGAAAGTTACAGGTAGAGGAGGTT TACAACTTTTCCCAAGATGATTTGTTAACAGAGGATATCCTGATCCTTGACACACACGCAGAAGTGTTTGTATGGATTGG TCAGTGTGTGGACCCAAAAGAAAAGCAAAATGCTTTTGAAATTGCCCAGAAATACATAGATAAGGCTGCATCTCTGGAGG GACTATCTCCTCATGTACCACTATACAAAGTAACAGAAGGGAATGAACCTTGCTTTTTCACAACATACTTTTCTTGGGAT CATACAAAAGCTATGGTTCCAGGAAACTCATTCCAGAAAAAGGTGACATTACTCTTTGGAATTGGCCATCCTGTAGAGGA AAAGTCTAATGGGTCAAGTCAAGGAGGGGGACCAAGACAAAGAGCAGAAGCTTTGGCTGCCTTAAATAATGCATTCAATT CATCTCCTGAGGCAACATCCAGTGCGGATAAGTCGAATGGGCTAAGTCGAGGAGGACCAAGACAAAGGGCTGAAGCCTTA GCAGCCTTAAACTCTGCATTTAATTCATCATCTGGAACCAAAGTTTATACTCCTAGGCCATCTGGAAGAGGTCAAGGATC ACAAAGAGCCGCCGCAGTAGCTGCTCTCTCTTCAGTTCTTACTGCTGAAAAGAAGAAAACTTCACCTGAAACTTCTCCTG TGGCTAGCACTAGTCCTGTAGTGGAGAATAGCAACTTTGATACTAAAAGTGAAAGTGCCCCTTCTGAAAAGGAAATTGTT GAAGAAGTTACAGAAGTCAAGGAGACAGAAGTTGTTGCCCTTGAAACTGGTACCAATGGGGATTCAGAACAACCAAAACA AGAAAATGTGGAGGATGGAGGAAATGACAGTGAAAATAATAATCAAAATTTCTTCAGTTATGAGCAGTTAAAGACCAAAT CTGGTAGTGTTGTGTCTGGAATTGATCTTAAACGGAGAGAGGCCTATCTGTCAGACAAAGAGTTCCAAGCTGTATTTGGA ATGGCCAAAGATGCATTCTCCAAGTTGCCAAGATGGAAGCAAGACATGCTGAAAAGAAAAGTGGATTTGTTCTAG |