| Microexon ID | Ha_1:45066965-45066972:- |
| Species | Helianthus annuus | Coordinates | 1:45066965..45066972 |
| Microexon Cluster ID | MEP20 |
| Size | 8 |
| Phase | 2 |
| Pfam Domain Motif | VSP |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 16,34,8,50 |
| Microexon location in the Microexon-tag | 3 |
| Microexon-tag DNA Seq | TWTRTTCCKGGMARAGATSAAAATGGAARYTWYSYRCCHYTRMAGWYRAGHHMARRWGGWWTAKCWRGTGGWGYYATWGCTGGMATATCTRTWGSWGGAGTWRCHGGK |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 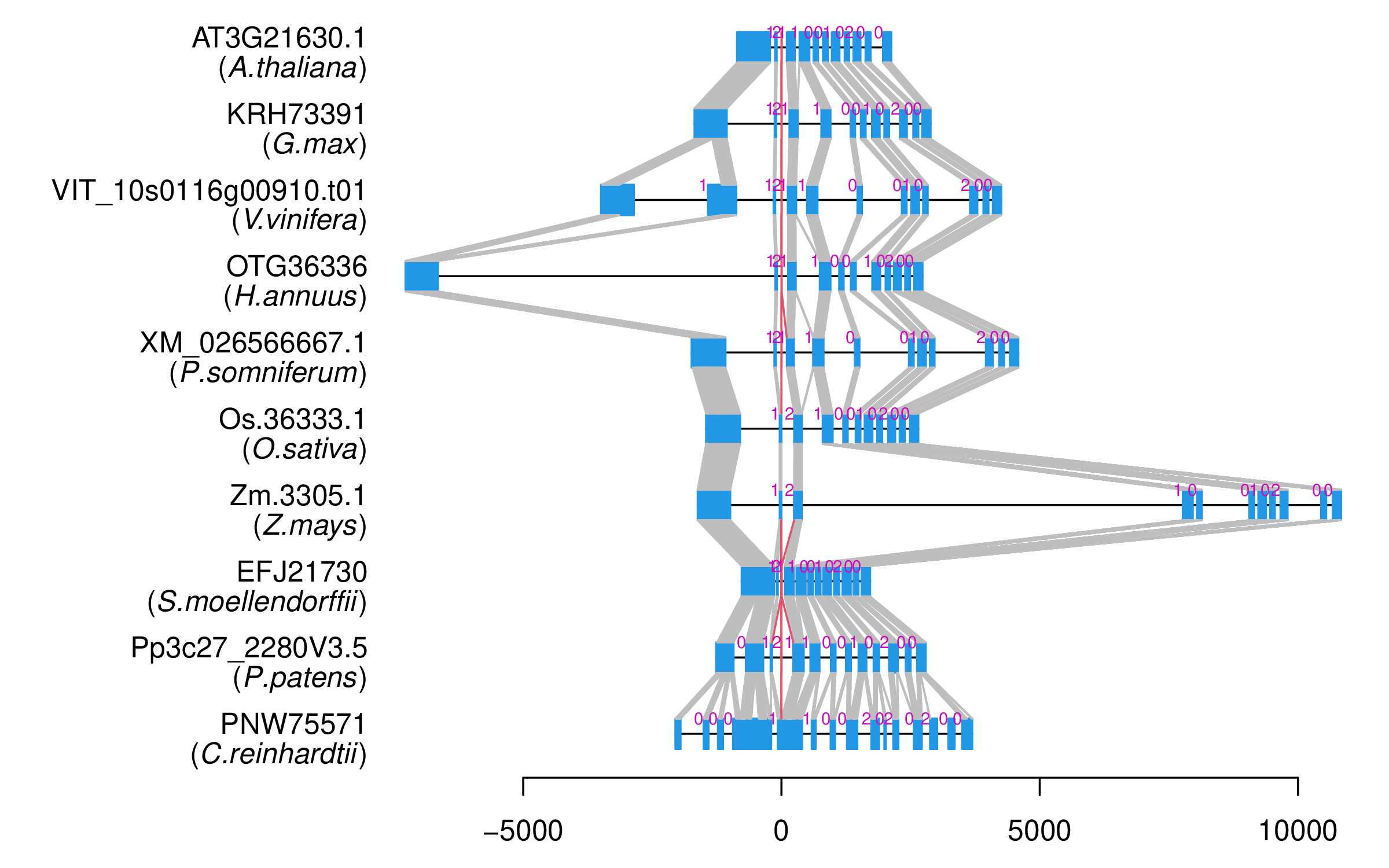 |
| Microexon DNA seq | CAATAGGG |
| Microexon Amino Acid seq | SNRG |
| Microexon-tag DNA Seq | TTTATTCCTGGAAGAGATCAAAATGGAACTTTTCCGCCATTAAAGATCAGCAATAGGGGGTTATCTGGTGGTGCCACTGCTGGTGTATCTGTTGGAGCAGTTGCAGGT |
| Microexon-tag Amino Acid Seq | FIPGRDQNGTFPPLKISNRGLSGGATAGVSVGAVAG |
| Microexon-tag spanning region | 45066792-45070211 |
| Microexon-tag prediction score | 0.9494 |
| Overlapped with the annotated transcript (%) | 85.19 |
| New Transcript ID | OTG36336x |
| Reference Transcript ID | OTG36336 |
| Gene ID | HannXRQ_Chr01g0006491 |
| Gene Name | NA |
| Transcript ID | OTG36336 |
| Protein ID | OTG36336 |
| Gene ID | HannXRQ_Chr01g0006491 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >OTG36336 MNNNISNTKRHILQLGLCVLFFIVKIESKCSNGCDLAFASYYVTQGSNLTYISNIFGQSIPMILKYNPQIPRSDTIESGT RINVPFSCLCLNGDFLGHTFIYHTQVGDTYSKVAKEVFANLTDEYWVQLVNIFDPAQIPDFADVNVTVNCTCGDKHVSKD YGLFATYPLQPGEDLWSLSKDSGVPMMLLERFNPGSNFSAGSGPVFVPAKDQNGTFPPLKISNRGLSGGATAGVSVGAVA GVLFFAICFYFVSYRRKRVGEGSLLLEDGPEHVHDVGLRRNMGGTTNSGTLTGGAHPGATGITVDKSVEFTYEELAMATD DFSITNKIGQGGFGTVYYGELRGEKAAIKKMEMQASKEFLAELKVLTHVHHLNLVRLIGYCVEGSLFLVYEFIGNGNLSQ HLRGSSGRESIPWATRVQIALDAARGLEYIHEHTVPVYIHRDIKSPNILIDEDFRAKVADFGLTKLTEVGSGSLQTRLVG TFGYMPPEYAQYGEVSPKVDVYAFGVVLFELVSAKEAIVKTNEFGNESKGLVGLFDEVLSLSDPSEGLRKLVDPRLGADY PLDSVRKVALLARACTHDNAQLRPSMRSIVVALMTLSSLTEDWDVGSFYENQDLAQLMSGR* |
| CDS seq | >OTG36336 ATGAACAACAATATTTCAAATACAAAGAGACATATACTACAATTGGGGCTTTGTGTTCTTTTCTTCATTGTCAAGATTGA ATCCAAGTGTAGCAATGGTTGTGATCTGGCCTTTGCATCATATTATGTCACACAAGGGTCAAATCTGACTTACATAAGCA ACATTTTTGGCCAATCAATCCCTATGATCCTTAAGTACAATCCACAAATCCCGAGAAGCGACACCATCGAAAGTGGGACC CGAATTAACGTTCCATTTTCTTGTCTATGTTTGAATGGTGATTTTTTAGGTCACACGTTTATATACCACACACAAGTTGG CGATACTTATAGTAAGGTTGCAAAAGAGGTATTTGCAAATCTTACCGATGAGTATTGGGTCCAACTGGTTAACATATTTG ACCCGGCTCAAATACCAGATTTTGCGGATGTAAATGTTACCGTGAATTGTACATGTGGCGACAAACACGTGTCGAAGGAT TACGGGTTGTTCGCAACATACCCTCTTCAACCCGGAGAAGATTTGTGGTCCTTAAGTAAAGATTCGGGTGTCCCAATGAT GTTGTTGGAGCGGTTCAACCCGGGATCCAATTTCAGTGCCGGGTCGGGACCAGTGTTTGTGCCGGCCAAAGATCAAAATG GAACTTTTCCGCCATTAAAGATCAGCAATAGGGGGTTATCTGGTGGTGCCACTGCTGGTGTATCTGTTGGAGCAGTTGCA GGTGTTCTTTTCTTTGCCATTTGCTTCTACTTTGTCTCCTATCGAAGGAAGAGGGTGGGCGAAGGATCACTGCTTCTTGA AGATGGACCCGAACATGTTCATGATGTAGGTTTACGTAGAAACATGGGAGGAACCACAAACTCGGGCACTCTAACTGGGG GTGCACATCCAGGGGCCACGGGTATAACCGTGGACAAGTCAGTGGAGTTCACATACGAGGAGCTTGCTATGGCTACAGAT GACTTTAGCATCACCAATAAGATTGGTCAAGGCGGCTTTGGTACCGTTTACTATGGAGAGCTCAGAGGCGAAAAAGCTGC AATAAAGAAGATGGAAATGCAAGCATCAAAAGAATTTCTTGCTGAATTAAAGGTGTTAACACATGTTCATCATTTGAACC TGGTACGGTTGATAGGATATTGTGTTGAAGGATCGTTGTTTTTGGTCTATGAGTTTATCGGGAATGGCAATTTGAGTCAA CATTTGCGCGGTTCATCGGGCAGAGAGTCAATTCCATGGGCTACAAGGGTTCAAATCGCCCTTGATGCGGCTAGAGGGCT TGAATACATTCATGAGCATACAGTTCCTGTCTATATACATCGCGATATCAAGTCTCCTAACATTTTAATCGATGAAGATT TCCGTGCAAAGGTTGCTGACTTTGGGCTGACAAAACTTACCGAAGTCGGGAGTGGTTCTTTACAAACCCGTTTAGTTGGC ACATTCGGCTACATGCCTCCCGAATATGCTCAGTATGGGGAGGTTTCTCCAAAGGTTGATGTATATGCTTTCGGGGTCGT ATTGTTTGAGCTAGTATCAGCGAAAGAAGCCATTGTCAAGACAAATGAATTTGGTAACGAGTCCAAAGGACTTGTTGGTT TGTTTGATGAGGTCCTAAGTTTGTCTGACCCAAGTGAAGGTTTACGCAAACTAGTCGACCCAAGGCTTGGGGCCGACTAC CCTCTCGACTCAGTGCGCAAGGTTGCACTGCTTGCTAGAGCTTGTACACATGATAATGCGCAGTTGAGGCCAAGCATGAG GTCTATTGTCGTTGCGCTAATGACACTTTCATCATTGACCGAGGATTGGGACGTTGGATCTTTCTACGAAAATCAAGATT TAGCTCAACTGATGTCAGGGAGGTAG |
| Microexon DNA seq | CAATAGGG |
| Microexon Amino Acid seq | SNRG |
| Microexon-tag DNA Seq | TTTGTGCCGGCCAAAGATCAAAATGGAACTTTTCCGCCATTAAAGATCAGCAATAGGGGGTTATCTGGTGGTGCCACTGCTGGTGTATCTGTTGGAGCAGTTGCAGGT |
| Microexon-tag Amino Acid seq | FVPAKDQNGTFPPLKISNRGLSGGATAGVSVGAVAG |
| Transcript ID | OTG36336 |
| Gene ID | Ha.702 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >OTG36336 MNNNISNTKRHILQLGLCVLFFIVKIESKCSNGCDLAFASYYVTQGSNLTYISNIFGQSIPMILKYNPQIPRSDTIESGT RINVPFSCLCLNGDFLGHTFIYHTQVGDTYSKVAKEVFANLTDEYWVQLVNIFDPAQIPDFADVNVTVNCTCGDKHVSKD YGLFATYPLQPGEDLWSLSKDSGVPMMLLERFNPGSNFSAGSGPVFVPAKDQNGTFPPLKISNRGLSGGATAGVSVGAVA GVLFFAICFYFVSYRRKRVGEGSLLLEDGPEHVHDVGLRRNMGGTTNSGTLTGGAHPGATGITVDKSVEFTYEELAMATD DFSITNKIGQGGFGTVYYGELRGEKAAIKKMEMQASKEFLAELKVLTHVHHLNLVRLIGYCVEGSLFLVYEFIGNGNLSQ HLRGSSGRESIPWATRVQIALDAARGLEYIHEHTVPVYIHRDIKSPNILIDEDFRAKVADFGLTKLTEVGSGSLQTRLVG TFGYMPPEYAQYGEVSPKVDVYAFGVVLFELVSAKEAIVKTNEFGNESKGLVGLFDEVLSLSDPSEGLRKLVDPRLGADY PLDSVRKVALLARACTHDNAQLRPSMRSIVVALMTLSSLTEDWDVGSFYENQDLAQLMSGR* |
| CDS seq | >OTG36336 ATGAACAACAATATTTCAAATACAAAGAGACATATACTACAATTGGGGCTTTGTGTTCTTTTCTTCATTGTCAAGATTGA ATCCAAGTGTAGCAATGGTTGTGATCTGGCCTTTGCATCATATTATGTCACACAAGGGTCAAATCTGACTTACATAAGCA ACATTTTTGGCCAATCAATCCCTATGATCCTTAAGTACAATCCACAAATCCCGAGAAGCGACACCATCGAAAGTGGGACC CGAATTAACGTTCCATTTTCTTGTCTATGTTTGAATGGTGATTTTTTAGGTCACACGTTTATATACCACACACAAGTTGG CGATACTTATAGTAAGGTTGCAAAAGAGGTATTTGCAAATCTTACCGATGAGTATTGGGTCCAACTGGTTAACATATTTG ACCCGGCTCAAATACCAGATTTTGCGGATGTAAATGTTACCGTGAATTGTACATGTGGCGACAAACACGTGTCGAAGGAT TACGGGTTGTTCGCAACATACCCTCTTCAACCCGGAGAAGATTTGTGGTCCTTAAGTAAAGATTCGGGTGTCCCAATGAT GTTGTTGGAGCGGTTCAACCCGGGATCCAATTTCAGTGCCGGGTCGGGACCAGTGTTTGTGCCGGCCAAAGATCAAAATG GAACTTTTCCGCCATTAAAGATCAGCAATAGGGGGTTATCTGGTGGTGCCACTGCTGGTGTATCTGTTGGAGCAGTTGCA GGTGTTCTTTTCTTTGCCATTTGCTTCTACTTTGTCTCCTATCGAAGGAAGAGGGTGGGCGAAGGATCACTGCTTCTTGA AGATGGACCCGAACATGTTCATGATGTAGGTTTACGTAGAAACATGGGAGGAACCACAAACTCGGGCACTCTAACTGGGG GTGCACATCCAGGGGCCACGGGTATAACCGTGGACAAGTCAGTGGAGTTCACATACGAGGAGCTTGCTATGGCTACAGAT GACTTTAGCATCACCAATAAGATTGGTCAAGGCGGCTTTGGTACCGTTTACTATGGAGAGCTCAGAGGCGAAAAAGCTGC AATAAAGAAGATGGAAATGCAAGCATCAAAAGAATTTCTTGCTGAATTAAAGGTGTTAACACATGTTCATCATTTGAACC TGGTACGGTTGATAGGATATTGTGTTGAAGGATCGTTGTTTTTGGTCTATGAGTTTATCGGGAATGGCAATTTGAGTCAA CATTTGCGCGGTTCATCGGGCAGAGAGTCAATTCCATGGGCTACAAGGGTTCAAATCGCCCTTGATGCGGCTAGAGGGCT TGAATACATTCATGAGCATACAGTTCCTGTCTATATACATCGCGATATCAAGTCTCCTAACATTTTAATCGATGAAGATT TCCGTGCAAAGGTTGCTGACTTTGGGCTGACAAAACTTACCGAAGTCGGGAGTGGTTCTTTACAAACCCGTTTAGTTGGC ACATTCGGCTACATGCCTCCCGAATATGCTCAGTATGGGGAGGTTTCTCCAAAGGTTGATGTATATGCTTTCGGGGTCGT ATTGTTTGAGCTAGTATCAGCGAAAGAAGCCATTGTCAAGACAAATGAATTTGGTAACGAGTCCAAAGGACTTGTTGGTT TGTTTGATGAGGTCCTAAGTTTGTCTGACCCAAGTGAAGGTTTACGCAAACTAGTCGACCCAAGGCTTGGGGCCGACTAC CCTCTCGACTCAGTGCGCAAGGTTGCACTGCTTGCTAGAGCTTGTACACATGATAATGCGCAGTTGAGGCCAAGCATGAG GTCTATTGTCGTTGCGCTAATGACACTTTCATCATTGACCGAGGATTGGGACGTTGGATCTTTCTACGAAAATCAAGATT TAGCTCAACTGATGTCAGGGAGGTAG |