| Microexon ID | Zm_4:75671004-75671011:+ |
| Species | Zea mays | Coordinates | 4:75671004..75671011 |
| Microexon Cluster ID | MEP19 |
| Size | 8 |
| Phase | 2 |
| Pfam Domain Motif | Unknown |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 50,8,50 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GYRKCWMAYCGTGAWCCTCGWTTTMGRTCYMRWAYKCRWGAYRRTGAAGGRTCTCAAGGTAARYCTGARGTRTCWRCYRTTGTTTATAAAGYTGGTGARTGCATGCAA |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 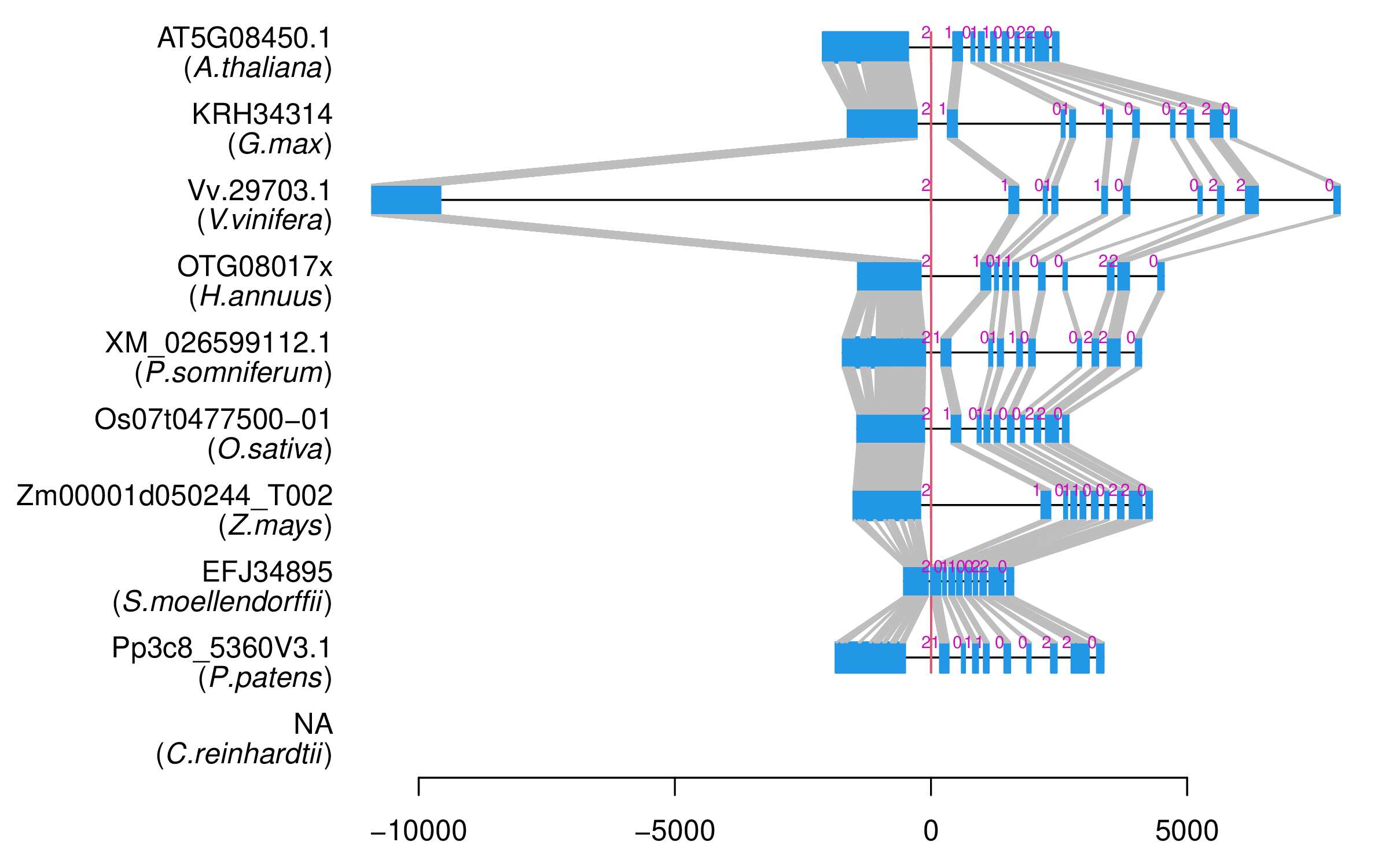 |
| Microexon DNA seq | GTCTCAAG |
| Microexon Amino Acid seq | GSQG |
| Microexon-tag DNA Seq | GTATCTCAGCGTGAACCTCGATTCCGGTCCAGAATGCGTGATGGTGAAGGGTCTCAAGGTAAGTCTGAGGTGTCTGCCATTGTTTATAAAGCTGGGGAGTGCATGCAG |
| Microexon-tag Amino Acid Seq | VSQREPRFRSRMRDGEGSQGKSEVSAIVYKAGECMQ |
| Microexon-tag spanning region | 75670748-75673209 |
| Microexon-tag prediction score | 0.9787 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | Zm00001d050244_T002x |
| Reference Transcript ID | Zm00001d050244_T002 |
| Gene ID | Zm00001d050244 |
| Gene Name | NA |
| Transcript ID | Zm00001d050244_T002 |
| Protein ID | Zm00001d050244_P002 |
| Gene ID | Zm00001d050244 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >Zm00001d050244_P002 MSGAPKRLLEEGSHSTPTKRPLDDSSLYSSPGKFIQSGGSDFHGSSEHDGRFAKFQRVESRDDKRPSVHRMPVGSTNFAV HPISSDSRLESKQNKDARDSKADDRETKVDARDVHSDSRIEFQANKIESDVKVDNRADESEIRADRRGHPDYRTDIKFGK DSHSTVPANINWKDNKEHRGKRHFEPPADTVDWRLPRPSLQSIDEAPKGPISVEGRNSKDTNESAGDYKAEPKNEDRFRD KDRKKKDEKHRDFGAREGDRNDRRTGVPLGSSGVERREMQREDRDAEKWDRERKDSLRDKEGNDREKDSARKDSSVVIAK DNPILEKASSDGAVKSAEHENTTTESKAPKDDVWKAHDRDPKDKKREKDVDAGDWLEQRNKYNDKELDDNAIEGDMEKDK DVFGSVQRRRMVRPRGGSQVSQREPRFRSRMRDGEGSQGKSEVSAIVYKAGECMQELLKSWKEFDVTQDATIAESLQHGP TLEIRIPAEFVTSTNRQVKGAQLWGTDIYTNDSDLVAVLMHTGYCSPTSSPPPSAIQELRATVRVLPPQESYTSTLRNNV RSRAWGAGIGCSFRIERCCIFKKGGGTIGLEPRLSHVSAVEPTLAPVAVERTMTTRAAASNALRQQRFVREVTIQYNLCN EPWLKYSINIVADKGLKKSLYTSARLKKGEVIYLETHINRYELCFSGDKPCIIGSSSNASESETEKHQSGSHHSQNGDRG CVEHELRDVFRWSRCKKAMPESAMRSIGIPLPADQLEVLQDNLEWEDVQWSQTGVWVSGKEYPLARVHFLSAN* |
| CDS seq | >Zm00001d050244_T002 ATGAGTGGTGCTCCAAAGAGGTTGCTCGAGGAAGGTAGTCACTCCACACCAACAAAACGCCCTTTGGATGACAGCAGCTT GTATTCGAGTCCTGGGAAATTTATTCAGTCCGGTGGCAGTGATTTCCATGGTTCTTCTGAACATGATGGTAGATTTGCGA AATTTCAACGTGTGGAGTCTCGTGATGATAAGAGGCCATCTGTACATCGGATGCCTGTTGGCTCCACTAACTTTGCTGTT CACCCCATCTCGTCTGACAGCAGATTAGAGTCAAAGCAAAATAAAGATGCACGGGACAGTAAGGCAGATGACCGCGAAAC AAAAGTCGATGCCAGGGACGTTCATAGTGATTCAAGGATTGAATTTCAGGCTAATAAAATTGAGAGTGATGTAAAGGTAG ACAATAGAGCAGATGAAAGTGAAATAAGGGCTGACAGGAGGGGCCATCCTGATTACAGAACTGACATAAAATTTGGTAAG GATAGTCATTCTACTGTTCCAGCAAACATAAACTGGAAGGACAACAAGGAGCACAGGGGTAAAAGACATTTTGAACCGCC CGCTGATACTGTGGATTGGCGTTTGCCCCGTCCTAGTTTACAAAGTATCGATGAAGCTCCCAAAGGTCCAATTTCTGTGG AAGGACGTAATTCCAAGGACACAAATGAATCTGCTGGTGATTACAAAGCTGAACCAAAAAACGAAGATAGGTTCAGAGAC AAGGACAGGAAAAAGAAGGACGAGAAGCATAGGGACTTCGGTGCAAGAGAAGGCGATAGAAATGATCGTCGGACCGGTGT ACCACTTGGCAGTAGTGGTGTTGAGCGAAGAGAAATGCAAAGGGAAGATAGGGATGCTGAGAAATGGGACAGGGAAAGAA AAGATTCCCTGCGAGACAAGGAAGGCAATGATAGGGAGAAGGATTCTGCTAGGAAAGATTCATCTGTAGTAATTGCAAAG GATAACCCTATACTAGAAAAAGCTTCATCTGATGGAGCTGTTAAGAGTGCTGAGCATGAGAATACGACAACAGAATCCAA GGCACCTAAGGATGATGTATGGAAAGCTCACGATAGGGATCCTAAGGACAAGAAAAGAGAGAAGGATGTGGATGCAGGAG ACTGGCTTGAGCAACGAAACAAATATAATGATAAGGAATTAGATGACAATGCCATTGAAGGAGATATGGAGAAAGATAAG GATGTTTTTGGAAGTGTCCAACGAAGGAGGATGGTGCGACCAAGGGGAGGTAGTCAAGTATCTCAGCGTGAACCTCGATT CCGGTCCAGAATGCGTGATGGTGAAGGGTCTCAAGGTAAGTCTGAGGTGTCTGCCATTGTTTATAAAGCTGGGGAGTGCA TGCAGGAGCTTCTGAAATCATGGAAAGAGTTTGATGTAACTCAGGATGCTACAATTGCTGAAAGCCTACAACATGGTCCT ACTCTTGAAATCCGAATACCTGCAGAATTTGTTACTTCCACTAACCGTCAGGTAAAAGGTGCTCAGCTCTGGGGAACAGA TATTTATACAAATGATTCAGATCTTGTGGCTGTGCTAATGCATACTGGTTACTGCTCCCCTACATCCTCCCCTCCACCAT CCGCCATTCAAGAGCTTCGTGCAACTGTTCGAGTTCTACCACCACAAGAGAGTTATACTTCAACACTGAGGAACAATGTG CGTTCACGTGCTTGGGGTGCTGGGATTGGTTGTAGCTTTCGGATTGAACGTTGCTGCATTTTCAAGAAAGGTGGTGGCAC CATTGGTCTTGAGCCACGCCTTAGCCACGTGTCAGCTGTGGAGCCTACTCTCGCCCCAGTTGCAGTTGAGCGTACAATGA CGACAAGAGCTGCAGCTTCTAATGCATTGCGGCAACAAAGATTTGTCCGTGAAGTGACTATACAGTACAATCTGTGCAAT GAGCCATGGTTGAAATATAGTATAAACATTGTGGCAGATAAGGGATTGAAAAAGTCTCTTTATACTTCTGCTAGACTGAA GAAAGGAGAAGTCATATATTTAGAAACACACATTAATAGGTATGAGCTTTGCTTCAGTGGAGACAAGCCTTGCATTATTG GATCAAGCTCCAATGCATCTGAATCAGAAACGGAGAAACACCAGAGCGGGAGTCACCATTCTCAGAATGGTGACAGAGGC TGTGTGGAGCATGAACTCCGGGATGTGTTCCGGTGGTCCCGCTGTAAGAAGGCCATGCCTGAAAGTGCCATGCGCTCCAT CGGTATCCCACTACCAGCAGACCAGTTAGAGGTATTGCAGGATAACCTCGAATGGGAGGATGTGCAGTGGTCACAGACCG GTGTGTGGGTATCTGGGAAGGAGTATCCCCTCGCCCGAGTGCACTTCCTCTCGGCGAACTAG |
| Microexon DNA seq | GTCTCAAG |
| Microexon Amino Acid seq | GSQG |
| Microexon-tag DNA Seq | GTATCTCAGCGTGAACCTCGATTCCGGTCCAGAATGCGTGATGGTGAAGGGTCTCAAGGTAAGTCTGAGGTGTCTGCCATTGTTTATAAAGCTGGGGAGTGCATGCAG |
| Microexon-tag Amino Acid seq | VSQREPRFRSRMRDGEGSQGKSEVSAIVYKAGECMQ |
| Transcript ID | Zm00001d050244_T002 |
| Gene ID | Zm.18649 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >Zm00001d050244_T002 MSGAPKRLLEEGSHSTPTKRPLDDSSLYSSPGKFIQSGGSDFHGSSEHDGRFAKFQRVESRDDKRPSVHRMPVGSTNFAV HPISSDSRLESKQNKDARDSKADDRETKVDARDVHSDSRIEFQANKIESDVKVDNRADESEIRADRRGHPDYRTDIKFGK DSHSTVPANINWKDNKEHRGKRHFEPPADTVDWRLPRPSLQSIDEAPKGPISVEGRNSKDTNESAGDYKAEPKNEDRFRD KDRKKKDEKHRDFGAREGDRNDRRTGVPLGSSGVERREMQREDRDAEKWDRERKDSLRDKEGNDREKDSARKDSSVVIAK DNPILEKASSDGAVKSAEHENTTTESKAPKDDVWKAHDRDPKDKKREKDVDAGDWLEQRNKYNDKELDDNAIEGDMEKDK DVFGSVQRRRMVRPRGGSQVSQREPRFRSRMRDGEGSQGKSEVSAIVYKAGECMQELLKSWKEFDVTQDATIAESLQHGP TLEIRIPAEFVTSTNRQVKGAQLWGTDIYTNDSDLVAVLMHTGYCSPTSSPPPSAIQELRATVRVLPPQESYTSTLRNNV RSRAWGAGIGCSFRIERCCIFKKGGGTIGLEPRLSHVSAVEPTLAPVAVERTMTTRAAASNALRQQRFVREVTIQYNLCN EPWLKYSINIVADKGLKKSLYTSARLKKGEVIYLETHINRYELCFSGDKPCIIGSSSNASESETEKHQSGSHHSQNGDRG CVEHELRDVFRWSRCKKAMPESAMRSIGIPLPADQLEVLQDNLEWEDVQWSQTGVWVSGKEYPLARVHFLSAN* |
| CDS seq | >Zm00001d050244_T002 ATGAGTGGTGCTCCAAAGAGGTTGCTCGAGGAAGGTAGTCACTCCACACCAACAAAACGCCCTTTGGATGACAGCAGCTT GTATTCGAGTCCTGGGAAATTTATTCAGTCCGGTGGCAGTGATTTCCATGGTTCTTCTGAACATGATGGTAGATTTGCGA AATTTCAACGTGTGGAGTCTCGTGATGATAAGAGGCCATCTGTACATCGGATGCCTGTTGGCTCCACTAACTTTGCTGTT CACCCCATCTCGTCTGACAGCAGATTAGAGTCAAAGCAAAATAAAGATGCACGGGACAGTAAGGCAGATGACCGCGAAAC AAAAGTCGATGCCAGGGACGTTCATAGTGATTCAAGGATTGAATTTCAGGCTAATAAAATTGAGAGTGATGTAAAGGTAG ACAATAGAGCAGATGAAAGTGAAATAAGGGCTGACAGGAGGGGCCATCCTGATTACAGAACTGACATAAAATTTGGTAAG GATAGTCATTCTACTGTTCCAGCAAACATAAACTGGAAGGACAACAAGGAGCACAGGGGTAAAAGACATTTTGAACCGCC CGCTGATACTGTGGATTGGCGTTTGCCCCGTCCTAGTTTACAAAGTATCGATGAAGCTCCCAAAGGTCCAATTTCTGTGG AAGGACGTAATTCCAAGGACACAAATGAATCTGCTGGTGATTACAAAGCTGAACCAAAAAACGAAGATAGGTTCAGAGAC AAGGACAGGAAAAAGAAGGACGAGAAGCATAGGGACTTCGGTGCAAGAGAAGGCGATAGAAATGATCGTCGGACCGGTGT ACCACTTGGCAGTAGTGGTGTTGAGCGAAGAGAAATGCAAAGGGAAGATAGGGATGCTGAGAAATGGGACAGGGAAAGAA AAGATTCCCTGCGAGACAAGGAAGGCAATGATAGGGAGAAGGATTCTGCTAGGAAAGATTCATCTGTAGTAATTGCAAAG GATAACCCTATACTAGAAAAAGCTTCATCTGATGGAGCTGTTAAGAGTGCTGAGCATGAGAATACGACAACAGAATCCAA GGCACCTAAGGATGATGTATGGAAAGCTCACGATAGGGATCCTAAGGACAAGAAAAGAGAGAAGGATGTGGATGCAGGAG ACTGGCTTGAGCAACGAAACAAATATAATGATAAGGAATTAGATGACAATGCCATTGAAGGAGATATGGAGAAAGATAAG GATGTTTTTGGAAGTGTCCAACGAAGGAGGATGGTGCGACCAAGGGGAGGTAGTCAAGTATCTCAGCGTGAACCTCGATT CCGGTCCAGAATGCGTGATGGTGAAGGGTCTCAAGGTAAGTCTGAGGTGTCTGCCATTGTTTATAAAGCTGGGGAGTGCA TGCAGGAGCTTCTGAAATCATGGAAAGAGTTTGATGTAACTCAGGATGCTACAATTGCTGAAAGCCTACAACATGGTCCT ACTCTTGAAATCCGAATACCTGCAGAATTTGTTACTTCCACTAACCGTCAGGTAAAAGGTGCTCAGCTCTGGGGAACAGA TATTTATACAAATGATTCAGATCTTGTGGCTGTGCTAATGCATACTGGTTACTGCTCCCCTACATCCTCCCCTCCACCAT CCGCCATTCAAGAGCTTCGTGCAACTGTTCGAGTTCTACCACCACAAGAGAGTTATACTTCAACACTGAGGAACAATGTG CGTTCACGTGCTTGGGGTGCTGGGATTGGTTGTAGCTTTCGGATTGAACGTTGCTGCATTTTCAAGAAAGGTGGTGGCAC CATTGGTCTTGAGCCACGCCTTAGCCACGTGTCAGCTGTGGAGCCTACTCTCGCCCCAGTTGCAGTTGAGCGTACAATGA CGACAAGAGCTGCAGCTTCTAATGCATTGCGGCAACAAAGATTTGTCCGTGAAGTGACTATACAGTACAATCTGTGCAAT GAGCCATGGTTGAAATATAGTATAAACATTGTGGCAGATAAGGGATTGAAAAAGTCTCTTTATACTTCTGCTAGACTGAA GAAAGGAGAAGTCATATATTTAGAAACACACATTAATAGGTATGAGCTTTGCTTCAGTGGAGACAAGCCTTGCATTATTG GATCAAGCTCCAATGCATCTGAATCAGAAACGGAGAAACACCAGAGCGGGAGTCACCATTCTCAGAATGGTGACAGAGGC TGTGTGGAGCATGAACTCCGGGATGTGTTCCGGTGGTCCCGCTGTAAGAAGGCCATGCCTGAAAGTGCCATGCGCTCCAT CGGTATCCCACTACCAGCAGACCAGTTAGAGGTATTGCAGGATAACCTCGAATGGGAGGATGTGCAGTGGTCACAGACCG GTGTGTGGGTATCTGGGAAGGAGTATCCCCTCGCCCGAGTGCACTTCCTCTCGGCGAACTAG |