| Microexon ID | Ps_NC_039365.1:38724011-38724018:+ |
| Species | Papaver somniferum | Coordinates | NC_039365.1:38724011..38724018 |
| Microexon Cluster ID | MEP19 |
| Size | 8 |
| Phase | 2 |
| Pfam Domain Motif | Unknown |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 50,8,50 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GYRKCWMAYCGTGAWCCTCGWTTTMGRTCYMRWAYKCRWGAYRRTGAAGGRTCTCAAGGTAARYCTGARGTRTCWRCYRTTGTTTATAAAGYTGGTGARTGCATGCAA |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 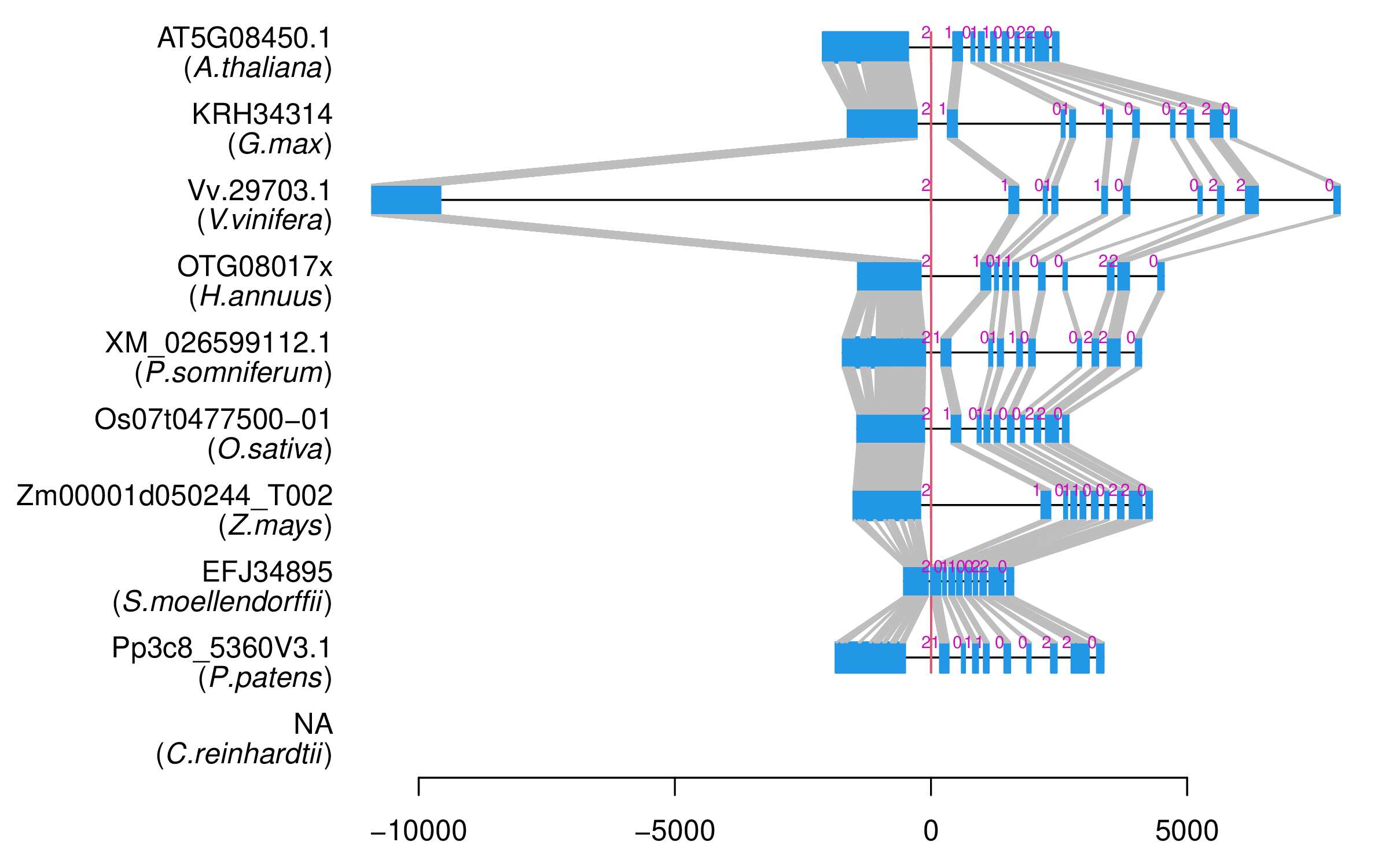 |
| Microexon DNA seq | ATCTCAAG |
| Microexon Amino Acid seq | GSQG |
| Microexon-tag DNA Seq | GTGGGTAACAGGGAGCCTCGGTTTCGATCTCGCTCCCGGGATATCGAAGGATCTCAAGGAAAACCAGAAGTAACTAGTGTGGTTTATAAAATTGGTGATTGCATGCAA |
| Microexon-tag Amino Acid Seq | VGNREPRFRSRSRDIEGSQGKPEVTSVVYKIGDCMQ |
| Microexon-tag spanning region | 38723848-38724266 |
| Microexon-tag prediction score | 0.9237 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026555545.1x |
| Reference Transcript ID | XM_026555545.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026555545.1 |
| Protein ID | XP_026411330.1 |
| Gene ID | LOC113306625 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026411330.1 MSGAPKRPHEEGSHPLTSKQTLEDTSKGSGKASHPVSNEYHPLPPEQQGPDGRLAKVPRIESRDADKRSPMLSTYHPVPS EGRLELNLKDAKNNRDRNVTHSSETRLDTEPTPQRMDVLGPRVENDMRKENKVDENKNETKHDREPNIDLKSGARTEKSI FNSGNSTVSTQKESKEHHRGNRYSDTPDGSSTARILPQNNVQGGNETGNEHSTTEARISSQFPRGEKDVHIDKESRGSDD KEMKRDKEPHLELKSERDGHAAGNTQLSRKEPKEHHRGGRHPETSMGPWSSPQTNFQGATESGNKSSVIEDPSRLGTHES LGDNKAGTRGDDRMKEKDRKKKEEKPKDWGDKEKDRNDRRNITQPGYNNIERRDSTKEERKSDKWEKERKDLHKEERLKE RENDHVKREAVSGTEKEVLNDEKELVDGSTKMADQENQALEQNRLKDCENMKNQDKDAKEKRQEKDADIEGDRQGKRMCF DKESDDGCTEGDGGSEREREVFGYSNQQRRRMLRPRGSPQVGNREPRFRSRSRDIEGSQGKPEVTSVVYKIGDCMQELIK SWKEFESSQENSKDDSSLNGPTLEIRIPTDCVTATNRQVKSGQLWGTDIYTDDSDLVAVLMHTGYCRLTASPPPPAIQEL CATIRVLPPQSCYLSTLRNNVRSRAWGAATGCSYRVERCSIVKKGGGSIDLDPCLTHTSTVEPTLAPVAVERSITTRSAA SNAMRQQRFVREVTIQYNHCNEPWIKYSISIVADKGLKKPLYTSARLKKGEVLYLETPKDRYELCFNGEKTVSAISHIPE SDKEKHQSHHNSHASNGERNVAERETVVIDGFRWSRCKKILPQRVMRSIGIPLPIEHLEVLEESLDWEDVQWSQTGVWIA GKEYTLARVHFLSL* |
| CDS seq | >XM_026555545.1 ATGAGTGGTGCTCCGAAAAGACCACATGAAGAGGGAAGCCATCCTTTGACTTCCAAACAGACACTTGAAGATACCAGTAA GGGTTCAGGAAAAGCTTCTCATCCAGTTTCTAACGAATACCACCCTCTTCCTCCTGAACAGCAGGGGCCAGATGGTCGGT TGGCAAAAGTTCCTCGGATTGAATCTCGTGATGCTGACAAAAGATCACCTATGCTTTCAACATATCACCCGGTTCCTTCA GAAGGCAGGTTGGAGTTGAACTTGAAAGATGCGAAGAACAACAGAGATCGCAATGTCACACATTCTTCAGAAACCAGGTT GGACACTGAACCCACTCCTCAAAGGATGGATGTACTTGGTCCTAGAGTTGAGAATGATATGAGGAAAGAAAATAAGGTGG ATGAGAACAAAAATGAAACGAAACACGACAGGGAGCCTAATATAGATTTGAAGAGCGGTGCTAGGACAGAAAAGAGTATT TTCAACTCAGGTAATAGTACTGTTTCAACCCAGAAAGAATCAAAAGAACACCACAGAGGAAATAGATATTCTGATACACC AGATGGAAGTTCAACTGCAAGGATTTTGCCCCAAAATAACGTTCAAGGAGGGAATGAGACTGGAAATGAACATTCAACAA CTGAAGCAAGGATTAGTTCTCAATTTCCCCGCGGCGAGAAAGATGTACATATTGATAAAGAAAGTAGAGGTAGCGATGAT AAAGAAATGAAACGTGATAAGGAGCCCCATTTAGAGTTGAAGAGTGAGAGGGATGGACATGCTGCAGGAAATACCCAATT GAGCCGAAAAGAGCCTAAGGAACATCACAGAGGAGGTAGACATCCAGAAACCTCAATGGGTCCTTGGTCATCACCGCAAA CTAATTTCCAAGGTGCAACTGAGAGTGGAAATAAATCTTCAGTTATTGAAGATCCAAGTCGCTTAGGTACACACGAATCT TTGGGCGACAATAAGGCCGGTACAAGAGGGGATGATAGAATGAAAGAGAAGGACAGGAAAAAGAAAGAAGAGAAACCAAA GGATTGGGGAGACAAGGAAAAGGACAGAAATGACCGTCGAAATATCACACAACCAGGTTATAACAATATTGAACGCAGGG ATTCAACAAAGGAAGAAAGAAAGTCGGATAAGTGGGAGAAGGAGAGAAAGGACCTTCATAAAGAAGAGCGACTGAAGGAG AGGGAAAATGACCATGTAAAGAGGGAGGCAGTTAGTGGGACTGAGAAGGAGGTTCTTAATGATGAGAAAGAATTGGTGGA TGGATCTACCAAAATGGCAGACCAGGAAAATCAAGCTTTAGAGCAAAACAGGCTCAAAGATTGTGAGAACATGAAAAACC AGGACAAAGATGCTAAGGAAAAGAGGCAAGAAAAGGATGCTGATATTGAAGGAGATAGACAAGGAAAACGCATGTGTTTT GATAAGGAGTCAGATGACGGCTGCACAGAGGGTGATGGAGGTTCAGAAAGAGAAAGAGAAGTTTTTGGATATAGCAATCA GCAGCGTAGGAGGATGCTTCGACCTAGGGGATCTCCTCAAGTGGGTAACAGGGAGCCTCGGTTTCGATCTCGCTCCCGGG ATATCGAAGGATCTCAAGGAAAACCAGAAGTAACTAGTGTGGTTTATAAAATTGGTGATTGCATGCAAGAGTTGATAAAA TCGTGGAAGGAATTTGAATCCTCTCAAGAGAACAGTAAAGATGACTCCTCTCTTAATGGCCCAACTCTGGAAATTCGGAT ACCTACCGACTGTGTTACTGCTACAAATCGTCAGGTCAAAAGTGGCCAGTTATGGGGGACGGATATCTACACTGATGATT CTGACCTTGTTGCTGTTCTCATGCACACTGGTTACTGCCGCCTAACAGCGTCTCCTCCTCCACCTGCTATCCAAGAACTA TGTGCAACTATACGAGTGTTGCCTCCACAATCTTGTTACTTGTCGACGTTGAGAAATAATGTCCGTTCCCGTGCTTGGGG AGCTGCTACTGGTTGTAGTTACCGTGTTGAAAGATGCTCCATTGTAAAGAAGGGTGGGGGAAGCATTGATCTTGACCCTT GTCTGACACATACATCAACAGTGGAGCCTACTCTTGCTCCAGTGGCAGTTGAACGCTCGATAACTACCAGATCAGCAGCT TCGAATGCAATGCGGCAACAAAGATTCGTTCGAGAAGTCACAATTCAATACAATCACTGCAATGAACCTTGGATTAAATA TAGCATAAGCATAGTTGCTGACAAGGGACTGAAGAAGCCTCTTTATACATCTGCTCGTTTGAAGAAGGGAGAAGTTTTAT ATTTGGAAACACCTAAAGACAGGTACGAGCTCTGTTTCAATGGAGAGAAAACAGTTAGCGCAATCTCTCATATACCAGAA AGTGACAAGGAAAAACATCAAAGCCACCATAATTCTCACGCTTCAAATGGTGAGAGAAATGTGGCGGAACGTGAAACCGT AGTTATTGATGGATTCCGATGGTCTCGTTGTAAGAAGATCCTGCCCCAGAGGGTTATGCGTTCAATTGGGATCCCGTTGC CCATTGAACACTTGGAGGTATTGGAGGAGAGTCTTGACTGGGAGGATGTGCAATGGTCACAGACCGGTGTTTGGATAGCA GGAAAAGAATACACACTTGCTAGGGTTCATTTTCTCTCCTTATAG |
| Microexon DNA seq | ATCTCAAG |
| Microexon Amino Acid seq | GSQG |
| Microexon-tag DNA Seq | GTGGGTAACAGGGAGCCTCGGTTTCGATCTCGCTCCCGGGATATCGAAGGATCTCAAGGAAAACCAGAAGTAACTAGTGTGGTTTATAAAATTGGTGATTGCATGCAA |
| Microexon-tag Amino Acid seq | VGNREPRFRSRSRDIEGSQGKPEVTSVVYKIGDCMQ |
| Transcript ID | XM_026555545.1 |
| Gene ID | Ps.48972 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026555545.1 MSGAPKRPHEEGSHPLTSKQTLEDTSKGSGKASHPVSNEYHPLPPEQQGPDGRLAKVPRIESRDADKRSPMLSTYHPVPS EGRLELNLKDAKNNRDRNVTHSSETRLDTEPTPQRMDVLGPRVENDMRKENKVDENKNETKHDREPNIDLKSGARTEKSI FNSGNSTVSTQKESKEHHRGNRYSDTPDGSSTARILPQNNVQGGNETGNEHSTTEARISSQFPRGEKDVHIDKESRGSDD KEMKRDKEPHLELKSERDGHAAGNTQLSRKEPKEHHRGGRHPETSMGPWSSPQTNFQGATESGNKSSVIEDPSRLGTHES LGDNKAGTRGDDRMKEKDRKKKEEKPKDWGDKEKDRNDRRNITQPGYNNIERRDSTKEERKSDKWEKERKDLHKEERLKE RENDHVKREAVSGTEKEVLNDEKELVDGSTKMADQENQALEQNRLKDCENMKNQDKDAKEKRQEKDADIEGDRQGKRMCF DKESDDGCTEGDGGSEREREVFGYSNQQRRRMLRPRGSPQVGNREPRFRSRSRDIEGSQGKPEVTSVVYKIGDCMQELIK SWKEFESSQENSKDDSSLNGPTLEIRIPTDCVTATNRQVKSGQLWGTDIYTDDSDLVAVLMHTGYCRLTASPPPPAIQEL CATIRVLPPQSCYLSTLRNNVRSRAWGAATGCSYRVERCSIVKKGGGSIDLDPCLTHTSTVEPTLAPVAVERSITTRSAA SNAMRQQRFVREVTIQYNHCNEPWIKYSISIVADKGLKKPLYTSARLKKGEVLYLETPKDRYELCFNGEKTVSAISHIPE SDKEKHQSHHNSHASNGERNVAERETVVIDGFRWSRCKKILPQRVMRSIGIPLPIEHLEVLEESLDWEDVQWSQTGVWIA GKEYTLARVHFLSL* |
| CDS seq | >XM_026555545.1 ATGAGTGGTGCTCCGAAAAGACCACATGAAGAGGGAAGCCATCCTTTGACTTCCAAACAGACACTTGAAGATACCAGTAA GGGTTCAGGAAAAGCTTCTCATCCAGTTTCTAACGAATACCACCCTCTTCCTCCTGAACAGCAGGGGCCAGATGGTCGGT TGGCAAAAGTTCCTCGGATTGAATCTCGTGATGCTGACAAAAGATCACCTATGCTTTCAACATATCACCCGGTTCCTTCA GAAGGCAGGTTGGAGTTGAACTTGAAAGATGCGAAGAACAACAGAGATCGCAATGTCACACATTCTTCAGAAACCAGGTT GGACACTGAACCCACTCCTCAAAGGATGGATGTACTTGGTCCTAGAGTTGAGAATGATATGAGGAAAGAAAATAAGGTGG ATGAGAACAAAAATGAAACGAAACACGACAGGGAGCCTAATATAGATTTGAAGAGCGGTGCTAGGACAGAAAAGAGTATT TTCAACTCAGGTAATAGTACTGTTTCAACCCAGAAAGAATCAAAAGAACACCACAGAGGAAATAGATATTCTGATACACC AGATGGAAGTTCAACTGCAAGGATTTTGCCCCAAAATAACGTTCAAGGAGGGAATGAGACTGGAAATGAACATTCAACAA CTGAAGCAAGGATTAGTTCTCAATTTCCCCGCGGCGAGAAAGATGTACATATTGATAAAGAAAGTAGAGGTAGCGATGAT AAAGAAATGAAACGTGATAAGGAGCCCCATTTAGAGTTGAAGAGTGAGAGGGATGGACATGCTGCAGGAAATACCCAATT GAGCCGAAAAGAGCCTAAGGAACATCACAGAGGAGGTAGACATCCAGAAACCTCAATGGGTCCTTGGTCATCACCGCAAA CTAATTTCCAAGGTGCAACTGAGAGTGGAAATAAATCTTCAGTTATTGAAGATCCAAGTCGCTTAGGTACACACGAATCT TTGGGCGACAATAAGGCCGGTACAAGAGGGGATGATAGAATGAAAGAGAAGGACAGGAAAAAGAAAGAAGAGAAACCAAA GGATTGGGGAGACAAGGAAAAGGACAGAAATGACCGTCGAAATATCACACAACCAGGTTATAACAATATTGAACGCAGGG ATTCAACAAAGGAAGAAAGAAAGTCGGATAAGTGGGAGAAGGAGAGAAAGGACCTTCATAAAGAAGAGCGACTGAAGGAG AGGGAAAATGACCATGTAAAGAGGGAGGCAGTTAGTGGGACTGAGAAGGAGGTTCTTAATGATGAGAAAGAATTGGTGGA TGGATCTACCAAAATGGCAGACCAGGAAAATCAAGCTTTAGAGCAAAACAGGCTCAAAGATTGTGAGAACATGAAAAACC AGGACAAAGATGCTAAGGAAAAGAGGCAAGAAAAGGATGCTGATATTGAAGGAGATAGACAAGGAAAACGCATGTGTTTT GATAAGGAGTCAGATGACGGCTGCACAGAGGGTGATGGAGGTTCAGAAAGAGAAAGAGAAGTTTTTGGATATAGCAATCA GCAGCGTAGGAGGATGCTTCGACCTAGGGGATCTCCTCAAGTGGGTAACAGGGAGCCTCGGTTTCGATCTCGCTCCCGGG ATATCGAAGGATCTCAAGGAAAACCAGAAGTAACTAGTGTGGTTTATAAAATTGGTGATTGCATGCAAGAGTTGATAAAA TCGTGGAAGGAATTTGAATCCTCTCAAGAGAACAGTAAAGATGACTCCTCTCTTAATGGCCCAACTCTGGAAATTCGGAT ACCTACCGACTGTGTTACTGCTACAAATCGTCAGGTCAAAAGTGGCCAGTTATGGGGGACGGATATCTACACTGATGATT CTGACCTTGTTGCTGTTCTCATGCACACTGGTTACTGCCGCCTAACAGCGTCTCCTCCTCCACCTGCTATCCAAGAACTA TGTGCAACTATACGAGTGTTGCCTCCACAATCTTGTTACTTGTCGACGTTGAGAAATAATGTCCGTTCCCGTGCTTGGGG AGCTGCTACTGGTTGTAGTTACCGTGTTGAAAGATGCTCCATTGTAAAGAAGGGTGGGGGAAGCATTGATCTTGACCCTT GTCTGACACATACATCAACAGTGGAGCCTACTCTTGCTCCAGTGGCAGTTGAACGCTCGATAACTACCAGATCAGCAGCT TCGAATGCAATGCGGCAACAAAGATTCGTTCGAGAAGTCACAATTCAATACAATCACTGCAATGAACCTTGGATTAAATA TAGCATAAGCATAGTTGCTGACAAGGGACTGAAGAAGCCTCTTTATACATCTGCTCGTTTGAAGAAGGGAGAAGTTTTAT ATTTGGAAACACCTAAAGACAGGTACGAGCTCTGTTTCAATGGAGAGAAAACAGTTAGCGCAATCTCTCATATACCAGAA AGTGACAAGGAAAAACATCAAAGCCACCATAATTCTCACGCTTCAAATGGTGAGAGAAATGTGGCGGAACGTGAAACCGT AGTTATTGATGGATTCCGATGGTCTCGTTGTAAGAAGATCCTGCCCCAGAGGGTTATGCGTTCAATTGGGATCCCGTTGC CCATTGAACACTTGGAGGTATTGGAGGAGAGTCTTGACTGGGAGGATGTGCAATGGTCACAGACCGGTGTTTGGATAGCA GGAAAAGAATACACACTTGCTAGGGTTCATTTTCTCTCCTTATAG |