| Microexon ID | Gm_20:45057409-45057416:+ |
| Species | Glycine max | Coordinates | 20:45057409..45057416 |
| Microexon Cluster ID | MEP19 |
| Size | 8 |
| Phase | 2 |
| Pfam Domain Motif | Unknown |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 50,8,50 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GYRKCWMAYCGTGAWCCTCGWTTTMGRTCYMRWAYKCRWGAYRRTGAAGGRTCTCAAGGTAARYCTGARGTRTCWRCYRTTGTTTATAAAGYTGGTGARTGCATGCAA |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 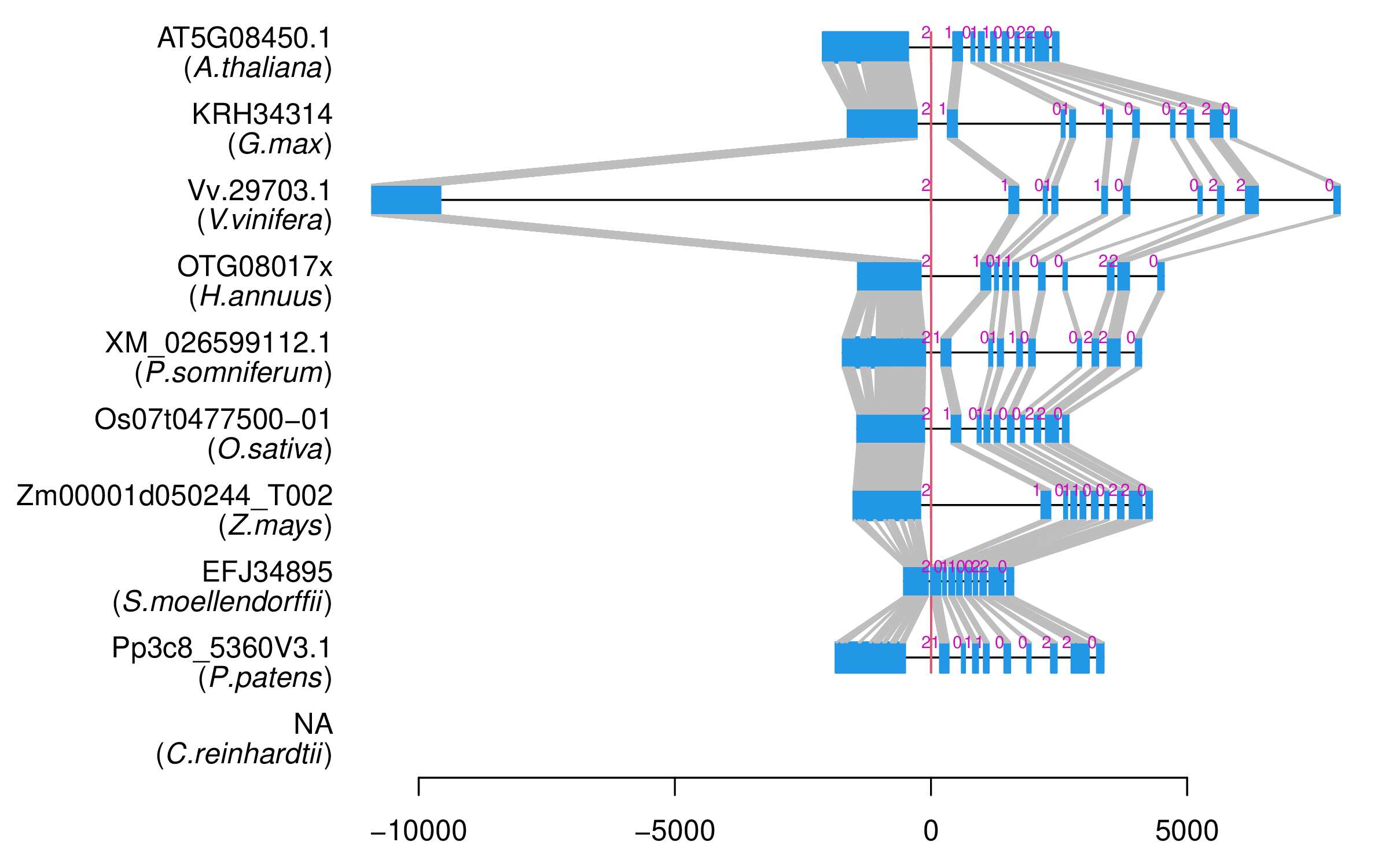 |
| Microexon DNA seq | GTCTCAAG |
| Microexon Amino Acid seq | GSQG |
| Microexon-tag DNA Seq | GTGCCTAACCGGGAGCCTCGTTTCAGATCCCGTGCCCAAGATAATGATGGGTCTCAAGGTAAAGTAGAAGTTTCTTCTGTTGTTTATAAAGTTGGCGAAAGCATGCAA |
| Microexon-tag Amino Acid Seq | VPNREPRFRSRAQDNDGSQGKVEVSSVVYKVGESMQ |
| Microexon-tag spanning region | 45057111-45057787 |
| Microexon-tag prediction score | 0.9531 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | KRG92487x |
| Reference Transcript ID | KRG92487 |
| Gene ID | GLYMA_20G214600 |
| Gene Name | NA |
| Transcript ID | KRG92487 |
| Protein ID | KRG92487 |
| Gene ID | GLYMA_20G214600 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >KRG92487 MSGAPKRSHEESVHSSSKHSNEDSGTYSKLVSLPVSNEYHMPYDISQDSRVAKVPRTEFRDADRRSPLNPVYRMSSPLND SRADNPIGPENRIESRDSKDSRDPRFENRDTKTEKELYGEARRDPPNAKSEKDMRVEGRGDDNKDVWHDRDSHNDPKGDT KTEKDGYNVASSHLNWKDSKEYHRGKRYSDAPGGSLDTWHMLRGNTQGSVEVGKESSAAGERDYVEAHEAVSENKVDPKG DDRSKEKDRKRKDVKHREWGDREKERSDRRNSPQVSNSTGDCKESTKEDRDVERLEREKKDLPEEKENIKEREKDQMKRE SWNGMEKEVSINEKEPVDASAKLPEQEPVLPEQKKQKEVDSWKNVDREAREKRKERDADLEGDRSDKHSKCLDKESNDGC ADGEGMMEKEREVYNYSSQHRKRIQRSRGSPQVPNREPRFRSRAQDNDGSQGKVEVSSVVYKVGESMQELIKLWKEYESS QSQMEKNGESSNNGPTLEIRIPSEHITATNRQDALRHQYPYSANYLVRGGQLWGTDVYTYDSDLVAVLMHTGYCRPTASP PHAAIQELRATVRVLPPQDCYISTLRNNVRSRAWGAAIGCSYRVERCCIVKKGGGTIDLEPCLTHTSTIEPTLAPVTVER TMTTRAAASNALRQQRFVREVTIQYNLCNEPWIKYSISTVADKGLKKPLYTSARLKKGEVLYLETHLSRYELCFTGEKML KVTPAAPLHDPATEKSQNHHPHSANGEKNDCENVMIDAFRWSRCKKPLPQKLMRTIGIPLPLEHIEVLEENLDWEDVQWS QAGVWIAGKEYTLARVHFLSMN* |
| CDS seq | >KRG92487 ATGAGTGGTGCACCTAAGAGATCTCATGAAGAGTCTGTTCATTCATCTTCAAAGCACTCAAATGAAGATTCGGGTACTTA TTCCAAGTTGGTTTCATTGCCAGTCTCAAATGAGTACCATATGCCTTATGATATAAGTCAGGACTCCCGGGTGGCAAAAG TGCCTCGAACTGAATTTCGTGATGCAGATAGAAGATCCCCTCTTAATCCAGTGTATCGGATGTCGTCACCTTTGAATGAT TCTCGTGCAGATAATCCTATTGGTCCTGAGAATAGGATAGAATCAAGGGATTCGAAGGACAGTAGAGATCCCCGGTTTGA GAATCGTGATACAAAGACAGAGAAGGAGTTGTATGGTGAAGCAAGAAGGGATCCTCCAAATGCTAAAAGTGAAAAGGATA TGCGCGTAGAAGGTAGAGGAGATGACAACAAGGATGTTTGGCATGATCGGGATAGTCATAATGATCCGAAAGGTGACACC AAGACAGAGAAAGATGGTTATAATGTGGCTAGCAGCCACTTGAATTGGAAAGATTCAAAAGAGTACCATAGAGGAAAAAG ATATTCTGATGCTCCTGGTGGAAGTTTGGACACATGGCATATGTTACGTGGAAATACACAAGGCTCGGTTGAGGTTGGGA AGGAGAGTTCCGCAGCAGGAGAGAGAGATTATGTTGAAGCTCATGAAGCTGTTAGTGAGAACAAAGTTGATCCTAAAGGT GATGATAGATCCAAAGAGAAAGATAGAAAGAGGAAAGATGTGAAGCATAGGGAATGGGGAGATAGGGAAAAAGAAAGAAG TGATCGTAGAAACAGTCCACAAGTTAGCAATAGTACCGGTGACTGCAAAGAATCTACCAAGGAAGATAGAGATGTAGAAA GGTTGGAGAGGGAGAAAAAAGATCTTCCAGAAGAGAAAGAAAATATAAAAGAGAGGGAAAAGGATCAGATGAAGAGGGAA TCATGGAATGGAATGGAGAAAGAGGTCTCAATTAACGAGAAGGAACCTGTTGATGCATCAGCTAAACTTCCTGAACAAGA ACCTGTGTTACCAGAGCAGAAGAAACAAAAAGAAGTTGATAGCTGGAAAAATGTAGATAGAGAAGCTAGAGAGAAGAGAA AAGAAAGGGATGCTGATTTAGAAGGAGATAGGTCTGATAAGCATAGCAAATGTCTTGACAAGGAATCAAACGATGGGTGT GCTGATGGAGAAGGGATGATGGAGAAGGAGAGGGAGGTCTATAATTATAGCAGTCAGCACCGTAAGAGGATACAACGATC TAGAGGGAGCCCTCAGGTGCCTAACCGGGAGCCTCGTTTCAGATCCCGTGCCCAAGATAATGATGGGTCTCAAGGTAAAG TAGAAGTTTCTTCTGTTGTTTATAAAGTTGGCGAAAGCATGCAAGAACTGATAAAGTTGTGGAAGGAATATGAATCATCT CAATCTCAAATGGAAAAAAATGGTGAAAGCTCTAATAATGGTCCCACTCTGGAAATTCGTATACCATCTGAGCATATCAC AGCTACAAACCGCCAAGATGCTCTGAGACATCAATATCCATATTCTGCCAATTATCTGGTCAGAGGTGGCCAGCTTTGGG GGACCGATGTGTACACATACGATTCAGATCTTGTTGCTGTTCTCATGCATACAGGTTACTGTCGCCCAACAGCGTCTCCA CCCCATGCAGCCATACAAGAATTGCGTGCAACCGTTCGTGTACTACCTCCTCAAGATTGCTATATTTCTACACTGAGAAA CAATGTCCGTTCCCGTGCTTGGGGTGCAGCAATTGGTTGTAGTTATAGAGTGGAGCGGTGTTGCATTGTGAAGAAAGGAG GTGGAACTATTGATCTTGAACCTTGCCTTACACATACATCAACTATTGAGCCCACCCTTGCTCCAGTGACTGTTGAGCGA ACTATGACTACCAGGGCTGCAGCTTCGAATGCATTGCGGCAACAAAGATTTGTTCGAGAAGTCACAATACAGTACAATCT CTGCAATGAGCCTTGGATAAAGTATAGTATAAGCACTGTTGCTGACAAGGGTTTAAAAAAGCCACTTTACACATCTGCAC GTTTGAAGAAGGGGGAAGTTTTGTATTTGGAGACACATTTGTCCAGATATGAACTTTGTTTTACTGGAGAGAAGATGCTC AAGGTTACACCAGCAGCCCCGTTGCATGACCCTGCCACAGAAAAGTCTCAAAATCACCACCCACATTCTGCAAATGGTGA AAAAAATGATTGTGAGAATGTCATGATTGACGCATTCCGGTGGTCTCGTTGTAAGAAGCCTCTGCCACAGAAACTGATGC GTACAATTGGCATCCCTTTGCCTCTTGAACATATAGAGGTACTGGAGGAAAATTTGGACTGGGAAGATGTGCAATGGTCG CAAGCTGGTGTTTGGATTGCTGGAAAGGAATATACCCTGGCACGGGTGCATTTCTTGTCAATGAATTAA |
| Microexon DNA seq | GTCTCAAG |
| Microexon Amino Acid seq | GSQG |
| Microexon-tag DNA Seq | GTGCCTAACCGGGAGCCTCGTTTCAGATCCCGTGCCCAAGATAATGATGGGTCTCAAGGTAAAGTAGAAGTTTCTTCTGTTGTTTATAAAGTTGGCGAAAGCATGCAA |
| Microexon-tag Amino Acid seq | VPNREPRFRSRAQDNDGSQGKVEVSSVVYKVGESMQ |
| Transcript ID | Gm.34485.2 |
| Gene ID | Gm.34485 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >Gm.34485.2 MSGAPKRSHEESVHSSSKHSNEDSGTYSKLVSLPVSNEYHMPYDISQDSRVAKVPRTEFRDADRRSPLNPVYRMSSPLND SRADNPIGPENRIESRDSKDSRDPRFENRDTKTEKELYGEARRDPPNAKSEKDMRVEGRGDDNKDVWHDRDSHNDPKGDT KTEKDGYNVASSHLNWKDSKEYHRGKRYSDAPGGSLDTWHMLRGNTQGSVEVGKESSAAGERDYVEAHEAVSENKVDPKG DDRSKEKDRKRKDVKHREWGDREKERSDRRNSPQVSNSTGDCKESTKEDRDVERLEREKKDLPEEKENIKEREKDQMKRE SWNGMEKEVSINEKEPVDASAKLPEQEPVLPEQKKQKEVDSWKNVDREAREKRKERDADLEGDRSDKHSKCLDKESNDGC ADGEGMMEKEREVYNYSSQHRKRIQRSRGSPQVPNREPRFRSRAQDNDGSQGKVEVSSVVYKVGESMQELIKLWKEYESS QSQMEKNGESSNNGPTLEIRIPSEHITATNRQDALRHQYPYSANYLVRGGQLWGTDVYTYDSDLVAVLMHTGYCRPTASP PHAAIQELRATVRVLPPQDCYISTLRNNVRSRAWGAAIGCSYRVERCCIVKKGGGTIDLEPCLTHTSTIEPTLAPVTVER TMTTRAAASNALRQQRFVREVTIQYNLCNEPWIKYSISTVADKGLKKPLYTSARLKKGEVLYLETHLSRYELCFTGEKML KVTPAAPLHDPATEKSQNHHPHSANGEKNDCENVMIDAFRWSRCKKPLPQKLMRTIGIPLPLEHIEVLEENLDWEDVQWS QAGVWIAGKEYTLARVHFLSMN* |
| CDS seq | >Gm.34485.2 ATGAGTGGTGCACCTAAGAGATCTCATGAAGAGTCTGTTCATTCATCTTCAAAGCACTCAAATGAAGATTCGGGTACTTA TTCCAAGTTGGTTTCATTGCCAGTCTCAAATGAGTACCATATGCCTTATGATATAAGTCAGGACTCCCGGGTGGCAAAAG TGCCTCGAACTGAATTTCGTGATGCAGATAGAAGATCCCCTCTTAATCCAGTGTATCGGATGTCGTCACCTTTGAATGAT TCTCGTGCAGATAATCCTATTGGTCCTGAGAATAGGATAGAATCAAGGGATTCGAAGGACAGTAGAGATCCCCGGTTTGA GAATCGTGATACAAAGACAGAGAAGGAGTTGTATGGTGAAGCAAGAAGGGATCCTCCAAATGCTAAAAGTGAAAAGGATA TGCGCGTAGAAGGTAGAGGAGATGACAACAAGGATGTTTGGCATGATCGGGATAGTCATAATGATCCGAAAGGTGACACC AAGACAGAGAAAGATGGTTATAATGTGGCTAGCAGCCACTTGAATTGGAAAGATTCAAAAGAGTACCATAGAGGAAAAAG ATATTCTGATGCTCCTGGTGGAAGTTTGGACACATGGCATATGTTACGTGGAAATACACAAGGCTCGGTTGAGGTTGGGA AGGAGAGTTCCGCAGCAGGAGAGAGAGATTATGTTGAAGCTCATGAAGCTGTTAGTGAGAACAAAGTTGATCCTAAAGGT GATGATAGATCCAAAGAGAAAGATAGAAAGAGGAAAGATGTGAAGCATAGGGAATGGGGAGATAGGGAAAAAGAAAGAAG TGATCGTAGAAACAGTCCACAAGTTAGCAATAGTACCGGTGACTGCAAAGAATCTACCAAGGAAGATAGAGATGTAGAAA GGTTGGAGAGGGAGAAAAAAGATCTTCCAGAAGAGAAAGAAAATATAAAAGAGAGGGAAAAGGATCAGATGAAGAGGGAA TCATGGAATGGAATGGAGAAAGAGGTCTCAATTAACGAGAAGGAACCTGTTGATGCATCAGCTAAACTTCCTGAACAAGA ACCTGTGTTACCAGAGCAGAAGAAACAAAAAGAAGTTGATAGCTGGAAAAATGTAGATAGAGAAGCTAGAGAGAAGAGAA AAGAAAGGGATGCTGATTTAGAAGGAGATAGGTCTGATAAGCATAGCAAATGTCTTGACAAGGAATCAAACGATGGGTGT GCTGATGGAGAAGGGATGATGGAGAAGGAGAGGGAGGTCTATAATTATAGCAGTCAGCACCGTAAGAGGATACAACGATC TAGAGGGAGCCCTCAGGTGCCTAACCGGGAGCCTCGTTTCAGATCCCGTGCCCAAGATAATGATGGGTCTCAAGGTAAAG TAGAAGTTTCTTCTGTTGTTTATAAAGTTGGCGAAAGCATGCAAGAACTGATAAAGTTGTGGAAGGAATATGAATCATCT CAATCTCAAATGGAAAAAAATGGTGAAAGCTCTAATAATGGTCCCACTCTGGAAATTCGTATACCATCTGAGCATATCAC AGCTACAAACCGCCAAGATGCTCTGAGACATCAATATCCATATTCTGCCAATTATCTGGTCAGAGGTGGCCAGCTTTGGG GGACCGATGTGTACACATACGATTCAGATCTTGTTGCTGTTCTCATGCATACAGGTTACTGTCGCCCAACAGCGTCTCCA CCCCATGCAGCCATACAAGAATTGCGTGCAACCGTTCGTGTACTACCTCCTCAAGATTGCTATATTTCTACACTGAGAAA CAATGTCCGTTCCCGTGCTTGGGGTGCAGCAATTGGTTGTAGTTATAGAGTGGAGCGGTGTTGCATTGTGAAGAAAGGAG GTGGAACTATTGATCTTGAACCTTGCCTTACACATACATCAACTATTGAGCCCACCCTTGCTCCAGTGACTGTTGAGCGA ACTATGACTACCAGGGCTGCAGCTTCGAATGCATTGCGGCAACAAAGATTTGTTCGAGAAGTCACAATACAGTACAATCT CTGCAATGAGCCTTGGATAAAGTATAGTATAAGCACTGTTGCTGACAAGGGTTTAAAAAAGCCACTTTACACATCTGCAC GTTTGAAGAAGGGGGAAGTTTTGTATTTGGAGACACATTTGTCCAGATATGAACTTTGTTTTACTGGAGAGAAGATGCTC AAGGTTACACCAGCAGCCCCGTTGCATGACCCTGCCACAGAAAAGTCTCAAAATCACCACCCACATTCTGCAAATGGTGA AAAAAATGATTGTGAGAATGTCATGATTGACGCATTCCGGTGGTCTCGTTGTAAGAAGCCTCTGCCACAGAAACTGATGC GTACAATTGGCATCCCTTTGCCTCTTGAACATATAGAGGTACTGGAGGAAAATTTGGACTGGGAAGATGTGCAATGGTCG CAAGCTGGTGTTTGGATTGCTGGAAAGGAATATACCCTGGCACGGGTGCATTTCTTGTCAATGAATTAA |