| Microexon ID | Gm_10:40983726-40983733:- |
| Species | Glycine max | Coordinates | 10:40983726..40983733 |
| Microexon Cluster ID | MEP19 |
| Size | 8 |
| Phase | 2 |
| Pfam Domain Motif | Unknown |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 50,8,50 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GYRKCWMAYCGTGAWCCTCGWTTTMGRTCYMRWAYKCRWGAYRRTGAAGGRTCTCAAGGTAARYCTGARGTRTCWRCYRTTGTTTATAAAGYTGGTGARTGCATGCAA |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 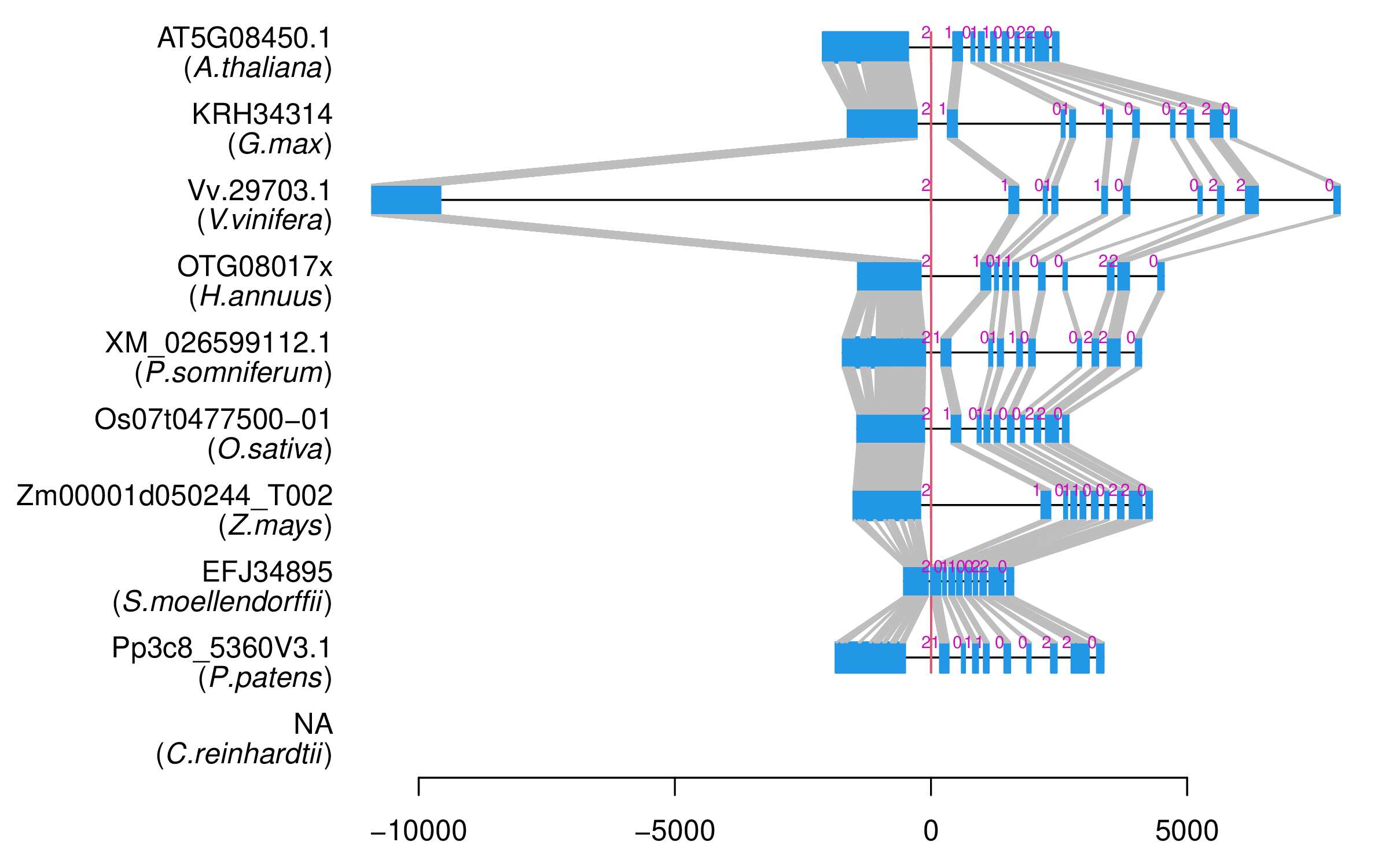 |
| Microexon DNA seq | GTCTCAAG |
| Microexon Amino Acid seq | GSQG |
| Microexon-tag DNA Seq | GCGCCGAACCGGGAGTCTTTTTTCAGATCCCATCCCCAAGACAAAGACGGGTCTCAAGGTAAAGTAGAAGTTTCTTCTGTTGTTTATAAAGTTGGCGAAAGCATGCAA |
| Microexon-tag Amino Acid Seq | APNRESFFRSHPQDKDGSQGKVEVSSVVYKVGESMQ |
| Microexon-tag spanning region | 40983355-40984059 |
| Microexon-tag prediction score | 0.9185 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | KRH34314x |
| Reference Transcript ID | KRH34314 |
| Gene ID | GLYMA_10G175900 |
| Gene Name | NA |
| Transcript ID | KRH34314 |
| Protein ID | KRH34314 |
| Gene ID | GLYMA_10G175900 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >KRH34314 MSGAPKRSHEESVHSSSKHPNEDLGTYSKLVSSSVSNEYHMPHDITQDSRVAKVPRTEFHDADRRSPLNPVYRMSSPLND SRTDHPIGPENRIESRDSKDNRDLRFENRDTKTEKKELHGEARRDPPSAKSEKDVRVEGRGDDNKDVRHDRDSHNDPKGD TKTEKDGYNVVSSHLNWKDSKEYHRGKRYSDSPGGNWDTWHMSRGNTQGSVEVGKESSAAGERDHVEAHEAVCENKVDPK GDDRSKEKDRKRKDVKHREWGDREKERSDRRNSPQVTNSTGDCKESAKEDRDVERLEREKKDLPKEKENLTERERDQMKR ESWNGMEKEVSNNEKESVDASDKLTEQEIVLPEQKKQKEVDSWKNVDREARERRKERDADLEGDRSDKRTKGLDKESNDG CADVEGVMEKEREVYNYSSQHRKRIQRSRGSPQAPNRESFFRSHPQDKDGSQGKVEVSSVVYKVGESMQELIKLWKEHES SQSEMEKNGESSNNGPTLEIRIPSEHVTATNRQVRGGQLWGTDVYTYDSDLVAVLMHTGYCRPTASPPHAAIQELRATVR VLPPQDCYISTLRNNIRSRAWGAAIGCSYRVERCCIVKKGGDTIDLEPCLTHTSTIEPTLAPVTVERTMTTRAAASNALR QQRFVREVTIQYNLCNEPWIKYSISTVADKGLKKPLYTSARLKKGEVLYLETHLSRYELCFTGEKMVKVTPATQLHDPVT EKSQNHHPHSTNGEKNDCENVMIDAFRWSRCKKPLPQKLMRTIGIPLPIEHIELLEENLDWEDVQWSQTGVWIAGKEYTL ARVHFLSMN* |
| CDS seq | >KRH34314 ATGAGTGGTGCACCTAAGAGATCTCATGAAGAGTCTGTTCATTCATCTTCAAAGCACCCGAATGAAGATTTGGGTACATA TTCCAAGTTGGTTTCATCGTCAGTTTCAAATGAGTACCATATGCCTCATGATATAACTCAGGACTCCCGGGTGGCAAAAG TGCCTCGAACTGAATTTCATGATGCAGATAGAAGATCTCCTCTTAATCCTGTGTATCGGATGTCGTCACCGTTGAATGAT TCTCGTACAGATCATCCTATTGGCCCTGAGAACAGGATTGAATCAAGGGATTCCAAGGACAATAGAGATCTCCGGTTTGA GAACCGCGATACAAAGACAGAGAAGAAGGAGTTGCATGGTGAAGCAAGAAGGGATCCTCCAAGTGCTAAGAGTGAAAAGG ATGTGCGTGTTGAAGGTAGAGGAGATGACAACAAGGATGTCAGGCATGATCGGGATAGTCATAATGATCCGAAAGGTGAC ACCAAGACAGAGAAAGATGGTTATAATGTGGTTAGCAGCCACTTGAATTGGAAAGATTCAAAAGAGTACCATAGAGGAAA AAGATATTCTGATTCCCCTGGTGGGAATTGGGACACATGGCATATGTCACGTGGAAATACACAAGGCTCAGTTGAGGTTG GGAAGGAGAGTTCAGCAGCAGGAGAAAGAGATCATGTTGAAGCTCATGAAGCTGTTTGTGAGAACAAAGTTGATCCTAAA GGTGATGATAGATCTAAAGAGAAAGATAGAAAGAGGAAGGATGTGAAGCATAGGGAATGGGGAGATAGGGAAAAAGAAAG AAGTGATCGTAGAAACAGTCCACAAGTAACAAACAGTACCGGTGACTGCAAAGAATCTGCCAAGGAAGATAGAGATGTAG AAAGGTTGGAGAGGGAGAAAAAAGATCTTCCAAAAGAGAAAGAAAATTTAACAGAGAGGGAAAGGGATCAGATGAAGAGA GAATCATGGAATGGAATGGAGAAAGAGGTTTCAAATAACGAGAAGGAATCTGTTGATGCATCAGATAAACTAACTGAACA AGAAATTGTGTTACCAGAGCAGAAGAAACAAAAAGAAGTTGATAGCTGGAAAAATGTAGATAGAGAAGCTAGAGAGAGGA GAAAAGAAAGGGATGCTGATTTAGAAGGGGATAGGTCTGATAAACGTACCAAGGGCCTTGACAAGGAATCAAACGATGGG TGTGCTGATGTAGAAGGGGTGATGGAGAAGGAGAGGGAGGTCTATAATTATAGCAGTCAGCACCGTAAGAGGATACAACG ATCTAGGGGAAGCCCTCAGGCGCCGAACCGGGAGTCTTTTTTCAGATCCCATCCCCAAGACAAAGACGGGTCTCAAGGTA AAGTAGAAGTTTCTTCTGTTGTTTATAAAGTTGGCGAAAGCATGCAAGAACTGATAAAGTTGTGGAAGGAACATGAATCA TCTCAATCTGAAATGGAGAAAAATGGTGAAAGCTCTAATAATGGTCCCACTCTGGAAATTCGGATACCATCTGAGCATGT AACGGCTACAAACCGCCAAGTCAGAGGTGGCCAGCTTTGGGGGACCGATGTGTACACATACGATTCAGATCTTGTTGCTG TTCTCATGCATACCGGTTACTGTCGCCCAACAGCATCTCCACCTCATGCAGCCATACAAGAATTGCGTGCAACTGTCCGT GTGCTACCTCCTCAAGATTGCTATATTTCTACACTGAGAAACAACATACGTTCCCGTGCTTGGGGTGCAGCAATTGGTTG TAGTTATAGAGTTGAGCGGTGTTGCATTGTGAAGAAAGGAGGTGATACTATTGATCTTGAACCTTGCCTTACACATACAT CAACTATTGAACCCACCCTTGCTCCAGTGACTGTTGAGCGGACAATGACTACCAGGGCTGCAGCTTCGAATGCATTGCGG CAACAAAGATTTGTTCGAGAAGTCACAATACAGTACAATCTCTGCAATGAGCCATGGATAAAATATAGTATAAGCACTGT CGCGGACAAGGGTTTAAAAAAGCCACTCTACACATCTGCTCGTTTGAAGAAGGGAGAAGTTTTGTATTTGGAGACACATT TGTCCAGATATGAACTTTGTTTTACTGGAGAGAAGATGGTCAAGGTTACACCAGCAACCCAGTTGCATGACCCTGTCACA GAAAAGTCTCAAAATCACCACCCACATTCTACAAATGGTGAAAAAAATGATTGTGAGAATGTCATGATTGATGCATTCAG GTGGTCTCGTTGTAAGAAGCCTCTGCCACAGAAACTGATGCGTACAATTGGCATCCCTTTGCCTATTGAACATATAGAGT TACTGGAGGAAAATTTGGACTGGGAAGATGTGCAATGGTCGCAAACAGGTGTTTGGATTGCTGGAAAGGAATATACCTTG GCACGAGTGCATTTCTTGTCAATGAATTAA |
| Microexon DNA seq | GTCTCAAG |
| Microexon Amino Acid seq | GSQG |
| Microexon-tag DNA Seq | GCGCCGAACCGGGAGTCTTTTTTCAGATCCCATCCCCAAGACAAAGACGGGTCTCAAGGTAAAGTAGAAGTTTCTTCTGTTGTTTATAAAGTTGGCGAAAGCATGCAA |
| Microexon-tag Amino Acid seq | APNRESFFRSHPQDKDGSQGKVEVSSVVYKVGESMQ |
| Transcript ID | Gm.4071.1 |
| Gene ID | Gm.4071 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >Gm.4071.1 MSGAPKRSHEESVHSSSKHPNEDLGTYSKLVSSSVSNEYHMPHDITQDSRVAKVPRTEFHDADRRSPLNPVYRMSSPLND SRTDHPIGPENRIESRDSKDNRDLRFENRDTKTEKKELHGEARRDPPSAKSEKDVRVEGRGDDNKDVRHDRDSHNDPKGD TKTEKDGYNVVSSHLNWKDSKEYHRGKRYSDSPGGNWDTWHMSRGNTQGSVEVGKESSAAGERDHVEAHEAVCENKVDPK GDDRSKEKDRKRKDVKHREWGDREKERSDRRNSPQVTNSTGDCKESAKEDRDVERLEREKKDLPKEKENLTERERDQMKR ESWNGMEKEVSNNEKESVDASDKLTEQEIVLPEQKKQKEVDSWKNVDREARERRKERDADLEGDRSDKRTKGLDKESNDG CADVEGVMEKEREVYNYSSQHRKRIQRSRGSPQAPNRESFFRSHPQDKDGSQGKVEVSSVVYKVGESMQELIKLWKEHES SQSEMEKNGESSNNGPTLEIRIPSEHVTATNRQVRGGQLWGTDVYTYDSDLVAVLMHTGYCRPTASPPHAAIQELRATVR VLPPQDCYISTLRNNIRSRAWGAAIGCSYRVERCCIVKKGGDTIDLEPCLTHTSTIEPTLAPVTVERTMTTRAAASNALR QQRFVREVTIQYNLCNEPWIKYSISTVADKGLKKPLYTSARLKKGEVLYLETHLSRYELCFTGEKMVKVTPATQLHDPVT EKSQNHHPHSTNGEKNDCENVMIDAFRWSRCKKPLPQKLMRTIGIPLPIEHIELLEENLDWEDVQWSQTGVWIAGKEYTL ARVHFLSMN* |
| CDS seq | >Gm.4071.1 ATGAGTGGTGCACCTAAGAGATCTCATGAAGAGTCTGTTCATTCATCTTCAAAGCACCCGAATGAAGATTTGGGTACATA TTCCAAGTTGGTTTCATCGTCAGTTTCAAATGAGTACCATATGCCTCATGATATAACTCAGGACTCCCGGGTGGCAAAAG TGCCTCGAACTGAATTTCATGATGCAGATAGAAGATCTCCTCTTAATCCTGTGTATCGGATGTCGTCACCGTTGAATGAT TCTCGTACAGATCATCCTATTGGCCCTGAGAACAGGATTGAATCAAGGGATTCCAAGGACAATAGAGATCTCCGGTTTGA GAACCGCGATACAAAGACAGAGAAGAAGGAGTTGCATGGTGAAGCAAGAAGGGATCCTCCAAGTGCTAAGAGTGAAAAGG ATGTGCGTGTTGAAGGTAGAGGAGATGACAACAAGGATGTCAGGCATGATCGGGATAGTCATAATGATCCGAAAGGTGAC ACCAAGACAGAGAAAGATGGTTATAATGTGGTTAGCAGCCACTTGAATTGGAAAGATTCAAAAGAGTACCATAGAGGAAA AAGATATTCTGATTCCCCTGGTGGGAATTGGGACACATGGCATATGTCACGTGGAAATACACAAGGCTCAGTTGAGGTTG GGAAGGAGAGTTCAGCAGCAGGAGAAAGAGATCATGTTGAAGCTCATGAAGCTGTTTGTGAGAACAAAGTTGATCCTAAA GGTGATGATAGATCTAAAGAGAAAGATAGAAAGAGGAAGGATGTGAAGCATAGGGAATGGGGAGATAGGGAAAAAGAAAG AAGTGATCGTAGAAACAGTCCACAAGTAACAAACAGTACCGGTGACTGCAAAGAATCTGCCAAGGAAGATAGAGATGTAG AAAGGTTGGAGAGGGAGAAAAAAGATCTTCCAAAAGAGAAAGAAAATTTAACAGAGAGGGAAAGGGATCAGATGAAGAGA GAATCATGGAATGGAATGGAGAAAGAGGTTTCAAATAACGAGAAGGAATCTGTTGATGCATCAGATAAACTAACTGAACA AGAAATTGTGTTACCAGAGCAGAAGAAACAAAAAGAAGTTGATAGCTGGAAAAATGTAGATAGAGAAGCTAGAGAGAGGA GAAAAGAAAGGGATGCTGATTTAGAAGGGGATAGGTCTGATAAACGTACCAAGGGCCTTGACAAGGAATCAAACGATGGG TGTGCTGATGTAGAAGGGGTGATGGAGAAGGAGAGGGAGGTCTATAATTATAGCAGTCAGCACCGTAAGAGGATACAACG ATCTAGGGGAAGCCCTCAGGCGCCGAACCGGGAGTCTTTTTTCAGATCCCATCCCCAAGACAAAGACGGGTCTCAAGGTA AAGTAGAAGTTTCTTCTGTTGTTTATAAAGTTGGCGAAAGCATGCAAGAACTGATAAAGTTGTGGAAGGAACATGAATCA TCTCAATCTGAAATGGAGAAAAATGGTGAAAGCTCTAATAATGGTCCCACTCTGGAAATTCGGATACCATCTGAGCATGT AACGGCTACAAACCGCCAAGTCAGAGGTGGCCAGCTTTGGGGGACCGATGTGTACACATACGATTCAGATCTTGTTGCTG TTCTCATGCATACCGGTTACTGTCGCCCAACAGCATCTCCACCTCATGCAGCCATACAAGAATTGCGTGCAACTGTCCGT GTGCTACCTCCTCAAGATTGCTATATTTCTACACTGAGAAACAACATACGTTCCCGTGCTTGGGGTGCAGCAATTGGTTG TAGTTATAGAGTTGAGCGGTGTTGCATTGTGAAGAAAGGAGGTGATACTATTGATCTTGAACCTTGCCTTACACATACAT CAACTATTGAACCCACCCTTGCTCCAGTGACTGTTGAGCGGACAATGACTACCAGGGCTGCAGCTTCGAATGCATTGCGG CAACAAAGATTTGTTCGAGAAGTCACAATACAGTACAATCTCTGCAATGAGCCATGGATAAAATATAGTATAAGCACTGT CGCGGACAAGGGTTTAAAAAAGCCACTCTACACATCTGCTCGTTTGAAGAAGGGAGAAGTTTTGTATTTGGAGACACATT TGTCCAGATATGAACTTTGTTTTACTGGAGAGAAGATGGTCAAGGTTACACCAGCAACCCAGTTGCATGACCCTGTCACA GAAAAGTCTCAAAATCACCACCCACATTCTACAAATGGTGAAAAAAATGATTGTGAGAATGTCATGATTGATGCATTCAG GTGGTCTCGTTGTAAGAAGCCTCTGCCACAGAAACTGATGCGTACAATTGGCATCCCTTTGCCTATTGAACATATAGAGT TACTGGAGGAAAATTTGGACTGGGAAGATGTGCAATGGTCGCAAACAGGTGTTTGGATTGCTGGAAAGGAATATACCTTG GCACGAGTGCATTTCTTGTCAATGAATTAA |