| Microexon ID | Ps_NW_020622381.1:11907329-11907334:- |
| Species | Papaver somniferum | Coordinates | NW_020622381.1:11907329..11907334 |
| Microexon Cluster ID | MEP12 |
| Size | 6 |
| Phase | 1 |
| Pfam Domain Motif | Unknown |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 52,6,50 |
| Microexon location in the Microexon-tag | 2 |
| Microexon-tag DNA Seq | GAAGAMCRTGTKCGKGAGGATKTKCARAAGTWYYCWAGRGGWTCYCCACAAGCWAGAGCTTATSGKAATGATGGMRCWMRRRGYCGWTCAASMCATTCAAAATCTCCM |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 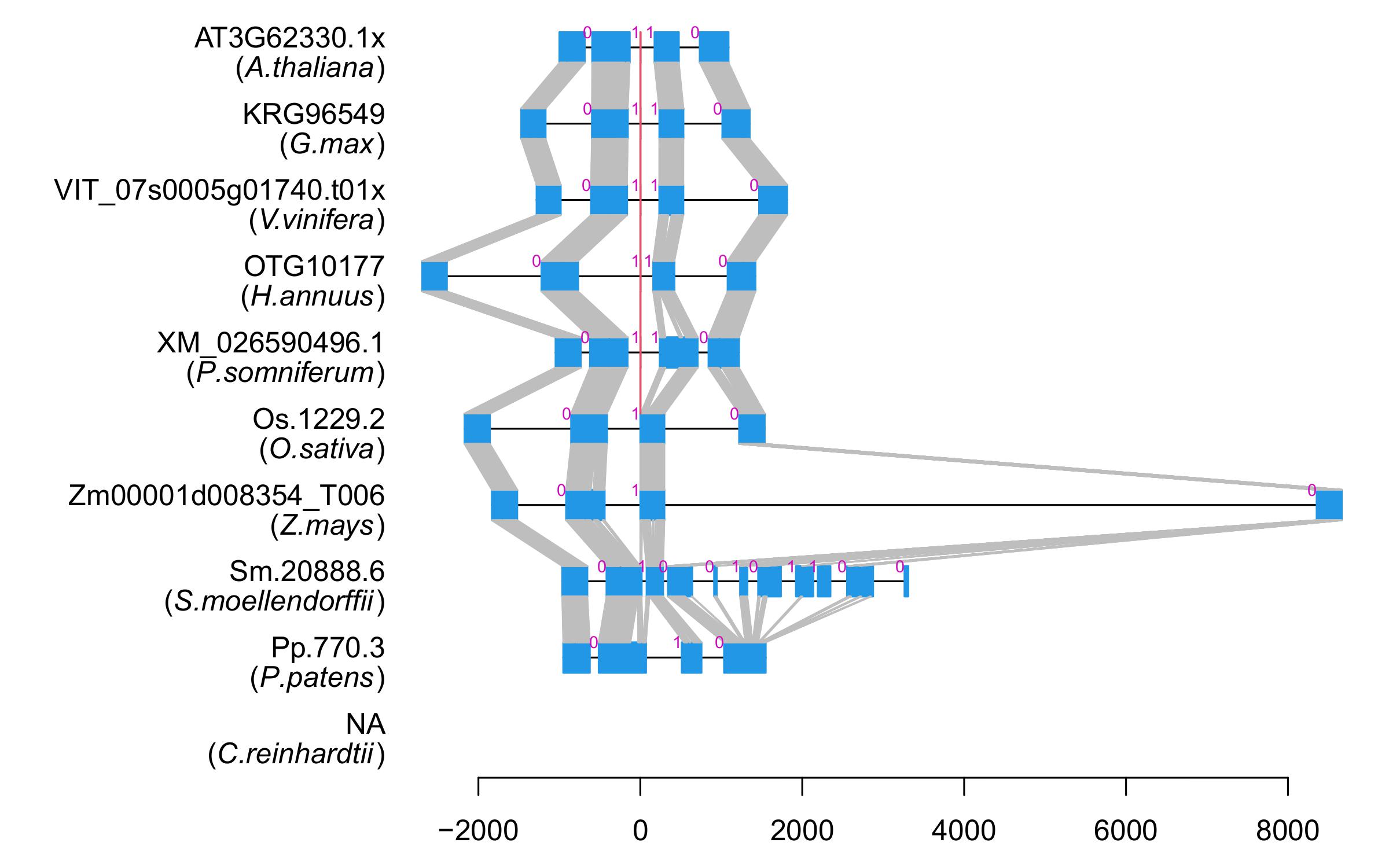 |
Ps_NW_020622381.1:11907329-11907334:- does not have available information here.
| Transcript ID | XM_026579642.1 |
| Protein ID | XP_026435427.1 |
| Gene ID | LOC113333137 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026435427.1 MEREPSPDVDDDFDDIYKEYTGPPGSNTAAAATAQEKPKVPKRSHTSSDEEDETRDPNAVPTDFTSREAKVWEAKSKATE RNWKKRKEEEMICKICGESGHFTQGCPSTLGANRKTQDFFERVAARDSQVRALFTEKVIQRIEKDIGCKIKMDEKFIIVS GKDRLCLSKGVDAVHKVKEEGNGNSKNQRGSTSSRRSRSRSPADGGRAGSRTGRSEPPRSSGHSPRKTTQLPQKFGRPEK VVEEHIREDVQKFSRGSPRARAFRNGVRGRSSHSRSPGRPPYANNAGSNPYDDRARVRSSHSRSPGRPPYANNAASAPYG DGARVRSTHSRSPGQPTFASNAASNPYDGHTHVIGSSRPDGWNIEKRVPEVNPGGGRFEFPAYPKTLEELELEYKREAME LSRARDNEEDEENYKHREHIREMRENYMKKMAIQRGMHAKQWEEFLQLDIQRREQQAARQLSLAQGYSTGGSGRYGRPGY QDYDPSAGGNAHYGGASLPAVAIRDKYPYPVESYTPSRAHDVYSSGDFQRQRHEDYGKTYNRY* |
| CDS seq | >XM_026579642.1 ATGGAAAGAGAACCATCGCCGGATGTCGATGATGATTTCGATGACATTTACAAGGAATATACTGGTCCACCTGGATCAAA TACAGCAGCAGCAGCCACTGCGCAAGAGAAACCTAAAGTTCCCAAAAGGTCTCATACCTCCTCTGATGAAGAAGATGAAA CTCGTGACCCTAATGCTGTACCTACTGATTTCACTAGTCGTGAAGCTAAAGTTTGGGAAGCTAAATCAAAAGCTACGGAA CGAAATTGGAAGAAACGGAAAGAAGAAGAAATGATTTGCAAAATTTGTGGTGAATCTGGTCACTTTACTCAGGGATGTCC ATCTACGCTGGGAGCAAATCGCAAGACGCAAGATTTCTTTGAAAGGGTTGCGGCCAGAGATAGCCAAGTACGAGCGCTGT TTACTGAAAAGGTAATTCAAAGGATTGAAAAGGATATTGGGTGCAAAATTAAAATGGATGAGAAGTTTATAATAGTAAGT GGGAAAGATAGACTATGTCTGTCAAAAGGCGTGGATGCTGTGCACAAAGTGAAGGAAGAGGGGAATGGTAATAGTAAAAA TCAAAGAGGTTCGACTAGTTCACGAAGGAGCAGGTCAAGATCTCCTGCTGATGGAGGTCGTGCTGGTTCACGCACTGGGC GTTCTGAACCTCCAAGGTCATCTGGTCATAGTCCACGCAAAACAACACAGTTACCTCAAAAGTTTGGGAGACCAGAGAAG GTCGTAGAGGAACATATTCGCGAGGATGTGCAGAAGTTTTCTAGAGGTTCTCCACGAGCAAGAGCTTTTCGAAATGGGGT TAGAGGTCGTTCAAGTCATTCAAGATCTCCTGGACGGCCACCTTATGCAAACAATGCTGGCTCTAATCCGTATGATGATA GAGCTAGAGTTCGTTCAAGTCATTCGAGATCTCCTGGACGGCCACCTTATGCCAACAATGCTGCCTCCGCCCCTTATGGT GATGGAGCTAGAGTTCGTTCAACTCATTCAAGATCTCCTGGACAGCCAACTTTTGCCAGCAATGCTGCCTCTAATCCATA TGATGGTCATACACATGTCATTGGCTCCAGTAGACCTGATGGGTGGAATATTGAGAAACGCGTACCAGAGGTGAATCCTG GTGGTGGGAGGTTTGAATTCCCTGCATATCCAAAAACACTGGAAGAACTAGAATTGGAATATAAGAGAGAGGCAATGGAA CTTAGTAGAGCACGTGATAACGAAGAAGATGAAGAGAATTACAAGCATAGGGAGCATATTCGGGAAATGAGAGAGAATTA CATGAAGAAAATGGCTATTCAACGGGGGATGCATGCAAAGCAGTGGGAAGAGTTCCTTCAACTTGATATCCAGAGGCGGG AGCAACAAGCAGCACGCCAGCTATCTTTGGCACAAGGATATAGTACTGGTGGCAGTGGTCGCTATGGTCGGCCTGGTTAC CAAGACTATGACCCATCTGCAGGAGGCAATGCCCACTATGGTGGAGCCAGTTTACCTGCCGTGGCCATAAGGGATAAGTA CCCATATCCAGTTGAAAGCTATACTCCGTCGAGGGCTCATGATGTGTACAGCAGTGGTGATTTTCAACGCCAAAGACATG AGGATTATGGAAAAACGTACAATCGGTACTGA |
| Microexon DNA seq | CAAGAG |
| Microexon Amino Acid seq | ARA |
| Microexon-tag DNA Seq | GAGGAACATATTCGCGAGGATGTGCAGAAGTTTTCTAGAGGTTCTCCACGAGCAAGAGCTTTTCGAAATGGGGTTAGAGGTCGTTCAAGTCATTCAAGATCTCCTGGA |
| Microexon-tag Amino Acid seq | EEHIREDVQKFSRGSPRARAFRNGVRGRSSHSRSPG |
| Transcript ID | XM_026579642.1 |
| Gene ID | Ps.73954 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026579642.1 MEREPSPDVDDDFDDIYKEYTGPPGSNTAAAATAQEKPKVPKRSHTSSDEEDETRDPNAVPTDFTSREAKVWEAKSKATE RNWKKRKEEEMICKICGESGHFTQGCPSTLGANRKTQDFFERVAARDSQVRALFTEKVIQRIEKDIGCKIKMDEKFIIVS GKDRLCLSKGVDAVHKVKEEGNGNSKNQRGSTSSRRSRSRSPADGGRAGSRTGRSEPPRSSGHSPRKTTQLPQKFGRPEK VVEEHIREDVQKFSRGSPRARAFRNGVRGRSSHSRSPGRPPYANNAGSNPYDDRARVRSSHSRSPGRPPYANNAASAPYG DGARVRSTHSRSPGQPTFASNAASNPYDGHTHVIGSSRPDGWNIEKRVPEVNPGGGRFEFPAYPKTLEELELEYKREAME LSRARDNEEDEENYKHREHIREMRENYMKKMAIQRGMHAKQWEEFLQLDIQRREQQAARQLSLAQGYSTGGSGRYGRPGY QDYDPSAGGNAHYGGASLPAVAIRDKYPYPVESYTPSRAHDVYSSGDFQRQRHEDYGKTYNRY* |
| CDS seq | >XM_026579642.1 ATGGAAAGAGAACCATCGCCGGATGTCGATGATGATTTCGATGACATTTACAAGGAATATACTGGTCCACCTGGATCAAA TACAGCAGCAGCAGCCACTGCGCAAGAGAAACCTAAAGTTCCCAAAAGGTCTCATACCTCCTCTGATGAAGAAGATGAAA CTCGTGACCCTAATGCTGTACCTACTGATTTCACTAGTCGTGAAGCTAAAGTTTGGGAAGCTAAATCAAAAGCTACGGAA CGAAATTGGAAGAAACGGAAAGAAGAAGAAATGATTTGCAAAATTTGTGGTGAATCTGGTCACTTTACTCAGGGATGTCC ATCTACGCTGGGAGCAAATCGCAAGACGCAAGATTTCTTTGAAAGGGTTGCGGCCAGAGATAGCCAAGTACGAGCGCTGT TTACTGAAAAGGTAATTCAAAGGATTGAAAAGGATATTGGGTGCAAAATTAAAATGGATGAGAAGTTTATAATAGTAAGT GGGAAAGATAGACTATGTCTGTCAAAAGGCGTGGATGCTGTGCACAAAGTGAAGGAAGAGGGGAATGGTAATAGTAAAAA TCAAAGAGGTTCGACTAGTTCACGAAGGAGCAGGTCAAGATCTCCTGCTGATGGAGGTCGTGCTGGTTCACGCACTGGGC GTTCTGAACCTCCAAGGTCATCTGGTCATAGTCCACGCAAAACAACACAGTTACCTCAAAAGTTTGGGAGACCAGAGAAG GTCGTAGAGGAACATATTCGCGAGGATGTGCAGAAGTTTTCTAGAGGTTCTCCACGAGCAAGAGCTTTTCGAAATGGGGT TAGAGGTCGTTCAAGTCATTCAAGATCTCCTGGACGGCCACCTTATGCAAACAATGCTGGCTCTAATCCGTATGATGATA GAGCTAGAGTTCGTTCAAGTCATTCGAGATCTCCTGGACGGCCACCTTATGCCAACAATGCTGCCTCCGCCCCTTATGGT GATGGAGCTAGAGTTCGTTCAACTCATTCAAGATCTCCTGGACAGCCAACTTTTGCCAGCAATGCTGCCTCTAATCCATA TGATGGTCATACACATGTCATTGGCTCCAGTAGACCTGATGGGTGGAATATTGAGAAACGCGTACCAGAGGTGAATCCTG GTGGTGGGAGGTTTGAATTCCCTGCATATCCAAAAACACTGGAAGAACTAGAATTGGAATATAAGAGAGAGGCAATGGAA CTTAGTAGAGCACGTGATAACGAAGAAGATGAAGAGAATTACAAGCATAGGGAGCATATTCGGGAAATGAGAGAGAATTA CATGAAGAAAATGGCTATTCAACGGGGGATGCATGCAAAGCAGTGGGAAGAGTTCCTTCAACTTGATATCCAGAGGCGGG AGCAACAAGCAGCACGCCAGCTATCTTTGGCACAAGGATATAGTACTGGTGGCAGTGGTCGCTATGGTCGGCCTGGTTAC CAAGACTATGACCCATCTGCAGGAGGCAATGCCCACTATGGTGGAGCCAGTTTACCTGCCGTGGCCATAAGGGATAAGTA CCCATATCCAGTTGAAAGCTATACTCCGTCGAGGGCTCATGATGTGTACAGCAGTGGTGATTTTCAACGCCAAAGACATG AGGATTATGGAAAAACGTACAATCGGTACTGA |