| Microexon ID | Ps_NC_039367.1:54301721-54301725:- |
| Species | Papaver somniferum | Coordinates | NC_039367.1:54301721..54301725 |
| Microexon Cluster ID | MEP09 |
| Size | 5 |
| Phase | 2 |
| Pfam Domain Motif | SKG6 |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 19,34,5,50 |
| Microexon location in the Microexon-tag | 3 |
| Microexon-tag DNA Seq | GTDTWYATTCCDGSMMRAGATSAAAATGGAARYTATCSRCCCYTRMMAWCMAGCWCAGGAWTATCARGTGGAGYYATWGSTGGMATAKYTRTAGSAGYAGTAGYWGKR |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 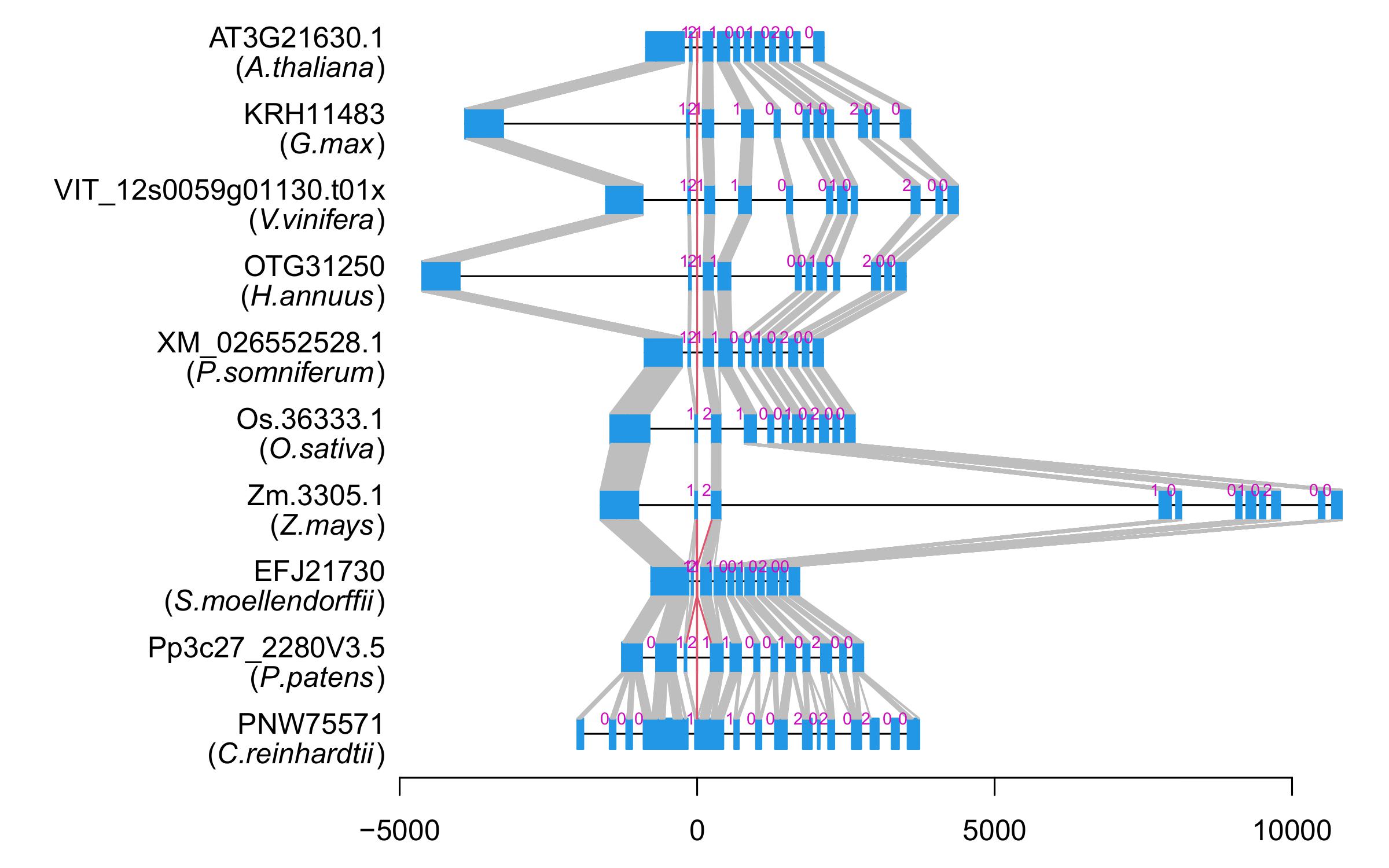 |
| Microexon DNA seq | CACAG |
| Microexon Amino Acid seq | STG |
| Microexon-tag DNA Seq | GTGTTTATTCCTGGCAAAGATGCAACGGGAAGCTACCCACGCTTGAAACCGAGCACAGGACTTCCTGCTGGAGCCATTGTTGGAATAGCAGTTGGGATAGTAGCTTTT |
| Microexon-tag Amino Acid Seq | VFIPGKDATGSYPRLKPSTGLPAGAIVGIAVGIVAF |
| Microexon-tag spanning region | 54301569-54302824 |
| Microexon-tag prediction score | 0.8854 |
| Overlapped with the annotated transcript (%) | 97.3 |
| New Transcript ID | XM_026566667.1x |
| Reference Transcript ID | XM_026566667.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026566667.1 |
| Protein ID | XP_026422452.1 |
| Gene ID | LOC113318498 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026422452.1 MVPIGRRRMKRKGEIEFELGLVFLGILFLFSSIGGVECQCRRGCDLALASYEIWAGTNLTFTSQIFNTNDQEILKYNRQV PNKDLIVAGERLNVPFTCDCLEEQRLGHNFTYILKPGGTYEKIVKYYANLTTVGDLTRENKYDNPNNILDGSLVNIIVNC SCGDEKVDDYGLFVTYPLLPGDNLSSIAKQFNISSDLVGRYNLNTDFSSGKGLVFIPGKDATGSYPRLKPSTGGLPAGAI VGIAVGIVAFALLLAVCTYIGLSRRKKAKKALLLSETSEGSRGNFNKSVELASPTALASPRVTGITVDKSVEFTYEELAR ATDDFSLANKIGQGGFGAVYYAELRGEKAAIKKMDMQASKEFLAELKVLTRVHHLNLVRLIGYCVEGSLFLVYEFIDSGN LSEHLRGTEKEPLPWSTRVYIALDSARGLEYIHEHTVPVYIHRDIKSANILVDRNFRGKVADFGLTKLTEVGSGSLQTRV VGTFGYMPPEYAQWGDITPKVDVYAFGVVLYELISAKEAVVRSNGSSVESRGLVSMFEEVLNQPDSNEDLRKLVDPRLGD NYPFDSVRKLAQLAKACTHENPQLRPTMRSIVVALMTLSSSTEDWDVGSFYENHGLVNLMSGR* |
| CDS seq | >XM_026566667.1 ATGGTACCTATAGGAAGAAGAAGAATGAAGAGAAAAGGGGAAATTGAGTTTGAACTAGGGTTAGTGTTTCTGGGGATATT GTTCTTATTTTCGAGTATTGGAGGAGTAGAATGCCAGTGCAGAAGGGGATGTGATCTCGCTTTAGCTTCTTATGAAATAT GGGCAGGTACAAACCTTACATTCACTTCACAAATTTTTAATACTAATGACCAGGAGATTCTCAAATACAATCGTCAAGTT CCTAACAAAGATCTTATTGTAGCTGGTGAAAGATTGAATGTCCCTTTTACATGTGATTGCCTTGAGGAACAACGTTTAGG TCATAATTTTACTTATATTCTTAAACCTGGTGGTACTTATGAAAAAATTGTGAAATATTACGCTAATCTTACTACTGTTG GGGATTTGACGAGAGAAAACAAATATGATAATCCTAACAATATACTTGATGGCTCCCTGGTAAATATCATTGTAAATTGC TCTTGTGGAGATGAAAAGGTGGATGATTATGGGTTGTTCGTGACTTATCCTTTACTTCCCGGTGATAACTTGAGTTCTAT TGCTAAGCAATTCAATATCAGTTCTGATTTGGTGGGGAGATACAACCTGAACACGGATTTCAGCAGCGGGAAGGGACTGG TGTTTATTCCTGGCAAAGATGCAACGGGAAGCTACCCACGCTTGAAACCGAGCACAGGAGGACTTCCTGCTGGAGCCATT GTTGGAATAGCAGTTGGGATAGTAGCTTTTGCACTATTATTGGCAGTTTGTACATATATTGGACTTTCTAGAAGGAAAAA GGCAAAGAAGGCATTATTGCTCTCCGAAACATCTGAAGGTTCTCGAGGCAACTTTAATAAATCAGTCGAATTAGCTTCTC CAACCGCCCTTGCTTCGCCTAGGGTTACAGGTATCACGGTGGATAAATCAGTGGAGTTTACGTATGAAGAGCTCGCCAGA GCAACCGATGACTTCAGTTTGGCTAATAAAATTGGTCAAGGTGGCTTTGGAGCTGTTTACTACGCTGAGCTTAGAGGCGA GAAAGCTGCAATCAAGAAGATGGATATGCAAGCATCAAAAGAGTTCCTCGCGGAACTGAAAGTTCTTACTCGTGTTCATC ACTTGAATCTGGTGCGCTTGATTGGATATTGTGTCGAGGGTTCTTTGTTCTTAGTGTACGAGTTCATTGACAGTGGAAAC CTAAGTGAACATTTACGTGGAACAGAGAAGGAACCATTGCCGTGGTCCACAAGGGTGTACATTGCTCTCGATTCTGCAAG AGGTCTTGAATACATCCACGAGCACACAGTTCCTGTTTACATTCATCGTGATATCAAATCTGCAAACATTCTGGTAGACA GAAACTTCCGCGGAAAGGTTGCAGATTTTGGGTTAACAAAGCTAACTGAAGTTGGAAGTGGATCCTTGCAAACACGGGTT GTGGGTACATTTGGATACATGCCGCCTGAGTATGCTCAATGGGGTGACATCACCCCCAAGGTTGATGTCTATGCTTTCGG GGTTGTCCTGTATGAACTTATATCAGCAAAAGAAGCCGTGGTTAGGTCAAATGGTTCCAGTGTTGAATCAAGAGGACTCG TCTCTATGTTTGAAGAAGTTCTTAATCAACCCGATTCGAATGAAGATCTTCGCAAACTAGTCGACCCTAGGCTTGGAGAC AACTACCCTTTTGATTCAGTCCGCAAGTTAGCTCAACTTGCAAAAGCTTGCACGCACGAGAATCCCCAATTGAGACCTAC CATGAGGTCAATTGTGGTCGCATTAATGACACTTTCATCATCAACAGAGGATTGGGATGTTGGCTCCTTCTACGAAAACC ACGGTCTAGTGAATCTAATGTCAGGAAGGTAA |
| Microexon DNA seq | CACAG |
| Microexon Amino Acid seq | STG |
| Microexon-tag DNA Seq | GTGTTTATTCCTGGCAAAGATGCAACGGGAAGCTACCCACGCTTGAAACCGAGCACAGGAGGACTTCCTGCTGGAGCCATTGTTGGAATAGCAGTTGGGATAGTAGCT |
| Microexon-tag Amino Acid seq | VFIPGKDATGSYPRLKPSTGGLPAGAIVGIAVGIVA |
| Transcript ID | XM_026566667.1 |
| Gene ID | Ps.60903 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026566667.1 MVPIGRRRMKRKGEIEFELGLVFLGILFLFSSIGGVECQCRRGCDLALASYEIWAGTNLTFTSQIFNTNDQEILKYNRQV PNKDLIVAGERLNVPFTCDCLEEQRLGHNFTYILKPGGTYEKIVKYYANLTTVGDLTRENKYDNPNNILDGSLVNIIVNC SCGDEKVDDYGLFVTYPLLPGDNLSSIAKQFNISSDLVGRYNLNTDFSSGKGLVFIPGKDATGSYPRLKPSTGGLPAGAI VGIAVGIVAFALLLAVCTYIGLSRRKKAKKALLLSETSEGSRGNFNKSVELASPTALASPRVTGITVDKSVEFTYEELAR ATDDFSLANKIGQGGFGAVYYAELRGEKAAIKKMDMQASKEFLAELKVLTRVHHLNLVRLIGYCVEGSLFLVYEFIDSGN LSEHLRGTEKEPLPWSTRVYIALDSARGLEYIHEHTVPVYIHRDIKSANILVDRNFRGKVADFGLTKLTEVGSGSLQTRV VGTFGYMPPEYAQWGDITPKVDVYAFGVVLYELISAKEAVVRSNGSSVESRGLVSMFEEVLNQPDSNEDLRKLVDPRLGD NYPFDSVRKLAQLAKACTHENPQLRPTMRSIVVALMTLSSSTEDWDVGSFYENHGLVNLMSGR* |
| CDS seq | >XM_026566667.1 ATGGTACCTATAGGAAGAAGAAGAATGAAGAGAAAAGGGGAAATTGAGTTTGAACTAGGGTTAGTGTTTCTGGGGATATT GTTCTTATTTTCGAGTATTGGAGGAGTAGAATGCCAGTGCAGAAGGGGATGTGATCTCGCTTTAGCTTCTTATGAAATAT GGGCAGGTACAAACCTTACATTCACTTCACAAATTTTTAATACTAATGACCAGGAGATTCTCAAATACAATCGTCAAGTT CCTAACAAAGATCTTATTGTAGCTGGTGAAAGATTGAATGTCCCTTTTACATGTGATTGCCTTGAGGAACAACGTTTAGG TCATAATTTTACTTATATTCTTAAACCTGGTGGTACTTATGAAAAAATTGTGAAATATTACGCTAATCTTACTACTGTTG GGGATTTGACGAGAGAAAACAAATATGATAATCCTAACAATATACTTGATGGCTCCCTGGTAAATATCATTGTAAATTGC TCTTGTGGAGATGAAAAGGTGGATGATTATGGGTTGTTCGTGACTTATCCTTTACTTCCCGGTGATAACTTGAGTTCTAT TGCTAAGCAATTCAATATCAGTTCTGATTTGGTGGGGAGATACAACCTGAACACGGATTTCAGCAGCGGGAAGGGACTGG TGTTTATTCCTGGCAAAGATGCAACGGGAAGCTACCCACGCTTGAAACCGAGCACAGGAGGACTTCCTGCTGGAGCCATT GTTGGAATAGCAGTTGGGATAGTAGCTTTTGCACTATTATTGGCAGTTTGTACATATATTGGACTTTCTAGAAGGAAAAA GGCAAAGAAGGCATTATTGCTCTCCGAAACATCTGAAGGTTCTCGAGGCAACTTTAATAAATCAGTCGAATTAGCTTCTC CAACCGCCCTTGCTTCGCCTAGGGTTACAGGTATCACGGTGGATAAATCAGTGGAGTTTACGTATGAAGAGCTCGCCAGA GCAACCGATGACTTCAGTTTGGCTAATAAAATTGGTCAAGGTGGCTTTGGAGCTGTTTACTACGCTGAGCTTAGAGGCGA GAAAGCTGCAATCAAGAAGATGGATATGCAAGCATCAAAAGAGTTCCTCGCGGAACTGAAAGTTCTTACTCGTGTTCATC ACTTGAATCTGGTGCGCTTGATTGGATATTGTGTCGAGGGTTCTTTGTTCTTAGTGTACGAGTTCATTGACAGTGGAAAC CTAAGTGAACATTTACGTGGAACAGAGAAGGAACCATTGCCGTGGTCCACAAGGGTGTACATTGCTCTCGATTCTGCAAG AGGTCTTGAATACATCCACGAGCACACAGTTCCTGTTTACATTCATCGTGATATCAAATCTGCAAACATTCTGGTAGACA GAAACTTCCGCGGAAAGGTTGCAGATTTTGGGTTAACAAAGCTAACTGAAGTTGGAAGTGGATCCTTGCAAACACGGGTT GTGGGTACATTTGGATACATGCCGCCTGAGTATGCTCAATGGGGTGACATCACCCCCAAGGTTGATGTCTATGCTTTCGG GGTTGTCCTGTATGAACTTATATCAGCAAAAGAAGCCGTGGTTAGGTCAAATGGTTCCAGTGTTGAATCAAGAGGACTCG TCTCTATGTTTGAAGAAGTTCTTAATCAACCCGATTCGAATGAAGATCTTCGCAAACTAGTCGACCCTAGGCTTGGAGAC AACTACCCTTTTGATTCAGTCCGCAAGTTAGCTCAACTTGCAAAAGCTTGCACGCACGAGAATCCCCAATTGAGACCTAC CATGAGGTCAATTGTGGTCGCATTAATGACACTTTCATCATCAACAGAGGATTGGGATGTTGGCTCCTTCTACGAAAACC ACGGTCTAGTGAATCTAATGTCAGGAAGGTAA |