| Microexon ID | Ps_NC_039359.1:100599479-100599483:- |
| Species | Papaver somniferum | Coordinates | NC_039359.1:100599479..100599483 |
| Microexon Cluster ID | MEP09 |
| Size | 5 |
| Phase | 2 |
| Pfam Domain Motif | SKG6 |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 19,34,5,50 |
| Microexon location in the Microexon-tag | 3 |
| Microexon-tag DNA Seq | GTDTWYATTCCDGSMMRAGATSAAAATGGAARYTATCSRCCCYTRMMAWCMAGCWCAGGAWTATCARGTGGAGYYATWGSTGGMATAKYTRTAGSAGYAGTAGYWGKR |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 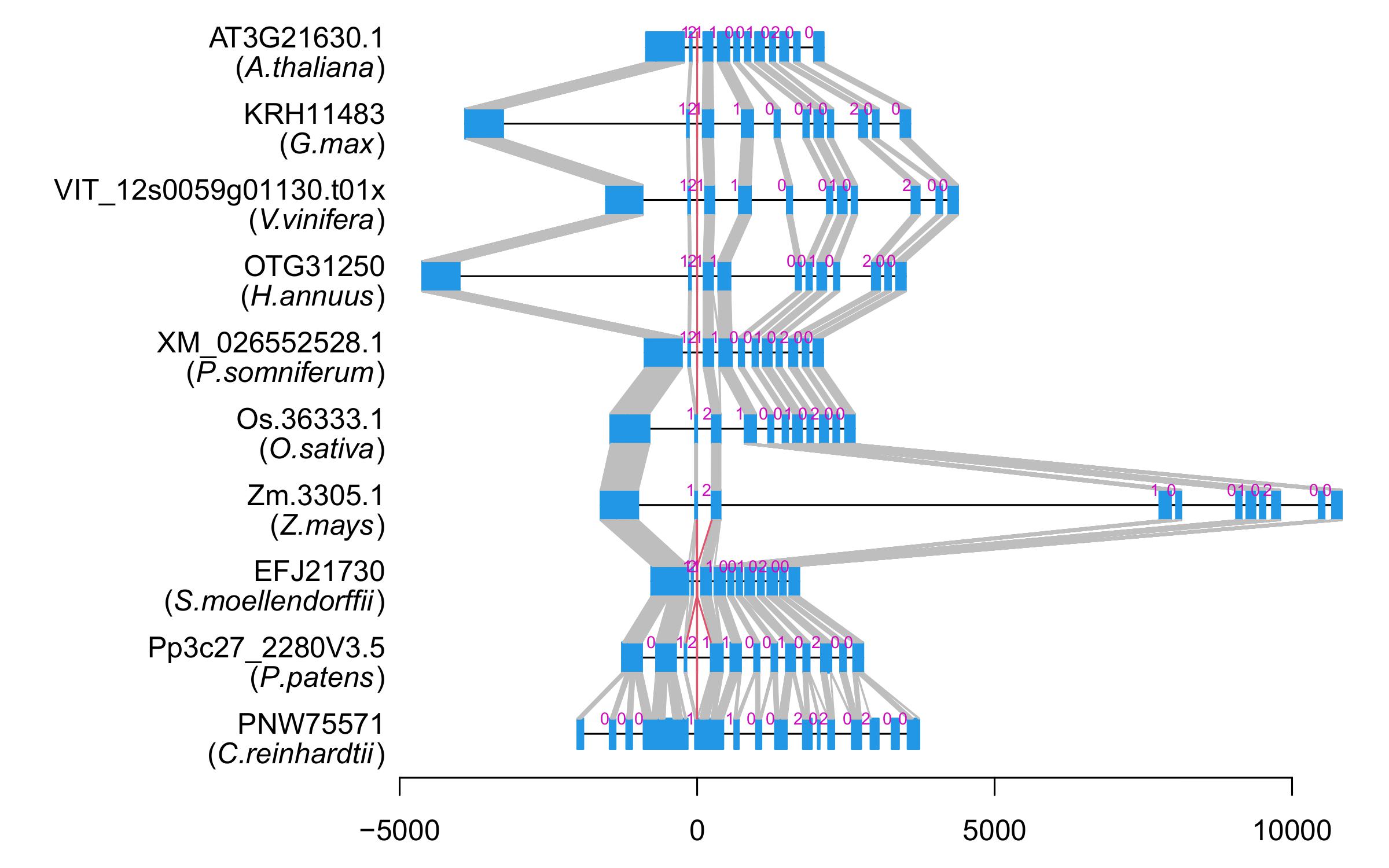 |
| Microexon DNA seq | CACAG |
| Microexon Amino Acid seq | STG |
| Microexon-tag DNA Seq | GTGTTTTTTCCTGGCAAAGATGAAACGGGAAACTACCCACGCTTGAAAGCGAGCACAGGACTTCCCACTGGAGCCATTGTTGGAATAGCAGTTGGAATAGTAGCTTTT |
| Microexon-tag Amino Acid Seq | VFFPGKDETGNYPRLKASTGLPTGAIVGIAVGIVAF |
| Microexon-tag spanning region | 100599338-100600993 |
| Microexon-tag prediction score | 0.8734 |
| Overlapped with the annotated transcript (%) | 97.3 |
| New Transcript ID | XM_026592397.1x |
| Reference Transcript ID | XM_026592397.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026592396.1 |
| Protein ID | XP_026448181.1 |
| Gene ID | LOC113348570 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XP_026448181.1 MVPIGRRRIIKSKGEIQFKLGFVFWGILFLFSSIGEVECQCRRGCDLALAYYDIWAGTNLTFTSKIFSTSDQEILKYNPQ VPNKDLILADDILNVPFRCDCIQEQRLGHNFTYTLQPGDTYEKIVKYYSNLTTKEDLSRDNPSYNPNNILDGSLVNVIVN CSCGDEKVDDYGLFVTYPLLPGDNLSSIAKKFNISSDLLRSYNPKTDFSSGKGVVFFPGKDETGNYPRLKASTAGGLPTG AIVGIAVGIVAFALLLAVCTYIVLSKKKKAKKALLLFETSEGSRGNFNKSVELASPTALASPRVTGITVDKSVEFTYEEL ARATDDFSLANKIGQGGFGAVYYAELRGEKAAIKKMDMQASKEFLAELKVLTRVHHLNLVRLIGYCVEGSLFLVYEFIDS GNLSEHLRGTEKEPLPWSTRVHIALDSARGLEYIHEHTVPVYIHRDIKSANILVDRNFRGKVADFGLTKLTEVGSGSLQT RVVGTFGYMPPEYAQWGDITPKVDVYAFGVVLYELISAKEAVVRSNGSSVESRGLVSMFEEVLNQPESNEDLRKLVDPRL GDNYPFDSIRKVAQLAKACTQENPQLRPSMRSIVVALMTLSSSTEDWDVGSFYENHGLVNLMSGR* |
| CDS seq | >XM_026592396.1 ATGGTACCTATAGGAAGAAGAAGAATAATAAAGAGTAAAGGGGAGATTCAGTTTAAACTAGGGTTTGTGTTTTGGGGGAT TTTGTTTTTGTTCTCGAGTATTGGAGAAGTAGAATGCCAGTGCAGAAGGGGATGTGATCTCGCTTTAGCTTATTATGATA TATGGGCAGGTACAAACCTTACATTCACTTCGAAAATTTTTAGTACTAGTGACCAGGAGATTCTCAAGTACAATCCTCAA GTTCCTAACAAAGATCTCATTTTAGCTGATGACATATTGAATGTCCCTTTTAGATGTGATTGCATTCAGGAACAACGATT AGGTCACAATTTTACTTATACTCTCCAACCTGGTGATACTTATGAAAAAATCGTTAAATATTACTCTAATCTTACTACCA AAGAAGACTTGAGTAGAGATAACCCCTCTTATAATCCTAACAATATACTTGATGGCTCCCTGGTAAATGTCATTGTAAAT TGCTCTTGTGGAGATGAAAAGGTGGATGATTATGGGTTGTTCGTGACTTATCCTTTACTTCCTGGTGATAACTTGAGTTC TATTGCTAAGAAATTCAATATCAGTTCTGATTTGCTACGGAGTTACAACCCGAAAACGGATTTCAGCAGCGGGAAGGGTG TGGTGTTTTTTCCTGGCAAAGATGAAACGGGAAACTACCCACGCTTGAAAGCGAGCACAGCAGGAGGACTTCCCACTGGA GCCATTGTTGGAATAGCAGTTGGAATAGTAGCTTTTGCACTATTATTGGCAGTTTGTACATATATTGTACTTTCTAAAAA GAAAAAGGCGAAGAAGGCATTATTGCTCTTCGAAACATCTGAAGGTTCTCGAGGCAATTTTAATAAATCAGTCGAATTAG CTTCTCCAACCGCCCTTGCTTCACCTAGGGTAACAGGTATCACGGTGGATAAATCAGTCGAGTTTACATATGAAGAGCTC GCCAGGGCGACCGATGACTTCAGTTTGGCTAATAAAATTGGTCAAGGTGGTTTTGGAGCTGTTTACTATGCTGAGCTTAG AGGCGAGAAAGCTGCAATCAAGAAGATGGATATGCAAGCATCAAAAGAGTTCCTCGCTGAACTGAAAGTTCTTACTCGGG TTCATCACTTGAATCTGGTGCGCTTGATTGGATATTGTGTCGAGGGTTCTTTGTTTTTAGTGTACGAGTTCATTGACAGT GGAAACCTAAGTGAACATTTACGTGGAACAGAGAAGGAACCATTGCCGTGGTCCACAAGGGTGCACATTGCTCTCGATTC TGCAAGAGGTCTTGAATACATCCACGAGCACACAGTTCCTGTTTACATTCATCGTGATATCAAATCTGCAAACATTCTGG TAGACAGGAACTTCCGCGGAAAGGTTGCAGATTTTGGGTTAACAAAGCTAACTGAAGTTGGAAGTGGATCCTTGCAAACA CGGGTTGTGGGTACATTTGGATACATGCCGCCTGAGTATGCTCAGTGGGGTGATATTACCCCCAAGGTTGATGTCTATGC TTTCGGGGTTGTCCTGTATGAACTTATATCAGCAAAAGAAGCTGTGGTTAGATCAAATGGTTCCAGTGTTGAATCAAGAG GACTCGTCTCTATGTTTGAAGAAGTTCTTAATCAGCCCGAGTCAAATGAAGATCTTCGCAAACTAGTCGACCCTAGGCTT GGAGACAACTACCCTTTTGATTCAATCCGTAAGGTGGCTCAACTTGCAAAAGCTTGCACGCAAGAGAACCCTCAATTGAG ACCTAGCATGAGGTCAATTGTGGTCGCATTAATGACACTTTCATCATCAACTGAAGATTGGGATGTTGGCTCCTTCTATG AAAACCACGGTCTAGTGAATCTAATGTCAGGAAGGTAA |
| Microexon DNA seq | CACAG |
| Microexon Amino Acid seq | STA |
| Microexon-tag DNA Seq | GTGTTTTTTCCTGGCAAAGATGAAACGGGAAACTACCCACGCTTGAAAGCGAGCACAGCAGGAGGACTTCCCACTGGAGCCATTGTTGGAATAGCAGTTGGAATAGTA |
| Microexon-tag Amino Acid seq | VFFPGKDETGNYPRLKASTAGGLPTGAIVGIAVGIV |
| Transcript ID | XM_026592396.1 |
| Gene ID | Ps.11643 |
| Gene Name | NA |
| Pfam domain motif | Unknown |
| Motif E-value | NA |
| Motif start | NA |
| Motif end | NA |
| Protein seq | >XM_026592396.1 MVPIGRRRIIKSKGEIQFKLGFVFWGILFLFSSIGEVECQCRRGCDLALAYYDIWAGTNLTFTSKIFSTSDQEILKYNPQ VPNKDLILADDILNVPFRCDCIQEQRLGHNFTYTLQPGDTYEKIVKYYSNLTTKEDLSRDNPSYNPNNILDGSLVNVIVN CSCGDEKVDDYGLFVTYPLLPGDNLSSIAKKFNISSDLLRSYNPKTDFSSGKGVVFFPGKDETGNYPRLKASTAGGLPTG AIVGIAVGIVAFALLLAVCTYIVLSKKKKAKKALLLFETSEGSRGNFNKSVELASPTALASPRVTGITVDKSVEFTYEEL ARATDDFSLANKIGQGGFGAVYYAELRGEKAAIKKMDMQASKEFLAELKVLTRVHHLNLVRLIGYCVEGSLFLVYEFIDS GNLSEHLRGTEKEPLPWSTRVHIALDSARGLEYIHEHTVPVYIHRDIKSANILVDRNFRGKVADFGLTKLTEVGSGSLQT RVVGTFGYMPPEYAQWGDITPKVDVYAFGVVLYELISAKEAVVRSNGSSVESRGLVSMFEEVLNQPESNEDLRKLVDPRL GDNYPFDSIRKVAQLAKACTQENPQLRPSMRSIVVALMTLSSSTEDWDVGSFYENHGLVNLMSGR* |
| CDS seq | >XM_026592396.1 ATGGTACCTATAGGAAGAAGAAGAATAATAAAGAGTAAAGGGGAGATTCAGTTTAAACTAGGGTTTGTGTTTTGGGGGAT TTTGTTTTTGTTCTCGAGTATTGGAGAAGTAGAATGCCAGTGCAGAAGGGGATGTGATCTCGCTTTAGCTTATTATGATA TATGGGCAGGTACAAACCTTACATTCACTTCGAAAATTTTTAGTACTAGTGACCAGGAGATTCTCAAGTACAATCCTCAA GTTCCTAACAAAGATCTCATTTTAGCTGATGACATATTGAATGTCCCTTTTAGATGTGATTGCATTCAGGAACAACGATT AGGTCACAATTTTACTTATACTCTCCAACCTGGTGATACTTATGAAAAAATCGTTAAATATTACTCTAATCTTACTACCA AAGAAGACTTGAGTAGAGATAACCCCTCTTATAATCCTAACAATATACTTGATGGCTCCCTGGTAAATGTCATTGTAAAT TGCTCTTGTGGAGATGAAAAGGTGGATGATTATGGGTTGTTCGTGACTTATCCTTTACTTCCTGGTGATAACTTGAGTTC TATTGCTAAGAAATTCAATATCAGTTCTGATTTGCTACGGAGTTACAACCCGAAAACGGATTTCAGCAGCGGGAAGGGTG TGGTGTTTTTTCCTGGCAAAGATGAAACGGGAAACTACCCACGCTTGAAAGCGAGCACAGCAGGAGGACTTCCCACTGGA GCCATTGTTGGAATAGCAGTTGGAATAGTAGCTTTTGCACTATTATTGGCAGTTTGTACATATATTGTACTTTCTAAAAA GAAAAAGGCGAAGAAGGCATTATTGCTCTTCGAAACATCTGAAGGTTCTCGAGGCAATTTTAATAAATCAGTCGAATTAG CTTCTCCAACCGCCCTTGCTTCACCTAGGGTAACAGGTATCACGGTGGATAAATCAGTCGAGTTTACATATGAAGAGCTC GCCAGGGCGACCGATGACTTCAGTTTGGCTAATAAAATTGGTCAAGGTGGTTTTGGAGCTGTTTACTATGCTGAGCTTAG AGGCGAGAAAGCTGCAATCAAGAAGATGGATATGCAAGCATCAAAAGAGTTCCTCGCTGAACTGAAAGTTCTTACTCGGG TTCATCACTTGAATCTGGTGCGCTTGATTGGATATTGTGTCGAGGGTTCTTTGTTTTTAGTGTACGAGTTCATTGACAGT GGAAACCTAAGTGAACATTTACGTGGAACAGAGAAGGAACCATTGCCGTGGTCCACAAGGGTGCACATTGCTCTCGATTC TGCAAGAGGTCTTGAATACATCCACGAGCACACAGTTCCTGTTTACATTCATCGTGATATCAAATCTGCAAACATTCTGG TAGACAGGAACTTCCGCGGAAAGGTTGCAGATTTTGGGTTAACAAAGCTAACTGAAGTTGGAAGTGGATCCTTGCAAACA CGGGTTGTGGGTACATTTGGATACATGCCGCCTGAGTATGCTCAGTGGGGTGATATTACCCCCAAGGTTGATGTCTATGC TTTCGGGGTTGTCCTGTATGAACTTATATCAGCAAAAGAAGCTGTGGTTAGATCAAATGGTTCCAGTGTTGAATCAAGAG GACTCGTCTCTATGTTTGAAGAAGTTCTTAATCAGCCCGAGTCAAATGAAGATCTTCGCAAACTAGTCGACCCTAGGCTT GGAGACAACTACCCTTTTGATTCAATCCGTAAGGTGGCTCAACTTGCAAAAGCTTGCACGCAAGAGAACCCTCAATTGAG ACCTAGCATGAGGTCAATTGTGGTCGCATTAATGACACTTTCATCATCAACTGAAGATTGGGATGTTGGCTCCTTCTATG AAAACCACGGTCTAGTGAATCTAATGTCAGGAAGGTAA |