| Microexon ID | Ps_NC_039358.1:145506860-145506864:- |
| Species | Papaver somniferum | Coordinates | NC_039358.1:145506860..145506864 |
| Microexon Cluster ID | MEP09 |
| Size | 5 |
| Phase | 2 |
| Pfam Domain Motif | SKG6 |
| Structure of Microexon-tag (flanking exon, microexon, flanking exon sizes) | 19,34,5,50 |
| Microexon location in the Microexon-tag | 3 |
| Microexon-tag DNA Seq | GTDTWYATTCCDGSMMRAGATSAAAATGGAARYTATCSRCCCYTRMMAWCMAGCWCAGGAWTATCARGTGGAGYYATWGSTGGMATAKYTRTAGSAGYAGTAGYWGKR |
| Logo of Microexon-tag DNA Seq | |
| Alignment of exons | 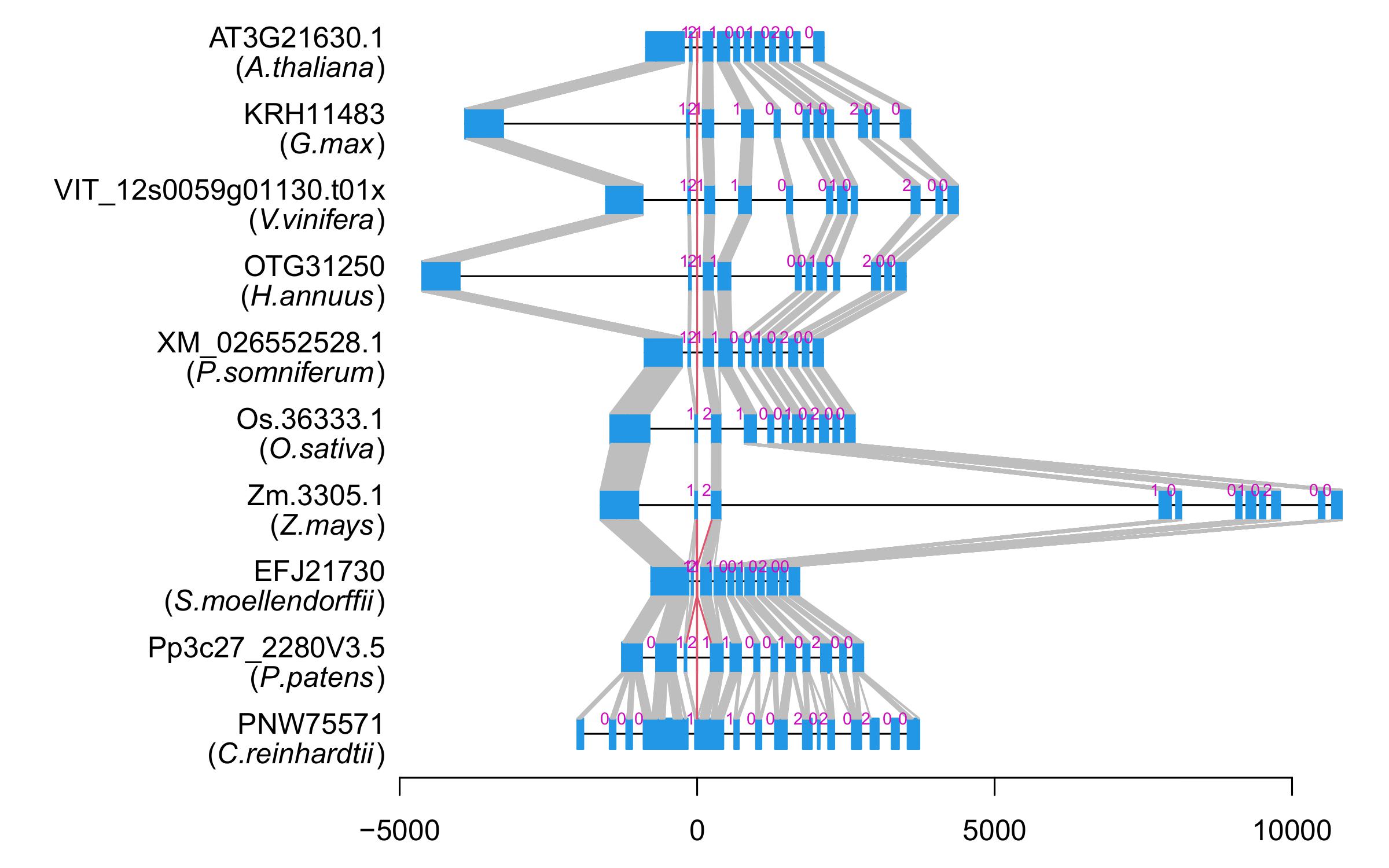 |
| Microexon DNA seq | CAGAG |
| Microexon Amino Acid seq | SRG |
| Microexon-tag DNA Seq | GTGTTCGTACCTGCAAAAGATCAAACAGGGGATTTTCCACGCCTGAAGTCGAGCAGAGGAATCTCCAGAGGCGCAATTGCAGGCACGTCAGTTGCAGTAGTAGCTGTT |
| Microexon-tag Amino Acid Seq | VFVPAKDQTGDFPRLKSSRGISRGAIAGTSVAVVAV |
| Microexon-tag spanning region | 145506705-145507136 |
| Microexon-tag prediction score | 0.8821 |
| Overlapped with the annotated transcript (%) | 100 |
| New Transcript ID | XM_026552528.1x |
| Reference Transcript ID | XM_026552528.1 |
| Gene ID | NA |
| Gene Name | NA |
| Transcript ID | XM_026552528.1 |
| Protein ID | XP_026408313.1 |
| Gene ID | LOC113303479 |
| Gene Name | NA |
| Pfam domain motif | VSP |
| Motif E-value | 0.078 |
| Motif start | 221 |
| Motif end | 250 |
| Protein seq | >XP_026408313.1 MFFCSSKRRKLELGIVILFFLCFRVKAKCSPGCDLAMASYFLVEGSNLTYISDIFGKNIPEILAYDPDVKDQNTIQFGTR VNVPFSCDCLNDDFLGHTFDYTTQTGDTYKIIAQKIFAELTTADWIQRINHLNPNLVLPYTSINVTVNCSCGDESVSKDY GLFMTYPLHPEDNLSFVASESGVPKKLLQMYNPGMDFSQGSGLVFVPAKDQTGDFPRLKSSRGISRGAIAGTSVAVVAVA VLLMAVCSYFGLSRRKKVNRLSLLPKLCTDSPTPSGLVGMVRSTPLGKHTESIGHVGGASPGLSGISMDKSVEFSYEELA KATNNFSSSKLIGQGGFGTVYYGMLRGEKAAIKKMDMQASKEFLAELNVLTHVHHLNLVHLIGYCVEGSLFLVYEYIENG NLSEHLHGSGWESLPWTTRVQIALDSARGLEYIHEHTVPVYIHRDIKSANILIDRNFHGKVADFGLTKLTEVGNSSLQTR LVGTFGYISPEYAQYGDISPKVDVYAFGVVIFELISAKEAVVKANGCIAESRGLVDLFEDVLNQIDPKGDLANLVDPKLG KDYPLDSVLKMAQLAKACAQENPQLRPSMRSIVVALTTLSSSSDNWDVGSFYENQALVNLVTGR* |
| CDS seq | >XM_026552528.1 ATGTTTTTCTGTTCAAGTAAAAGAAGAAAACTAGAGTTGGGTATAGTGATTCTTTTCTTCTTATGTTTTCGAGTTAAAGC TAAGTGTAGTCCAGGTTGTGATCTTGCTATGGCATCTTATTTCTTAGTAGAAGGATCAAACTTGACTTATATCAGTGATA TATTCGGCAAAAACATTCCGGAAATCCTTGCTTATGATCCGGATGTTAAAGATCAAAACACTATTCAGTTTGGAACAAGA GTGAACGTTCCATTCTCATGTGATTGTCTTAATGATGATTTTTTAGGACATACTTTCGATTATACAACGCAAACTGGAGA TACATATAAGATAATTGCTCAAAAGATTTTCGCAGAACTCACAACGGCAGATTGGATACAAAGAATAAATCATTTGAATC CTAATTTAGTGCTACCTTATACATCCATCAATGTAACAGTGAATTGCTCGTGTGGTGATGAAAGTGTATCAAAGGATTAT GGGTTATTTATGACTTACCCACTTCATCCTGAAGATAATTTATCTTTCGTAGCGTCTGAATCTGGTGTACCCAAAAAATT GCTACAGATGTATAACCCAGGAATGGATTTCAGCCAAGGGAGTGGATTGGTGTTCGTACCTGCAAAAGATCAAACAGGGG ATTTTCCACGCCTGAAGTCGAGCAGAGGAATCTCCAGAGGCGCAATTGCAGGCACGTCAGTTGCAGTAGTAGCTGTTGCA GTGTTATTAATGGCAGTCTGTTCATACTTTGGGCTCTCCAGAAGGAAGAAGGTCAACAGGTTGTCATTACTTCCAAAATT GTGCACAGATTCCCCTACCCCATCTGGTCTAGTAGGTATGGTAAGAAGTACTCCCTTGGGTAAACATACGGAATCAATCG GGCATGTTGGTGGAGCTTCCCCAGGACTTAGCGGTATCTCTATGGACAAATCTGTGGAATTCTCATATGAAGAACTTGCT AAGGCGACAAATAATTTTAGTAGTAGCAAGTTAATTGGTCAAGGAGGGTTTGGAACAGTTTACTATGGTATGCTAAGAGG AGAGAAAGCTGCAATCAAGAAGATGGATATGCAAGCATCGAAAGAGTTTCTTGCTGAACTGAATGTTCTAACACATGTTC ATCACTTGAACCTGGTACACTTAATTGGATATTGTGTTGAAGGTTCTTTGTTCCTTGTTTACGAGTATATTGAGAACGGG AACTTAAGCGAACACTTACATGGCTCGGGGTGGGAATCGCTACCATGGACCACAAGGGTGCAAATTGCACTTGATTCAGC AAGAGGTCTTGAATATATCCATGAACATACAGTTCCAGTGTACATCCATCGTGATATTAAATCAGCAAACATTTTGATAG ACAGAAACTTCCATGGAAAGGTAGCTGATTTTGGTTTAACTAAACTGACTGAAGTCGGAAATTCATCCTTGCAAACACGT CTAGTTGGTACATTCGGATATATTTCACCCGAGTATGCTCAGTATGGTGATATATCCCCTAAGGTTGATGTATATGCTTT TGGAGTAGTTATTTTTGAACTTATTTCCGCGAAGGAAGCTGTAGTTAAAGCAAATGGATGTATTGCTGAATCAAGGGGAC TTGTTGATTTGTTTGAGGATGTTCTTAATCAAATTGACCCGAAAGGTGATCTTGCCAATCTAGTCGACCCTAAACTTGGG AAGGATTATCCACTTGATTCAGTTCTTAAGATGGCACAGCTTGCCAAAGCTTGTGCACAAGAGAATCCACAACTAAGACC AAGTATGCGATCTATAGTGGTTGCATTAACCACACTCTCATCGTCATCTGACAATTGGGATGTCGGATCCTTCTACGAAA ATCAAGCTCTAGTTAACCTAGTGACAGGAAGGTAG |
| Microexon DNA seq | CAGAG |
| Microexon Amino Acid seq | SRG |
| Microexon-tag DNA Seq | GTGTTCGTACCTGCAAAAGATCAAACAGGGGATTTTCCACGCCTGAAGTCGAGCAGAGGAATCTCCAGAGGCGCAATTGCAGGCACGTCAGTTGCAGTAGTAGCTGTT |
| Microexon-tag Amino Acid seq | VFVPAKDQTGDFPRLKSSRGISRGAIAGTSVAVVAV |
| Transcript ID | Ps.4534.1 |
| Gene ID | Ps.4534 |
| Gene Name | NA |
| Pfam domain motif | VSP |
| Motif E-value | 0.078 |
| Motif start | 221 |
| Motif end | 250 |
| Protein seq | >Ps.4534.1 MFFCSSKRRKLELGIVILFFLCFRVKAKCSPGCDLAMASYFLVEGSNLTYISDIFGKNIPEILAYDPDVKDQNTIQFGTR VNVPFSCDCLNDDFLGHTFDYTTQTGDTYKIIAQKIFAELTTADWIQRINHLNPNLVLPYTSINVTVNCSCGDESVSKDY GLFMTYPLHPEDNLSFVASESGVPKKLLQMYNPGMDFSQGSGLVFVPAKDQTGDFPRLKSSRGISRGAIAGTSVAVVAVA VLLMAVCSYFGLSRRKKVNRLSLLPKLCTDSPTPSGLGMVRSTPLGKHTESIGHVGGASPGLSGISMDKSVEFSYEELAK ATNNFSSSKLIGQGGFGTVYYGMLRGEKAAIKKMDMQASKEFLAELNVLTHVHHLNLVHLIGYCVEGSLFLVYEYIENGN LSEHLHGSGWESLPWTTRVQIALDSARGLEYIHEHTVPVYIHRDIKSANILIDRNFHGKVADFGLTKLTEVGNSSLQTRL VGTFGYISPEYAQYGDISPKVDVYAFGVVIFELISAKEAVVKANGCIAESRGLVDLFEDVLNQIDPKGDLANLVDPKLGK DYPLDSVLKMAQLAKACAQENPQLRPSMRSIVVALTTLSSSSDNWDVGSFYENQALVNLVTGR* |
| CDS seq | >Ps.4534.1 ATGTTTTTCTGTTCAAGTAAAAGAAGAAAACTAGAGTTGGGTATAGTGATTCTTTTCTTCTTATGTTTTCGAGTTAAAGC TAAGTGTAGTCCAGGTTGTGATCTTGCTATGGCATCTTATTTCTTAGTAGAAGGATCAAACTTGACTTATATCAGTGATA TATTCGGCAAAAACATTCCGGAAATCCTTGCTTATGATCCGGATGTTAAAGATCAAAACACTATTCAGTTTGGAACAAGA GTGAACGTTCCATTCTCATGTGATTGTCTTAATGATGATTTTTTAGGACATACTTTCGATTATACAACGCAAACTGGAGA TACATATAAGATAATTGCTCAAAAGATTTTCGCAGAACTCACAACGGCAGATTGGATACAAAGAATAAATCATTTGAATC CTAATTTAGTGCTACCTTATACATCCATCAATGTAACAGTGAATTGCTCGTGTGGTGATGAAAGTGTATCAAAGGATTAT GGGTTATTTATGACTTACCCACTTCATCCTGAAGATAATTTATCTTTCGTAGCGTCTGAATCTGGTGTACCCAAAAAATT GCTACAGATGTATAACCCAGGAATGGATTTCAGCCAAGGGAGTGGATTGGTGTTCGTACCTGCAAAAGATCAAACAGGGG ATTTTCCACGCCTGAAGTCGAGCAGAGGAATCTCCAGAGGCGCAATTGCAGGCACGTCAGTTGCAGTAGTAGCTGTTGCA GTGTTATTAATGGCAGTCTGTTCATACTTTGGGCTCTCCAGAAGGAAGAAGGTCAACAGGTTGTCATTACTTCCAAAATT GTGCACAGATTCCCCTACCCCATCTGGTCTAGGTATGGTAAGAAGTACTCCCTTGGGTAAACATACGGAATCAATCGGGC ATGTTGGTGGAGCTTCCCCAGGACTTAGCGGTATCTCTATGGACAAATCTGTGGAATTCTCATATGAAGAACTTGCTAAG GCGACAAATAATTTTAGTAGTAGCAAGTTAATTGGTCAAGGAGGGTTTGGAACAGTTTACTATGGTATGCTAAGAGGAGA GAAAGCTGCAATCAAGAAGATGGATATGCAAGCATCGAAAGAGTTTCTTGCTGAACTGAATGTTCTAACACATGTTCATC ACTTGAACCTGGTACACTTAATTGGATATTGTGTTGAAGGTTCTTTGTTCCTTGTTTACGAGTATATTGAGAACGGGAAC TTAAGCGAACACTTACATGGCTCGGGGTGGGAATCGCTACCATGGACCACAAGGGTGCAAATTGCACTTGATTCAGCAAG AGGTCTTGAATATATCCATGAACATACAGTTCCAGTGTACATCCATCGTGATATTAAATCAGCAAACATTTTGATAGACA GAAACTTCCATGGAAAGGTAGCTGATTTTGGTTTAACTAAACTGACTGAAGTCGGAAATTCATCCTTGCAAACACGTCTA GTTGGTACATTCGGATATATTTCACCCGAGTATGCTCAGTATGGTGATATATCCCCTAAGGTTGATGTATATGCTTTTGG AGTAGTTATTTTTGAACTTATTTCCGCGAAGGAAGCTGTAGTTAAAGCAAATGGATGTATTGCTGAATCAAGGGGACTTG TTGATTTGTTTGAGGATGTTCTTAATCAAATTGACCCGAAAGGTGATCTTGCCAATCTAGTCGACCCTAAACTTGGGAAG GATTATCCACTTGATTCAGTTCTTAAGATGGCACAGCTTGCCAAAGCTTGTGCACAAGAGAATCCACAACTAAGACCAAG TATGCGATCTATAGTGGTTGCATTAACCACACTCTCATCGTCATCTGACAATTGGGATGTCGGATCCTTCTACGAAAATC AAGCTCTAGTTAACCTAGTGACAGGAAGGTAG |